
ÐндÑей ЯланÑкий -
Sesgo en ejemplos de aprendizaje automático: Policía, banca, COVID-19
El sesgo humano, los datos faltantes, la selección de datos, la confirmación de datos, las variables ocultas y las crisis inesperadas pueden contribuir a modelos, resultados y conocimientos de aprendizaje automático distorsionados.

Confiar en datos contaminados e intrínsecamente sesgados para tomar decisiones comerciales críticas y formular estrategias equivale a construir un castillo de naipes. Sin embargo, reconocer y neutralizar el sesgo en los conjuntos de datos de aprendizaje automático es algo que es más fácil decir que hacer porque el sesgo puede presentarse de muchas formas y en varios grados.
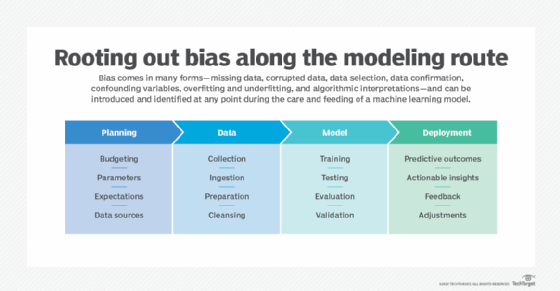
Entre los sesgos más comunes en los ejemplos de aprendizaje automático, el sesgo humano se puede introducir durante las fases de recopilación de datos, preparación y limpieza, así como en las fases de creación, prueba e implementación del modelo. Y no faltan ejemplos.
Algunas ciudades de EE. UU. han adoptado sistemas de vigilancia predictiva para optimizar su uso de los recursos. Un estudio reciente del AI Now Institute de la Universidad de Nueva York se centró en el uso de dichos sistemas en Chicago, Nueva Orleans y el condado de Maricopa, Arizona. El informe encontró que las prácticas policiales sesgadas se reflejan en datos de entrenamiento sesgados.
"[N]umerosas jurisdicciones sufren bajo las prácticas policiales continuas y generalizadas repletas de conductas ilegales, poco éticas y tendenciosas", observó el informe. "Esta conducta no solo influye en los datos utilizados para construir y mantener sistemas predictivos; apoya una cultura más amplia de prácticas policiales sospechosas y manipulación continua de datos".
Un aspecto preocupante es el circuito de retroalimentación que se ha creado. Dado que el comportamiento de la policía se refleja en los datos de capacitación, los sistemas predictivos anticipan que se producirán más delitos en los mismos vecindarios que han sido atacados de manera desproporcionada en primer lugar, independientemente de la tasa de delitos.
El sesgo de los datos a menudo resulta en discriminación, un gran problema ético. Al mismo tiempo, las organizaciones de todo tipo en diversas industrias deben hacer distinciones entre grupos de personas: por ejemplo, quiénes son los mejores y peores clientes, quiénes es probable o improbable que paguen las facturas a tiempo, o quiénes es probable o improbable que cometan un crimen.
"Es extremadamente difícil asegurarse de que ya no haya nada discriminatorio", dijo Michael Berthold, director ejecutivo del proveedor de plataformas de ciencia de datos KNIME. "Si saco de dónde vienes, cuánto ganas, dónde vives, tu [nivel] educativo y no sé qué más de ti, no queda nada que me permita discriminar entre tú y otra persona".
Faltan datos críticos
Los modelos de aprendizaje automático se utilizan comúnmente en los sistemas de ciberseguridad para identificar comportamientos anómalos, engañar a los delincuentes, realizar modelos de amenazas y más. Dado que los malos actores deben innovar continuamente para evitar ser detectados, están cambiando constantemente sus tácticas.
Los bancos establecen umbrales de transacción para la actividad de la cuenta, de modo que los titulares de las cuentas puedan ser notificados de una transferencia de fondos considerable en caso de que la transacción sea fraudulenta. Sabiendo esto, un grupo de hackers robó con éxito un total de mil millones de dólares al tomar montos en subdólares de millones de titulares de cuentas, según Ronald Coifman, profesor de matemáticas y ciencias de la computación en Phillips en la Universidad de Yale. Las transacciones pasaron desapercibidas porque eran demasiado sutiles para que las detectaran los sistemas de ciberseguridad existentes.
El elefante en la habitación son los falsos positivos. A los clientes bancarios no les importa recibir alertas sobre transacciones importantes, incluso si las iniciaron ellos mismos. Pero si cada transacción da como resultado una alerta automática, no importa cuán pequeña sea, los clientes pueden desarrollar fatiga por alerta y el equipo de ciberseguridad de un banco puede ahogarse en un exceso de ruido. Teniendo todo eso en cuenta, el banco implementó un nuevo sistema que utiliza diferentes algoritmos, al menos uno de los cuales combina álgebra lineal con geometría inferencial, para detectar y responder mejor a tipos de transacciones más pequeñas.
"Es posible que falten datos debido a errores metodológicos", dijo Edward Raff, científico jefe de Booz Allen Hamilton. "Usted está intentando crear un modelo representativo, pero hay algo que olvidó tener en cuenta y de lo que no se percató. Por lo tanto, cuando recopiló los datos, no tenía ningún procedimiento o plan para recopilar de alguna subpoblación".
Una forma de evitar el problema de la falta de datos es resolver el problema en colaboración con personas que tienen diferentes antecedentes. Como resultado, cada experto puede tender a tener una perspectiva diferente sobre el problema y sugerir variables que los demás podrían no considerar.
Sesgo en la selección de datos
Los investigadores médicos y farmacéuticos están tratando desesperadamente de identificar medicamentos aprobados que puedan usarse para combatir los síntomas de COVID-19 buscando en el creciente cuerpo de artículos de investigación, según Berthold de KNIME. "El problema que usted tiene... las publicaciones que tiene son en su mayoría positivas. Nadie publica resultados terribles", explicó. Por lo tanto, los investigadores no pueden tener en cuenta los resultados de muchas fallas en las pruebas de drogas.
La selección de datos ocupa un lugar destacado entre los sesgos en los ejemplos de aprendizaje automático. Ocurre cuando ciertos individuos, grupos o datos se seleccionan de una manera que no logra una aleatorización adecuada. "Es fácil caer en trampas al optar por lo fácil o extremo", dijo Raff. "Por lo tanto, usted está seleccionando según la disponibilidad, lo que potencialmente omite muchas cosas que realmente le interesan".

Sesgo de confirmación
En el mundo digital actual, más profesionales de negocios utilizan datos para probar o refutar algo. Pero, en lugar de formular una hipótesis y probarla como los científicos de datos están capacitados para hacer, es la naturaleza humana seleccionar datos que se alineen con el punto de vista del individuo. La investigación de marketing y política son ejemplos obvios.
El sesgo de confirmación también se filtra en los conjuntos de datos en forma de comportamiento humano. Los ciudadanos estadounidenses individuales, por ejemplo, se están alineando con uno de los dos comportamientos tribales de COVID-19. Un grupo cumple voluntariamente con el mandato de la máscara facial, mientras que el otro se rebela contra él. Los individuos en cualquiera de los grupos pueden "probar" la exactitud de su posición utilizando noticias e investigaciones que promuevan el punto de vista del individuo. Dado que el tema de las mascarillas se ha politizado, ese problema también se está abriendo camino en los conjuntos de datos.
Los científicos de datos pueden minimizar la probabilidad de sesgo de confirmación en ejemplos de aprendizaje automático al ser conscientes de su posibilidad y trabajar con otros para resolverlo. Sin embargo, algunos líderes empresariales a veces rechazan lo que muestran los datos porque quieren que los datos respalden cualquier punto que estén tratando de probar. En algunos casos, los científicos de datos tienen que elegir entre perder sus trabajos o torturar los datos para que digan lo que un ejecutivo quiera que digan.
"Eso puede suceder, desafortunadamente", señaló Raff. "La ciencia [de los datos] no es una herramienta para obtener las respuestas que desea, por lo que si dice: 'Esta es mi respuesta', no estamos haciendo ciencia de datos".
Variables de confusión
Los investigadores Alessandro Sette y Shane Crotty escribieron en Nature Reviews que "la memoria de células T CD4 reexistente podría... influir en los resultados de la vacunación contra el [COVID-19]". Y sugirieron que "la memoria preexistente de células T también podría actuar como un factor de confusión... Por ejemplo, si los sujetos con reactividad preexistente se clasificaran de manera desigual en diferentes grupos de dosis de vacuna, esto podría llevar a conclusiones erróneas".
Una variable confusa u oculta en los algoritmos de aprendizaje automático puede afectar negativamente la precisión del análisis predictivo porque influye en la variable dependiente.
"Tener [una] matriz de correlación completa antes del modelo predictivo es muy importante", explicó el profesor de Berkeley College, Darshan Desai. "El análisis de datos exploratorio que realiza es extremadamente importante para identificar qué variables son importantes para mantener en el modelo, cuáles son las que están altamente correlacionadas entre sí y causan más problemas en el modelo que agregar información adicional".
Una variable de confusión, agregó Raff, puede ser uno de los sesgos más difíciles de resolver por completo en los ejemplos de aprendizaje automático porque los científicos de datos y otros no necesariamente saben cuál es el factor externo. "Por eso es importante no solo tener científicos de datos, sino también expertos en dominio sobre el problema", razonó.
Modelos de sobreajuste
El pasado no es necesariamente indicativo del futuro, sin embargo, los modelos predictivos utilizan datos históricos para predecir eventos futuros. Durante los últimos meses, algunos investigadores han intentado predecir los impactos del COVID-19 en un lugar basándose en investigaciones realizadas en otras partes del mundo.
"Generalización", explicó Berthold de KNIME, "significa que estoy interesado en modelar un determinado aspecto de la realidad y quiero usar ese modelo para hacer predicciones sobre nuevos puntos de datos. Y si no define qué aspectos de la realidad le preocupan lo suficiente, entonces incluirá todo tipo de pequeños parámetros que a nadie realmente le importan. Si tiene todos los otros problemas bajo control, [el sobreajuste es] bastante fácil de controlar porque, cuando entrena modelos, tiene una muestra totalmente independiente que utiliza para la prueba".
La independencia de los datos de las pruebas de validación a veces puede ser cuestionable. Un estudio reciente, por ejemplo, desarrolló una puntuación de riesgo para la enfermedad grave de COVID-19 basada en una población total de 2.300 personas. Los datos de capacitación representaron a 1.590 pacientes con diagnósticos de COVID-19 confirmados por laboratorio que fueron hospitalizados en uno de los 575 hospitales entre el 21 de noviembre de 2019 y el 31 de enero de 2020. Los datos de prueba representaron a 710 personas de cuatro fuentes, tres de las cuales habían tenido seguimiento hasta el 28 de febrero de 2020.
Un resumen del informe, publicado por la Facultad de Salud Pública Bloomberg de la Universidad Johns Hopkins, señaló: "Los datos para las cohortes de desarrollo y validación eran de China, por lo que se desconoce la aplicabilidad del modelo a poblaciones fuera de China. No está claro si los autores corrigieron por sobreajuste".
Una forma de reconocer el sobreajuste es cuando un modelo está demostrando un alto nivel de precisión (90 %, por ejemplo) según los datos de entrenamiento, pero su precisión cae significativamente, digamos, al 55 % o 60 %, cuando se prueba con los datos de validación.




