
bluebay2014 - Fotolia
Cómo elegir un servidor basado en las necesidades de su centro de datos
En un esfuerzo por optimizar el rendimiento en la empresa, TI debe evaluar las principales prioridades para determinar cómo elegir un servidor y crear las cargas de trabajo más eficientes.
Los servidores son el corazón de la computación moderna, pero la contemplación de cómo elegir un servidor para alojar una carga de trabajo a veces puede crear una desconcertante variedad de opciones de hardware. Si bien es posible llenar un centro de datos con sistemas de caja blanca idénticos, virtualizados y agrupados que son capaces de administrar cualquier carga de trabajo, la nube está cambiando la manera en que las organizaciones ejecutan las aplicaciones. A medida que más empresas implementan cargas de trabajo en la nube pública, los centros de datos locales requieren menos recursos para alojar las cargas de trabajo que permanecen en las instalaciones. Esto está impulsando a los líderes empresariales y de TI a buscar más valor y rendimiento de la flota de servidores en reducción.
Hoy, el mar expansivo de los sistemas de caja blanca es desafiado por una nueva ola de especialización con características de servidor. Algunas organizaciones están redescubriendo la noción de que un servidor puede adaptarse a todos. Pero usted puede seleccionar o incluso adaptar el hardware del clúster del servidor para acomodar categorías de uso particulares.
La consolidación de VM y la E/S de la red agregan beneficios
Un beneficio central de la virtualización de servidores es la capacidad de alojar varias máquinas virtuales en el mismo servidor físico para utilizar más de los recursos informáticos disponibles de un servidor. Las máquinas virtuales se basan principalmente en la memoria del servidor (RAM) y los núcleos del procesador. Es imposible determinar con precisión cuántas VM pueden residir en un servidor determinado porque usted puede configurar máquinas virtuales para que utilicen una amplia gama de espacio de memoria y núcleos de procesador. Sin embargo, la regla general en los servidores incluye que seleccionar uno con más memoria y núcleos del procesador generalmente permitirá que más máquinas virtuales residan en el mismo servidor, lo que mejora la consolidación.
Por ejemplo, un servidor en rack PowerEdge R940 de Dell EMC puede alojar hasta 28 núcleos de procesador y ofrece 48 ranuras de módulos de memoria dual en línea (DIMM) de doble tasa de datos 4 (DDR4), que admiten hasta 6 TB de memoria. Algunas organizaciones pueden optar por renunciar a los servidores en rack individuales a favor de los servidores blade para un factor de forma alternativo o como parte de sistemas de infraestructura hiperconvergentes. Los servidores destinados a altos niveles de consolidación de máquinas virtuales también deben incluir funciones de servidor de resiliencia, como fuentes de alimentación redundantes intercambiables en caliente, y funciones de memoria resilientes, como intercambio en caliente de DIMM y replicación en espejo de DIMM.
Una consideración secundaria sobre cómo elegir un servidor para propósitos altamente consolidados es la atención adicional a la E/S de la red. Las cargas de trabajo de la empresa intercambian datos de manera rutinaria, acceden a recursos de almacenamiento centralizados, interactúan con los usuarios a través de la LAN o WAN, y así sucesivamente. Se puede producir cuellos de botella en la red cuando varias máquinas virtuales intentan compartir el mismo puerto de red de gama baja. Los servidores consolidados se pueden beneficiar de una interfaz de red rápida, como un puerto Ethernet de 10 Gigabit, aunque a menudo es más económico y flexible seleccionar un servidor con múltiples puertos de 1 GbE que pueda conectar juntos para obtener mayor velocidad y resiliencia.
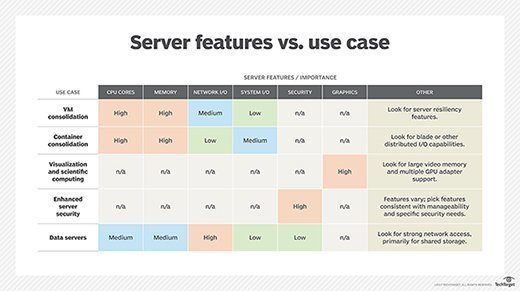
La consolidación de contenedores abre la RAM sobre cómo elegir un servidor
Los contenedores virtualizados representan un enfoque relativamente nuevo para la virtualización que permite a los desarrolladores y equipos de TI crear e implementar aplicaciones como instancias que combinan códigos y dependencias, aunque los contenedores comparten el mismo núcleo del sistema operativo subyacente. Los contenedores son atractivos para el desarrollo y la implementación de aplicaciones basadas en la nube altamente escalables.
Al igual que con la consolidación de VM, los recursos de cómputo tendrán un efecto directo en la cantidad de contenedores que un servidor puede albergar potencialmente, por lo que los servidores destinados a contenedores deberían proporcionar una amplia cantidad de RAM y núcleos de procesador. Más recursos de cómputo generalmente permitirán más contenedores.
Pero un gran número de contenedores simultáneos puede imponer serios desafíos internos de E/S para el servidor. Cada contenedor debe compartir un núcleo de sistema operativo común. Esto significa que podría haber docenas o incluso cientos de contenedores tratando de comunicarse con el mismo núcleo, lo que daría como resultado una latencia de SO excesiva que podría afectar el rendimiento del contenedor. Del mismo modo, los contenedores a menudo se implementan como componentes de la aplicación, no como aplicaciones completas. Esos contenedores de componentes deben comunicarse entre sí y ampliarse según sea necesario para mejorar el rendimiento de la carga de trabajo general. Esto puede generar un tráfico de APIs enorme, a veces impredecible, entre contenedores. En ambos casos, las limitaciones de ancho de banda de E/S dentro del servidor, así como la eficiencia del diseño arquitectónico de la aplicación, pueden limitar el número de contenedores que un servidor podría alojar con éxito.
La E/S de red también puede representar un cuello de botella potencial cuando muchas cargas de trabajo en contenedores deben comunicarse fuera del servidor a través de la LAN o WAN. Los cuellos de botella en la red pueden ralentizar el acceso al almacenamiento compartido, retrasar las respuestas de los usuarios e incluso precipitar errores en las cargas de trabajo. Considere las necesidades de red de los contenedores y las cargas de trabajo, y configure el servidor con la capacidad de red adecuada, ya sea como un puerto rápido de 10 GbE o con múltiples puertos de 1 GbE, que puede conectar entre sí para obtener más velocidad y resiliencia.
La mayoría de los tipos de servidores son capaces de albergar contenedores, pero las organizaciones que adoptan grandes volúmenes de contenedores elegirán con frecuencia servidores blade para combinar la capacidad de cómputo con capacidades de E/S medidas, distribuyendo contenedores en varios blades para distribuir la carga de E/S. Un ejemplo de servidor para contenedores es el Hewlett Packard Enterprise (HPE) ProLiant BL460c Gen10 Server Blade con hasta 26 núcleos de procesador y 2 TB de memoria DDR4.
La visualización y la computación científica afectan la forma de elegir un servidor
Las unidades de procesamiento de gráficos (GPU) están apareciendo cada vez más en el nivel del servidor para ayudar en las tareas matemáticas intensivas que van desde el procesamiento de big data y la computación científica hasta tareas más relacionadas con gráficos, como el modelado y la visualización. Las GPU también permiten que TI retenga y procese conjuntos de datos confidenciales y valiosos en un centro de datos mejor protegido, en lugar de permitir que esos datos fluyan a los puntos finales de negocios donde se pueden copiar o robar más fácilmente.
En general, el soporte para GPU requiere poco más que la adición de una tarjeta GPU adecuada en el servidor: hay poco impacto en el procesador tradicional del servidor, memoria, E/S, almacenamiento, red u otros detalles de hardware. Sin embargo, los adaptadores de GPU incluidos en los servidores de clase empresarial suelen ser mucho más sofisticados que los adaptadores de GPU disponibles para equipos de escritorio o estaciones de trabajo. De hecho, las GPU están cada vez más disponibles como módulos altamente especializados para sistemas blade.
Por ejemplo, el servidor blade de gráficos HPE ProLiant WS460c Gen9 utiliza tarjetas gráficas Nvidia Tesla M60 Peripheral Component Interconnect Express con dos GPUs, 4.096 núcleos de arquitectura de dispositivo unificado de cómputo y 16 GB de RAM de video DDR5 para gráficos por separado. El sistema de gráficos promociona la compatibilidad con hasta 48 GPU a través del uso de múltiples servidores blade de gráficos. El gran volumen de hardware GPU compatible, especialmente cuando el hardware GPU también está virtualizado, permite que muchos usuarios y cargas de trabajo compartan el subsistema gráfico.




