Las cinco “V” de big data
¿Cuáles son las 5 V de big data?
Las 5 V del big data –velocidad, volumen, valor, variedad y veracidad– son sus cinco características principales e innatas. Conocer las 5 V permite a los científicos de datos obtener más valor de sus datos y, al mismo tiempo, permite que sus organizaciones se centren más en el cliente.
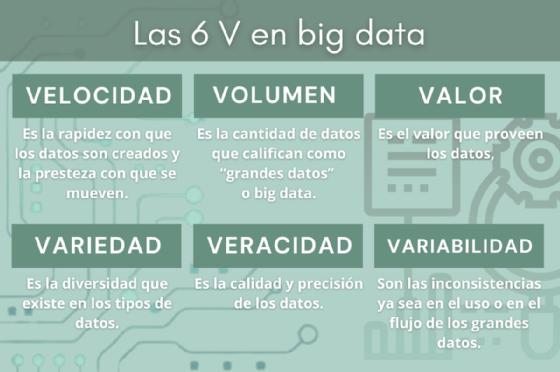
A principios de este siglo, se hablaba de big data en términos de tres V: volumen, velocidad y variedad. Con el tiempo, se agregaron dos V más, valor y veracidad, para ayudar a los científicos de datos a articular y comunicar de manera más efectiva las características importantes de big data. En algunos casos, existe incluso un sexto término V para big data: variabilidad.
¿Qué son los grandes datos?
Big data es una combinación de datos no estructurados, semiestructurados o estructurados recopilados por las organizaciones. Estos conjuntos de datos se pueden extraer para obtener información y utilizarlos en proyectos de aprendizaje automático, modelos predictivos y otras aplicaciones de análisis avanzado.
Los macrodatos se pueden utilizar para mejorar las operaciones, proporcionar un mejor servicio al cliente y crear campañas de marketing personalizadas, todo lo cual puede aumentar el valor de una organización. Por ejemplo, el análisis de big data puede proporcionar a las empresas información valiosa sobre sus clientes, que luego se puede utilizar para perfeccionar las técnicas de marketing y aumentar la participación del cliente y las tasas de conversión.
Los macrodatos se pueden utilizar en la atención sanitaria para identificar factores de riesgo de enfermedades, o los médicos pueden utilizarlos para ayudar a diagnosticar enfermedades en los pacientes. Las industrias energéticas pueden utilizar big data para rastrear redes eléctricas, implementar gestión de riesgos o realizar análisis de datos de mercado en tiempo real.
Las organizaciones que utilizan big data tienen una ventaja competitiva potencial sobre aquellas que no lo hacen porque pueden tomar decisiones comerciales más rápidas e informadas, basadas en los datos proporcionados.
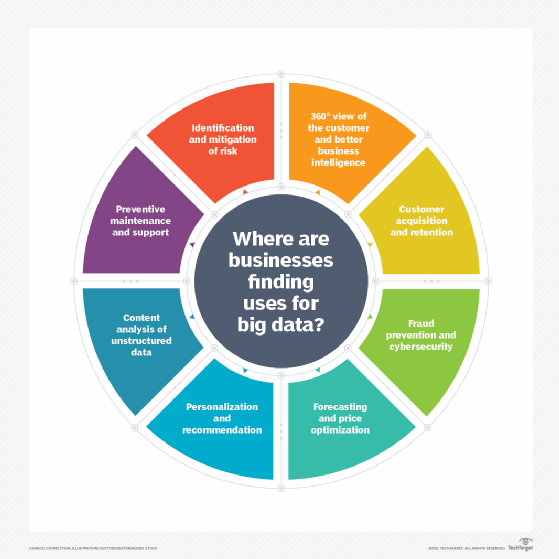
¿Cuáles son las 5 V?
Las 5 V se definen de la siguiente manera:
- La velocidad es la velocidad a la que se crean los datos y la velocidad a la que se mueven.
- El volumen es la cantidad de datos que califican como big data.
- El valor es el valor que proporcionan los datos.
- La variedad es la diversidad que existe en los tipos de datos.
- La veracidad es la calidad y exactitud de los datos.
Velocidad
La velocidad se refiere a la rapidez con la que se generan los datos y a qué velocidad se mueven. Este es un aspecto importante para las organizaciones que necesitan que sus datos fluyan rápidamente, de modo que estén disponibles en el momento adecuado para tomar las mejores decisiones comerciales posibles.
Una organización que utiliza big data tendrá un flujo grande y continuo de datos que se creará y enviará a su destino final. Los datos podrían provenir de fuentes como máquinas, redes, teléfonos inteligentes o redes sociales. La velocidad se aplica a la velocidad a la que llega esta información –por ejemplo, cuántas publicaciones en las redes sociales se ingieren por día– así como a la velocidad a la que debe digerirse y analizarse, a menudo rápidamente y a veces casi en tiempo real.
Por ejemplo, en el sector sanitario, muchos dispositivos médicos actuales están diseñados para monitorear a los pacientes y recopilar datos. Desde equipos médicos hospitalarios, hasta dispositivos portátiles, los datos recopilados deben enviarse a su destino y analizarse rápidamente.
En algunos casos, sin embargo, podría ser mejor tener un conjunto limitado de datos recopilados que recopilar más datos de los que una organización puede manejar porque esto puede conducir a velocidades de datos más lentas.
Volumen
El volumen se refiere a la cantidad de datos que existen. El volumen es como la base del big data, ya que es el tamaño inicial y la cantidad de datos que se recopilan. Si el volumen de datos es lo suficientemente grande, se puede considerar big data. Sin embargo, lo que se considera big data es relativo, y cambiará dependiendo de la potencia informática disponible en el mercado.
Por ejemplo, una empresa que opera cientos de tiendas en varios estados genera millones de transacciones por día. Esto se considera big data, y el número promedio de transacciones totales por día en las tiendas representa su volumen.
Valor
El valor se refiere a los beneficios que big data puede proporcionar, y se relaciona directamente con lo que las organizaciones pueden hacer con los datos recopilados. Ser capaz de extraer valor de los big data es un requisito, ya que el valor de los grandes datos aumenta significativamente dependiendo de los conocimientos que se pueden obtener de ellos.
Las organizaciones pueden utilizar herramientas de big data para recopilar y analizar los datos, pero la forma en que obtienen valor de esos datos debe ser exclusiva de ellas. Herramientas como Apache Hadoop pueden ayudar a las organizaciones a almacenar, limpiar y procesar rápidamente esta enorme cantidad de datos.
Un gran ejemplo del valor del big data se puede encontrar en la recopilación de datos de clientes individuales. Cuando una empresa puede perfilar a sus clientes, puede personalizar su experiencia en marketing y ventas, mejorando la eficiencia de los contactos y obteniendo una mayor satisfacción del cliente.
Variedad
La variedad se refiere a la diversidad de tipos de datos. Una organización puede obtener datos de varias fuentes de datos, cuyo valor puede variar. Los datos también pueden provenir de fuentes dentro y fuera de una empresa. El desafío en variedad se refiere a la estandarización y distribución de todos los datos que se recopilan.
Como se señaló anteriormente, los datos recopilados pueden ser no estructurados, semiestructurados o estructurados. Los datos no estructurados son datos que no están organizados y vienen en diferentes archivos o formatos. Normalmente, los datos no estructurados no son adecuados para una base de datos relacional convencional porque no encajan en los modelos de datos convencionales. Los datos semiestructurados son datos que no se han organizado en un repositorio especializado, pero que tienen información asociada, como metadatos. Esto hace que sea más fácil de procesar que los datos no estructurados. Mientras tanto, los datos estructurados son datos que se han organizado en un repositorio formateado. Esto significa que los datos se vuelven más accesibles para un procesamiento y análisis de datos efectivos.
Los datos crudos (raw data) también se consideran un tipo de datos. Si bien los datos sin procesar pueden clasificarse en otras categorías –estructurados, semiestructurados o no estructurados– se consideran crudos si no han recibido ningún procesamiento. En la mayoría de los casos, el término crudo se aplica a datos importados de otras organizaciones o enviados o ingresados por los usuarios. Los datos de las redes sociales suelen entrar en esta categoría.
Un ejemplo más específico podría encontrarse en una empresa que recopila diversos datos sobre sus clientes. Esto puede incluir datos estructurados extraídos de transacciones o publicaciones no estructuradas en redes sociales y textos del centro de llamadas. Gran parte de esto podría llegar en forma de datos crudos, lo que requeriría una limpieza antes de procesarlos.
Veracidad
La veracidad se refiere a la calidad, exactitud, integridad y credibilidad de los datos. Es posible que a los datos recopilados les falten piezas, que sean inexactos o que no proporcionen información real y valiosa. La veracidad, en general, se refiere al nivel de confianza que hay en los datos recopilados.
A veces los datos pueden volverse confusos y difíciles de usar. Una gran cantidad de datos puede causar más confusión que conocimientos si están incompletos. Por ejemplo, en el campo médico, si los datos sobre qué medicamentos está tomando un paciente están incompletos, la vida del paciente podría correr peligro.
Tanto el valor como la veracidad ayudan a definir la calidad y los conocimientos recopilados a partir de los datos. Existen –o deberían existir– umbrales para la veracidad de los datos en una organización a nivel ejecutivo, para determinar si son adecuados para la toma de decisiones de alto nivel.
¿Dónde podría aparecer una señal de alerta sobre los datos de veracidad? Podría, por ejemplo, carecer de un linaje de datos adecuado, es decir, de un rastro verificable de sus orígenes y movimiento.
La sexta V: Variabilidad
Los 5 V anteriores cubren mucho terreno y contribuyen en gran medida a aclarar el uso adecuado de big data. Pero hay otra V que vale la pena considerar seriamente, la variabilidad, que no define tanto los big data sino que enfatiza la necesidad de gestionarlos bien.
La variabilidad se refiere a inconsistencias en el uso o el flujo de big data. En el caso del primero, una organización podría tener más de una definición en uso para datos particulares. Por ejemplo, una compañía de seguros podría tener un departamento que utilice un conjunto de umbrales de riesgo, mientras que otro departamento utiliza un conjunto diferente. En el segundo conjunto, los datos que fluyen hacia los almacenes de datos de la empresa de manera descentralizada –sin un punto de entrada común o validación inicial– podrían llegar a diferentes sistemas que los modifican, lo que resultaría en fuentes de verdad contradictorias en el lado de los informes.
Minimizar la variabilidad en big data requiere construir cuidadosamente flujos de datos a medida que los datos se mueven a través de los sistemas de la organización, desde lo transaccional hasta lo analítico y todo lo demás. El mayor beneficio es la veracidad de los grandes datos, ya que la coherencia en el uso de los datos genera informes y análisis más estables y, por lo tanto, una mayor confianza.
Investigue más sobre Big data y gestión de la información
-
![]()
¿Qué ocurre con big data en la era de la inteligencia artificial?
-
![]()
Principales tendencias en big data para 2024 y en adelante
Por: Ron Schmelzer
-
![]()
Las 18 mejores herramientas y tecnologías de big data que debe conocer
Por: Mary Pratt
-
![]()
El análisis de datos no estructurados es crítico, pero difícil
Por: Mike Jude



