
alex_aldo - Fotolia
Cinco principios del proceso de gestión del cambio en las redes
La gestión de cambios en la red incluye cinco principios básicos, que incluyen el análisis de riesgos y la revisión por pares. Estas mejores prácticas pueden ayudar a los equipos de red a limitar los cambios fallidos de la red y las interrupciones.
La gestión de cambios de red es un proceso que tiene la intención de reducir el riesgo de un cambio fallido. Este proceso implica varios pasos que aseguran cambios exitosos, pero ¿cómo funciona cada paso?
Los pilotos de aeronaves utilizan procesos bien definidos para garantizar un vuelo seguro. Del mismo modo, los equipos de redes pueden usar procesos definidos para reducir el riesgo de cambios fallidos en la red que crean interrupciones no planificadas. Aún así, las organizaciones a veces encuentran que los cambios no salen según lo planeado, lo que resulta en una interrupción. Algunas fallas se deben a una falla del proceso, mientras que otras se deben a resultados no obvios de configuraciones complejas.
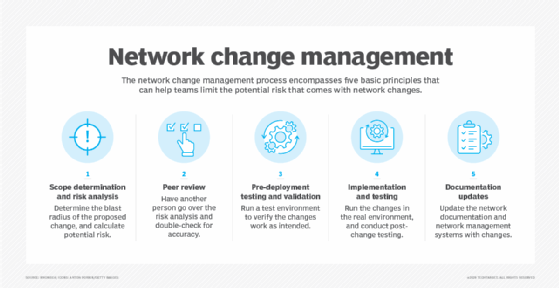
El proceso de gestión de cambios en la red se basa en la aplicación de varios principios operativos básicos, como los siguientes:
- Determinación del alcance y análisis de riesgos
- Revisión por pares
- Pruebas y validación previas a la implementación
- Implementación y pruebas
- Actualizaciones de documentación.
Los equipos de red realizan el proceso de creación de los detalles del cambio (nuevas configuraciones, información de conexión del dispositivo y documentación) antes del proceso de gestión del cambio. Una guía valiosa para la gestión del cambio en la red es el documento técnico "Gestión del cambio: mejores prácticas" de Cisco.
Alcance y análisis de riesgos
El primer paso en el proceso de gestión de cambios en la red debe ser evaluar el alcance de un cambio propuesto. Determine qué servicios podrían verse afectados y quién los utiliza. El término radio de explosión se usa con frecuencia para describir el alcance del efecto que puede tener un cambio, incluidos los posibles resultados negativos.
Los equipos querrán medir el alcance en términos de los dos factores siguientes:
- El número de puntos finales afectados por un cambio; y
- La importancia de los servicios a los que podría afectar un cambio.
Una vez que los equipos identifican el alcance, deben realizar una evaluación del riesgo del cambio. ¿Es algo que se ha hecho varias veces en el pasado y se entiende bien? ¿Está completamente automatizado o existe la posibilidad de que un error humano altere el cambio de una manera inesperada? ¿Se entiende bien la tecnología involucrada o existe la posibilidad de que ocurra algo inesperado?
El alcance de un cambio figura en el riesgo. Un cambio en la infraestructura en la que se ejecutan los procesos comerciales clave tendrá un mayor nivel de riesgo para el negocio que un cambio en una sucursal pequeña.
Los equipos de red pueden usar una calculadora de factores de riesgo que asigna valores a parámetros clave. Para crear una calculadora de riesgo, promedie los valores de los parámetros de ejemplo a continuación o busque una calculadora en la web.
- ¿El efecto será visible para los clientes? (No = 1, Sí = 10)
- ¿Cuántos clientes podrían verse afectados? (Rango de 1 a 10)
- ¿Qué tan importantes son los servicios dentro del alcance? (Rango de 1 a 10)
- ¿Se ha implementado este cambio con éxito en el pasado? (Sí = 1, No = 10)
- ¿Está automatizado el cambio? (Rango de 1 a 10, dependiendo del grado de automatización)
- ¿Se puede probar a fondo el cambio antes de la implementación? (Sí = 1, No = 10)
- ¿La documentación del proveedor es clara e inequívoca? (Rango de 1 a 10)
- ¿La revisión por pares es exhaustiva y surgió algún problema potencial? (Rango de 1 a 10)
Cuanto mayor sea el riesgo, más cuidadosos deberán ser los equipos durante el resto del proceso de gestión del cambio.
Revisión por pares
El siguiente paso es realizar una revisión por pares. Si bien los equipos pueden realizar este paso antes del análisis de riesgos, es mejor utilizar el nivel de riesgo para conducir la minuciosidad de una revisión por pares. Si bien todas las revisiones por pares deben ser comparativamente exhaustivas, los cambios de rutina, como los cambios en la lista de control de acceso o la modificación de LAN virtuales, probablemente recibirán revisiones rápidas. Las pruebas automatizadas y el despliegue de cambios de rutina pueden ayudar a mitigar el riesgo de revisiones rápidas en pares.
El personal interno que está familiarizado con la red llevará a cabo la mayoría de las revisiones por pares. Sin embargo, si un cambio está fuera de lo normal, tiene sentido contar con un experto del proveedor del equipo para realizar la revisión. Las revisiones deben retroalimentar la fase de análisis de riesgos, potencialmente actualizando las mediciones técnicas de riesgo, como indicar si las pruebas y la documentación son suficientes.
Pruebas previas a la implementación y validación
Idealmente, todos los cambios pasarían por una fase de prueba y validación previa a la implementación. La automatización de los cambios repetitivos de bajo riesgo puede eliminar la tentación de omitir las pruebas en los cambios que los equipos perciben como de bajo riesgo. Por supuesto, cuanto mayor es el alcance y el riesgo, más importante es probar y validar adecuadamente el cambio propuesto.
La prevalencia de instancias de SO de enrutador virtual y conmutador hace que sea más fácil automatizar la creación de topologías de red de prueba sin costosas inversiones en hardware. Los equipos necesitarán construir automatización para crear la topología de red virtual y derribarla cuando las pruebas se hayan completado con éxito.
Las pruebas previas a la implementación incluyen varios pasos que los equipos deben seguir para evaluar un cambio propuesto:
- Verifique que la red de prueba funcione actualmente según lo previsto antes del cambio.
- Implemente el cambio en una infraestructura de prueba para confirmar que el cambio da como resultado el estado final deseado. Los equipos deben usar procesos automatizados para evitar errores humanos y reducir el tiempo para validar el cambio. Si la validación en el entorno de prueba falla, determine la razón. ¿Falló porque el cambio fue incorrecto o fue porque la red de prueba no representa con precisión la red real?
- Pruebe el proceso de cambio de retroceso para que sea fácil volver al estado anterior si algo sale mal. El cambio de retroceso debería devolver la red al estado inicial, que los equipos pueden validar repitiendo el Paso 1.
Implementación y prueba
La implementación y las pruebas posteriores a la implementación y el paso de validación deben seguir el mismo proceso que en los Pasos 1 y 2 de las pruebas previas a la implementación. Si los equipos han hecho un buen trabajo de pruebas y validación previas a la implementación, no debería ocurrir nada inesperado. Si las pruebas posteriores al cambio detectan un problema inesperado, los equipos deben retroceder el cambio y verificar la restauración del servicio.
Algunos protocolos de red requerirán más tiempo para converger después de los cambios en redes grandes, lo que requiere que el proceso de verificación posterior al cambio incorpore demoras o pruebas de convergencia que una prueba previa a la implementación en un entorno de prueba pequeño no necesita.
Las organizaciones más avanzadas están automatizando los cambios en la configuración de la red con el objetivo de migrar a una cultura DevOps basada en la infraestructura como código. El objetivo es adoptar una integración continua y un proceso de prueba y despliegue continuo para cambios de bajo riesgo.
Documentación y actualizaciones de gestión de red
Idealmente, los equipos crearán y actualizarán documentos durante el proceso de creación del cambio, permitiéndoles revisar la documentación y los cambios en la administración de la red junto con los detalles del cambio. Una vez que los equipos han implementado y verificado el cambio, pueden incorporar los cambios de documentación en el sistema de documentación de la red.
No olvide actualizar el sistema de administración de la red según sea necesario. La mayoría de los sistemas de administración de red tienen API que permiten que los procesos automatizados realicen los cambios.
Si el paso de validación de cambio está automatizado, se puede incorporar a las verificaciones periódicas de validación de red. Estas verificaciones periódicas pueden detectar fallas en redes altamente redundantes y resistentes. Con el tiempo, los equipos construirán una biblioteca de comprobaciones de validación de red que abarque muchas partes de la red.
Los principios de una buena gestión de cambios en la red proporcionan orientación para reducir las interrupciones de red no planificadas debido a cambios fallidos. Los equipos deben crear un proceso que funcione para su organización y trabajar para hacer que ese proceso sea altamente eficiente.





