
freshidea - stock.adobe.com
How to achieve resilience – the modern uptime trinity
IT leaders can take responsibility for ensuring their organisations are resilient during times of crisis. There are no quick fixes, but if you think it is expensive to ensure resilience in your IT systems, try frequent failure instead

Some years ago, the computer system’s key focus was on performance and many articles, products and efforts were focused on this area. A few years later, the emphasis moved to high availability (HA) of hardware and software and all the other machinations they entail. Today the focus is on (cyber) security.
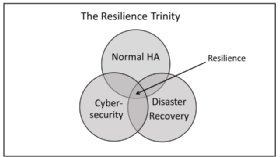
These discrete environments’ boundaries have now blurred under the heading of resilience, the main components of which are:
- Normal HA design, redundancy, and so on, plus normal recovery from non-critical outages. This applies to hardware and software. Human factors (“fat finger” syndrome and deliberate malice) are extremely common causes of failure.
- Cyber security breaches of all kinds. No hard system failures here, but leaving a compromised system online is dangerous. This area has spawned the phrase “cyber security resilience”.
- Disaster recovery (DR), a discipline not in evidence, for example, in May 2017 when WannaCry struck the UK NHS.
You can’t choose which of these three bases you cover – it’s all or nothing.
In boxing, resilience in simple terms means the ability to recover from a punch (normal recovery) or knockdown (disaster recovery). However, it has connotations beyond just that, inasmuch as the boxer must prepare himself via tough training, a fight plan and coaching to avoid the knockdown and, should it happen, he should be fit enough to recover and rejoin the fray quickly enough to beat the 10-second count – financial penalties in our world.
The Financial Conduct Authority defines a resilient financial system as one that can absorb shocks, rather than contribute to them. The speed and effectiveness of communications with the people most affected, including customers, is an important part of any firm’s overall response to an operational disruption.
“The financial sector needs an approach to operational risk management that includes preventative measures and the capabilities – in terms of people, processes and organisational culture – to adapt and recover when things go wrong,” it says.
Gartner defines resilience in a broader way, capable of different interpretations, thus: “Operational resilience is a set of techniques that allow people, processes and informational systems to adapt to changing patterns. It is the ability to alter operations in the face of changing business conditions.” In boxing parlance, this would mean a change of fight tactics.
To summarise these views, the key job in hand is to keep your operations running with the same quality of delivery in the manner the customers want. You interpret this principle according to your business and clients.
When is an outage not an outage?
This is a valid question to ask if you understand service-level agreements (SLAs). SLAs specify what properties the service should offer apart from a “system availability clause”. These requirements usually include response times, hours of service schedule (not the same as availability) at various points in the calendar, for example, high volume activity periods such as major holidays, product promotions, year-end processing, and so on.
Many people think of a system outage as complete failure – a knockout, using our earlier analogy. In reality, a system not performing as expected and defined in an SLA will often lead users to consider the system as “down” because it is not doing what it is supposed to do and impedes their work.
This leads to the concept of a logical outage (in boxing, a forced standing count) where, physically, everything is in working order but the service provided is not acceptable for some reason. These reasons vary, depending on what stage the applications have reached:
- At initiation of the new service, the user interface (UI) is totally unfriendly and foreign to the application users. This if often the result of a UI designed without user input or knowledge of the business process behind it.
- At initiation, it does not completely map the function of the business function it deals with onto the delivered application, again often the result of user non-involvement.
- During normal running, the performance degrades for some reason, resulting in effects such as loss or productivity through to being totally unusable. Loss of performance can have a disastrous effect on web-based sales systems, for example.
Studies have shown that people using a website to order goods have a mental, often unquantified expectation of interactive response times which, if exceeded, results in them leaving the site. In the worst case, it can mean the buyer obtaining the goods from a competitor’s site and, worse still, never returning.
The unconscious response time expectation of buyers varies from a few hundred milliseconds to a few seconds, depending on the study involved. Incidentally, poor design of the user interface is another logical outage, but this and other aspects of outages are too detailed (and gory) to cover here.
Areas of resilience
Resilience, in bare terms, means the ability to recover from a knockdown, to use the boxing analogy once more. But it has connotations beyond just that, inasmuch as the boxer must prepare himself by tough training and coaching to avoid the knockdown and, should it happen, he should be fit enough to recover, get to his feet and continue fighting. The IT scenario this involves, among other things:
- “Fitness” through rigorous system design, implementation and monitoring, plus staff training in risk and crisis management.
- Normal backup and recovery after outages or data loss not due to criminal activities or severe system damage.
- Cyber security tools and techniques to counter attacks by malware, both external and internal. In my view, the current internet architecture, intrinsically open, is unsuitable to stem the tide of malware, particularly in the rapidly growing areas of mobile computing and internet of things (IoT) devices. IoT devices are expected to number 22 billion by 2021, across many industries, and unfortunately, security was not the primary feature in their design and manufacture and still isn’t, in many cases. Security is notoriously difficult to retrofit.
- DR when the primary system is totally unable to function for whatever reason and workload must be located and accessed from facilities – system and accommodation (often forgotten) – elsewhere. The location of a secondary DR site is important because some natural disasters affect large areas and an on-site or near-site secondary system can be rendered useless by the same disaster that struck the primary. On the other hand, cyber security attacks are geography neutral. These factors involve experience, planning and common sense.
- Spanning the resilience ecosphere are the monitoring, management and analysis methods to turn data into information to support the resilience aims of a company and improve it. If you can’t measure it, you can’t manage it.
Figure 1 (below) is a simple representation of resilience and the main thing to remember is that it is not a pick-and choose-exercise – you have to do them all to close the loop between the three contributing areas of resilience planning and recovery activities.
In view of the series of failures of financial and other services’ computer systems over the past few years, it is evident that in performance and HA, the lessons learned have largely been forgotten.
Cyber security is a new threat which the business world has to be aware of and take action on, not following the Mark Twain dictum: “Everybody is talking about the weather, nobody is doing anything about it.”
The key factor is covering all the “resilience” bases at a level matching the business’ needs. It is not a “choose any n from M” menu type of choice – it is all or nothing for optimum resilience.
What needs to be resilient?
A good question, to which the answer is probably anything that can stop or hinder a service. Here are several examples:
- Server and peripheral devices, especially storage devices.*
- Software – application and system.*
- Physical facilities failure – rooms, power supplies, sprinklers, etc.
- Networks and its peripherals – mobile device, IoT, etc.*
- People – numbers, skills, finger trouble, commitment.*
- Backup and recovery methods and systems (resilience management).*
- DR facilities (complete primary site failure).*
- Security facilities across the entities above marked * and including encryption at rest and in flight.
Lusser’s Law shows that entities operating in parallel (unison) give higher availability than those in series. See Wikipedia for the simple mathematics of this.
To stretch a point a little, I think resilience will be enhanced by recognising the “trinity” aspect of the factors affecting resilience and should operate as such, even in virtual team mode across the individual teams involved. This needs some thought, but a “war room” mentality might be appropriate.
Tools and methods
There are scores of methods and technologies to “harden” areas where vulnerabilities lurk before, during and beyond the three areas shown in Figure 1. Some resilience topics are listed below:
HA design
There are many ways of “hardening” systems to make them more resilient, but they are too detailed to cover here. The other parts of the triumvirate – disaster recovery and cyber security – depend on an organisation’s requirements and is essentially a “knitting exercise”.
Cyber security
There are a great number of ways to protect your data, an attack on which can cause an outage or make the owner take it down for safety. These methods are too numerous to outline here, but I’ll mention one – encryption – which, according to IBM, represents a key safety area. Only 2.8% of attacks are successful against systems with encrypted data.
Disaster recovery
Again, a large area to cover, but once more a key message. How far you go in configuring a disaster recovery site depends on how many applications are important enough to require elaborate systems. This is decided by a failure business impact analysis between business and IT, part of business continuity planning.
Like any major activity, the results of any resilience plan need review and corrective action to be taken. This requires an environment where parameters relating to resilience are measurable, recorded, reviewed and acted upon. It is not simply a monitoring activity because monitoring is passive; management is active and proactive.
Management = Monitoring + Analysis + Review + Action
Why resilience is IT’s responsibility
I find that vendors and some organisations often split the components of resilience into different departments or functions, especially cyber security or HA. Unfortunately, systems cannot live by any of these alone, but only in synergistic development and operation.
They need to be considered together, especially as there will be areas where changes to one of these entities can adversely affect another, thereby mandating change management as a corollary discipline. This should be in place anyway in a well-run site.
Resilience, like a bespoke garment, is a personal thing and it is unlikely that the vendor of tools will know more than you do about your business and its vulnerabilities. If you think tools will do all the heavy lifting for you, you are deluding yourself.
NIST cyber resilience definition
Cyber resilience is defined as “the ability to anticipate, withstand, recover from and adapt to adverse conditions, stresses, attacks or compromises on systems that use or are enabled by cyber resources”.
Systems with this property are characterised by having security measures or safeguards “built in” as a foundational part of the architecture and design and, moreover, can withstand cyber attacks, faults and failures and continue to operate even in a degraded or debilitated state, carrying out mission-essential functions and ensuring that the other aspects of trustworthiness (in particular, safety and information security) are preserved.
Your impression of resilience may now be: “That is a big job.” Yes, it is, but a big problem usually involves hard work to solve or at least mitigate it. If you think it is expensive to ensure resilience, try frequent failure instead and consider the penalties for failure levied by regulatory bodies, particularly in finance.
In computer security, a vulnerability is a weakness that can be exploited by a threat actor, such as an attacker, to perform unauthorised actions within a computer system. However, in our quest for resilience, of which vulnerability is its antithesis, we need to expand this definition to cover the other two elements of resilience.
In the case of HA, the vulnerabilities include the inherent failure rate of the hardware and software components, their configuration (series if parallel), the environment and many other factors, including human error and vindictiveness.
In the DR world, the vulnerabilities in primary systems again are many and, in theory, apply to the DR site as well, but the probability of both sites suffering catastrophic outage simultaneously are vanishingly small, assuming the DR location and other factors are chosen well.
For example, if you chose to site both of them on a geological fault line, you are asking for trouble, similarly in flood or hurricane areas.
Ensuring optimum resilience of systems is not a “one solution fits all” situation, but a rather time-consuming search for vulnerabilities that can affect your systems(s) in each area, nor is it “let’s give this a try and see how it goes” – the “burn your boats” technique if it fails. No, it needs a component failure impact analysis where each impact is traced to which business aspects are compromised or fail if a particular component ceases to function.
If you think IT suppliers can sell you products that give the answer, you are deluding yourself. As Sir Winston Churchill said, in paraphrase: “All I can offer is blood, sweat and tears.”
Terry Critchley is the author of three books – High-availability IT services, High-performance IT services and Making it in IT. He can be contacted at [email protected].







