
freshidea - Fotolia
Almacenamiento de objetos, bloques y archivos: ¿cuál es mejor para las aplicaciones en la nube?
El almacenamiento de objetos, archivos y bloques a menudo compiten por los corazones y las mentes de los usuarios de aplicaciones en la nube. Tomar la decisión correcta puede tener un efecto profundo en el rendimiento, la confiabilidad y el costo de la aplicación.
El almacenamiento de bloques, archivos y objetos tiene diferencias y similitudes significativas. A lo largo de los años, esas diferencias se han reducido mientras que las similitudes han aumentado, lo que dificulta aún más la elección del almacenamiento más adecuado para las aplicaciones en la nube.
La elección del almacenamiento comienza por determinar las necesidades y los requisitos de las aplicaciones en la nube, como el acceso al almacenamiento a través de:
- Bloque: NVMe, NVMe-oF, iSCSI, canal de fibra
- Archivo: NFS, SMB
- Archivo paralelo: Lustre, Spectrum Scale, Panasas, WekaIO, BeeGFS
- Objeto: S3 (API RESTful)
Si la aplicación solo puede acceder al almacenamiento a través de un protocolo específico y el propietario de la aplicación no puede dedicar tiempo ni recursos para modificar la aplicación, la decisión de almacenamiento se toma de forma predeterminada.
Si este no es el caso, otros requisitos que influyen en la decisión incluyen el almacenamiento persistente de contenedores con estado –que no es un hecho para todos los sistemas– la protección de datos, la continuidad del negocio, la recuperación ante desastres y la seguridad. Asegúrese de que los propietarios de las aplicaciones aprueben los requisitos antes de seguir adelante.
El segundo paso para elegir el almacenamiento más adecuado para las aplicaciones en la nube requiere una comprensión de lo que son, lo que hacen, lo que no hacen, los mejores casos de uso para cada uno y cómo se comparan el almacenamiento de objetos, bloques y archivos. La comprensión y la profundidad del conocimiento reducen el riesgo de tomar una decisión menos que ideal para las necesidades específicas de la organización.
¿Qué es el almacenamiento en bloque?
El almacenamiento en bloque es el tipo predeterminado para los medios de almacenamiento –HDD o SSD– en servidores y estaciones de trabajo. También se encuentra en almacenamiento DAS, SAN y Remote Direct Memory Access (RDMA) mediante protocolos NVMe-oF.
Se llama bloque porque los datos se dividen y almacenan como bloques. Estos bloques se distribuyen físicamente en los medios de almacenamiento para una eficiencia óptima. Cada bloque recibe un identificador único que permite reconstituir los datos para lecturas.
Ventajas del almacenamiento en bloque
El rendimiento es la mayor ventaja del almacenamiento en bloque para las aplicaciones en la nube. En concreto, la latencia. La latencia es extremadamente importante cuando se trata del tiempo de respuesta de la transacción de la aplicación. Una latencia más baja se traduce en tiempos de respuesta más rápidos y más IOPS.
El almacenamiento en bloque también es relativamente simple. Los sistemas de archivos del servidor escriben en él de forma nativa. Las aplicaciones en la nube suelen utilizar el almacenamiento en bloques en la nube cuando necesitan lecturas o escrituras rápidas. Debido a que el almacenamiento en bloque desacopla los datos de la aplicación de la aplicación, permite que los datos se distribuyan en varias unidades y volúmenes. Eso acelera la recuperación de datos.
Desventajas del almacenamiento en bloque
El almacenamiento en bloque no tiene metadatos. Eso limita su flexibilidad. No hay capacidad de búsqueda o análisis de datos integrado. Aunque varios sistemas de almacenamiento en bloque promueven su análisis, estos son principalmente análisis de almacenamiento y unidades, no análisis de datos.
El almacenamiento en bloque en la nube suele tener graves limitaciones de escalabilidad. Las aplicaciones en la nube están limitadas a la cantidad de unidades accesibles.
Casos de uso de almacenamiento en bloque
Los casos de uso más comunes para el almacenamiento en bloque son:
- Bases de datos relacionales o transaccionales.
- Bases de datos de series temporales.
- Aplicaciones críticas para la misión y el negocio que requieren latencias y tiempos de respuesta muy bajos. Los ejemplos incluyen comercio de alta frecuencia, comercio electrónico como Magento, procesamiento de transacciones en línea, CRM y automatización de márketing.
- Almacenamiento general para servidores virtualizados y bare metal.
- Medios de almacenamiento subyacentes al almacenamiento de archivos y objetos.
- Sistemas de archivos de hipervisor, que también tienden a utilizar almacenamiento en bloque debido a su distribución en varios volúmenes.
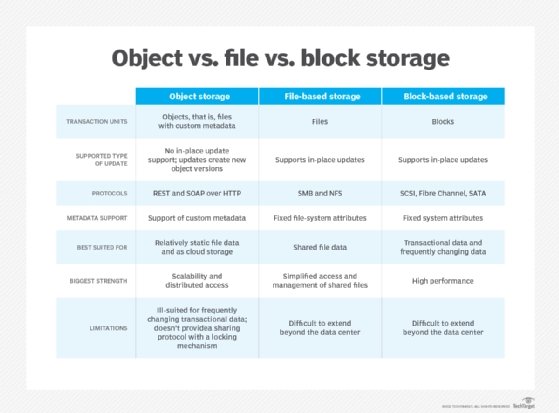
¿Qué es el almacenamiento de archivos?
El almacenamiento de archivos se organiza de manera similar a la forma en que las personas organizan los archivos físicos en un archivador. Los archivos se colocan sistemáticamente en carpetas y se organizan mediante convenciones de nomenclatura basadas en características como extensiones, categorías o aplicaciones. Los sistemas de archivos se presentan como una jerarquía de directorios, subdirectorios y archivos. Además, los archivos se almacenan con metadatos limitados, como el nombre del archivo, la fecha de creación, el creador, el tipo de archivo, el cambio más reciente y el último acceso.
La localización de un archivo se realiza de forma manual o programática trabajando a través de la jerarquía. Los usuarios o las aplicaciones en la nube que acceden a un archivo simplemente requieren la ruta del directorio al subdirectorio de la carpeta al archivo. Por lo general, es fácil nombrar, eliminar o manipular archivos sin ninguna interfaz adicional porque los archivos ya están organizados en un árbol de directorios jerárquico.
Buscar y ubicar archivos es relativamente fácil con una pequeña cantidad de archivos, pero puede ser extremadamente difícil a medida que la cantidad de archivos llega a miles de millones.
Una variación del almacenamiento de archivos es el almacenamiento de archivos en paralelo. Este tipo de sistema de almacenamiento de archivos está diseñado para lecturas simultáneas masivas y, en menor medida, escrituras simultáneas masivas. El almacenamiento de archivos en paralelo es más común con Data Direct Networks, IBM Spectrum Scale, Lustre de código abierto, BeeGFS de código abierto, Panasas y WekaIO. Los casos de uso son estrechos pero crecientes.
Ventajas del almacenamiento de archivos
La simplicidad se considera comúnmente la mayor ventaja del almacenamiento de archivos. Esa ventaja se percibe aún más en la nube a través de la colaboración y el uso compartido de archivos extendidos.
Muchas aplicaciones se han escrito y optimizado para el almacenamiento de archivos. Los hipervisores ubicuos de proveedores como VMware tienen NFS integrado. Varias bases de datos relacionales, como Oracle y Microsoft SQL Server, funcionan de forma nativa con almacenamiento de archivos, al igual que las bases de datos de código abierto populares, como MySQL, MariaDB, PerconaDB y PostgreSQL. Además, la mayoría de las bases de datos opcionales de esquema, como Casandra y MongoDB, funcionan de forma nativa con el almacenamiento de archivos.
Hay otra ventaja que proviene del almacenamiento de archivos de terceros que se ejecuta en la nube pública: implementaciones de software de proveedores de almacenamiento como Dell EMC, Pure Storage, Rozo Systems, StorOne, WekaIO y Zadara Storage. Estas ofertas de suscripción en la nube de pago por uso (PAYG) permiten el almacenamiento de archivos compartidos para aplicaciones en la nube, lo que reduce los costos al eliminar el almacenamiento huérfano. Los costosos SSD o SSD NVMe se pueden compartir entre varias aplicaciones.
Desventajas del almacenamiento de archivos
El costo es la desventaja más notable del almacenamiento de archivos en la nube. El almacenamiento de archivos en la nube suele ser de tres a cuatro veces más caro que el almacenamiento en bloque y un orden de magnitud más caro que el almacenamiento de objetos en la nube.
El rendimiento es otro tema. El almacenamiento de archivos requiere una capa superior de software frente a los medios de almacenamiento en bloque. Eso agrega latencia y reduce el tiempo de respuesta, las IOPS y el rendimiento. Sin embargo, varios sistemas de almacenamiento de archivos han reducido significativamente esa latencia general, por lo que es un problema mucho menor. Esto lo han logrado haciendo que su software de almacenamiento de archivos sea mucho más eficiente (StorOne), u optimizándolo para flash (Pavilion Data Systems, Pure Storage, Vast Data), agregando potencia de procesamiento (Pavilion Data) o usando RDMA de baja latencia. NFS (varios).
Quizás la desventaja más reclamada de los sistemas de almacenamiento de archivos es la escalabilidad limitada. Los sistemas de almacenamiento de archivos pueden atascarse a medida que la cantidad de archivos aumenta de cientos a miles de millones. Esta es una percepción obsoleta que no se aplica a muchos de los últimos sistemas de almacenamiento de archivos. Los sistemas de almacenamiento de archivos más recientes —Ctera Networks, Dell EMC, Nasuni, Panzura, Pavilion Data, Pure Storage, Qumulo, Vast Data y WekaIO— han superado este cuello de botella histórico de escalabilidad del almacenamiento de archivos mediante la implementación de una arquitectura escalable y/o un espacio de nombres global.
Casos de uso de almacenamiento de archivos
Los casos de uso de almacenamiento de archivos más comunes son:
- IA-aprendizaje automático
- Aprendizaje automático profundo de IA
- Analíticas de todo tipo
- Registros de salud
- Video transmitido en vivo
- Transmisión auditiva
- multimedios en general
- aplicaciones de oficina
- Almacenamiento de destino para copia de seguridad
- Almacenamiento de destino para archivo
- Uso compartido de archivos y colaboración en el flujo de trabajo.
Los casos de uso de almacenamiento de archivos menos comunes, pero aún importantes, incluyen:
- Aplicaciones de clúster de computación de alto rendimiento que utilizan almacenamiento de archivos paralelo
- Espacio de nombres global distribuido geográficamente (intercambio/colaboración)
- Ctera, Nasuni, Panzura
- VMware ESX y vSphere
- Bases de datos relacionales
- Bases de datos opcionales de esquema
¿Qué es el almacenamiento de objetos?
El almacenamiento de objetos organiza los datos no estructurados de una manera muy eficiente y poco intuitiva para las personas. No hay jerarquía, se trata de los objetos individuales. Es una arquitectura donde nada se comparte que permite, en teoría, una escalabilidad ilimitada. Los archivos se almacenan como objetos en diferentes ubicaciones y cada objeto tiene un identificador único con cantidades considerables de metadatos. La cantidad de metadatos es variable –y significativamente mayor que los metadatos del archivo– y su tamaño oscila entre kilobytes y gigabytes.
Los metadatos de almacenamiento de objetos incluyen los metadatos que normalmente se encuentran en los sistemas de archivos, mientras que comúnmente incluyen un resumen del contenido del archivo, palabras clave, puntos clave, comentarios, ubicaciones de objetos asociados, políticas de protección de datos, seguridad, acceso y ubicaciones geográficas.
Esos metadatos mejorados permiten que el almacenamiento de objetos proteja, administre, manipule y mantenga los objetos en un nivel mucho más fino de granularidad que el bloque o el archivo. Un ejemplo general de esto es la capacidad del almacenamiento de objetos para aumentar la durabilidad de los datos con el uso de códigos de borrado.
Los códigos de borrado dividen un archivo en múltiples objetos en diferentes unidades de almacenamiento, nodos de almacenamiento/servidor e incluso ubicaciones geográficas. Los códigos de borrado brindan resiliencia de datos de múltiples fallas simultáneas de unidades y/o nodos de almacenamiento. Esta es una resiliencia mayor que RAID o incluso RAID de paridad triple.
La localización de datos representados por varios objetos se realiza a través del identificador único del objeto y sus metadatos. No hay jerarquía para escanear o rastrear. Una granularidad más fina significa que se pueden proporcionar muchas funciones por objeto. Cuando la protección de datos, la replicación, la búsqueda, la minería, el movimiento y la gestión son más granulares –como en los almacenes de objetos– también se vuelven más rápidos y eficientes. Esto se nota cada vez más a medida que la cantidad de archivos crece a miles de millones o billones.
Ventajas del almacenamiento de objetos
La mayor ventaja del almacenamiento de objetos es el bajo costo. Esta es una razón principal por la que las organizaciones lo seleccionan para aplicaciones en la nube.
La escalabilidad masiva es la segunda mayor ventaja. Esa escalabilidad es el resultado directo de la arquitectura de nada compartido y la estructura plana del almacenamiento de objetos. El uso de identificadores únicos globales frente a las jerarquías de almacenamiento de archivos o almacenamiento en bloque facilita esa escalabilidad. Los almacenes de objetos han demostrado un crecimiento en exabytes de datos y tienen el potencial de crecer a una escala de zettabyte o incluso yottabyte.
Los metadatos sin restricciones proporcionan ventajas adicionales. Los administradores de almacenamiento tienen flexibilidad en la forma en que habilitan la conservación de datos, la retención de datos, el movimiento de datos desde nodos de mayor valor que usan SSD flash a nodos de menor valor que usan HDD y eliminaciones o vencimientos de datos.
Otra ventaja es la resiliencia de los datos frente a fallas de hardware debido a la codificación de borrado. El almacenamiento de objetos se puede programar para proteger contra un gran número de fallas de unidades y/o nodos de almacenamiento. Las unidades no se reconstruyen como se hace con RAID, pero los datos sí, y se reconstruyen rápidamente en varias unidades.
El almacenamiento de objetos se ha convertido en el almacenamiento principal para los proveedores de nube pública más grandes, incluidos AWS, Microsoft, Oracle, Google, Alibaba e IBM debido a estos beneficios.
Desventajas del almacenamiento de objetos
La codificación de borrado es excelente para la resiliencia de los datos, pero agrega una latencia significativa para lecturas y escrituras. La codificación de borrado consume mucha CPU y memoria, lo que ralentiza notablemente los tiempos de respuesta. Por lo tanto, el almacenamiento de objetos rara vez se usa más allá del almacenamiento secundario o terciario. Algunos proveedores han intentado mitigar este problema de latencia con implementaciones que se enfocan en SSD flash. Estos son más rápidos pero aún tienen latencias más altas que el almacenamiento de bloques o archivos con SSD.
La codificación de borrado tampoco protege contra la corrupción de datos, errores humanos o malware/ransomware. El almacenamiento de objetos, en general, no proporciona instantáneas, un elemento básico para el almacenamiento de bloques y archivos que proporciona ese nivel de protección.
Muchos sistemas de almacenamiento de objetos –también sistemas de almacenamiento de archivos y bloques– pueden proporcionar contenedores o cubos de almacenamiento inmutables basados en retención o de escritura única y muchas lecturas. Esto evita que los datos se alteren de alguna manera durante el período de retención. Esta es una capacidad importante en el entorno actual de ransomware y leyes de privacidad. Sin embargo, la mayoría de estos sistemas generalmente no escanean, detectan ni aíslan malware/ransomware en los datos almacenados en ese almacenamiento inmutable.
Aunque varios almacenes de objetos (DataCore Caringo, IBM Red Hat Ceph, Scality Ring) tienen una interfaz NAS integrada o una puerta de enlace NAS física, no pueden igualar el rendimiento del tiempo de respuesta de los sistemas NAS nativos. Tanto el almacenamiento de archivos como el de objetos a menudo tienen una función de puerta de enlace iSCSI en bloque. Una vez más, la variación de NAS suele ser –aunque no siempre– más eficaz que el equivalente de almacenamiento de objetos. Para aprovechar al máximo un almacén de objetos, la aplicación o el sistema de archivos del servidor debe utilizar la API RESTful. La API RESTful estándar de facto es actualmente S3. A medida que ha crecido la popularidad de AWS, también lo ha hecho la cantidad de aplicaciones que utilizan la API de S3. Esto no es una desventaja tan grande como solía ser, pero todavía está muy por detrás de las aplicaciones de almacenamiento de archivos.
A los sistemas de archivos, por otro lado, se accede a través de los protocolos estándar NFS, SMB, NFS paralelo, RDMA NFS o incluso Hadoop Distributed File System, así como IBM Spectrum Scale (anteriormente Global File Sharing System), Lustre, Panasas y WekaIO.
Casos de uso de almacenamiento de objetos
Los casos de uso de almacenamiento de archivos más comunes son:
- Almacenamiento de destino para copias de seguridad.
- Almacenamiento de destino para archivos o bóvedas.
- Intercambio de archivos y colaboración utilizando aplicaciones de sincronización y uso compartido de archivos como depósito central.
- Registros de salud.
- Video transmitido en vivo.
- Transmisión auditiva.
- Multimedios en general.
- IA, aprendizaje automático y aprendizaje automático profundo, especialmente con conjuntos de datos muy grandes.
- Archivadores perimetrales de espacios de nombres globales distribuidos geográficamente (Ctera, Nasuni, Panzura) que utilizan el almacenamiento de objetos como lago de datos centralizado.
- Lago de datos para análisis a gran escala, como almacenes de datos.
- Snowflake ejecuta su servicio de almacenamiento de datos en la nube sobre el almacenamiento de objetos de AWS S3.
Consideraciones de costos de selección de almacenamiento
El último paso para elegir el almacenamiento más adecuado para las aplicaciones en la nube es calcular el TCO. No es simplemente el precio de compra o suscripción. También incluye los costos de infraestructura de soporte, como espacio en rack, conmutadores, cables, conductos, transceptores, energía, refrigeración, fuente de alimentación ininterrumpida, WAN (si es necesario), capacitación, actualización de tecnología, tiempo de inactividad planificado, tiempo de inactividad no planificado y tiempo.
El tiempo dedicado a capacitar, administrar, operar, aprovisionar, solucionar problemas y actualizar son costos importantes y con demasiada frecuencia no se tienen en cuenta. Y eso no incluye cómo el rendimiento de la aplicación en la nube afecta otros costos, como la productividad de los empleados, los ingresos, el tiempo de comercialización de los productos, el análisis y el tiempo de IA para obtener información procesable.
Advertencias para la diferenciación y elección del tipo de almacenamiento
El almacenamiento continúa evolucionando. Así como existen sistemas de almacenamiento puro para el almacenamiento de bloques, archivos y objetos, también existen sistemas de almacenamiento híbridos. Estos sistemas proporcionan bloque, archivo, archivo paralelo y objeto; o bloque, archivo y objeto; o simplemente archivar y objetar en un solo sistema de almacenamiento. Los proveedores de servicios de nube pública también tienden a proporcionar bloques, archivos y objetos en sus servicios de almacenamiento.
Algunos sistemas de almacenamiento convergente enfatizan un tipo de almacenamiento y comprometen a los demás. Además, algunos tienen una escalabilidad limitada. Asegúrese de que el sistema de almacenamiento elegido admita los requisitos actuales de la aplicación en la nube y continúe haciéndolo en el futuro previsible.
Además, no asuma que el almacenamiento de aplicaciones en la nube se limita al almacenamiento proporcionado por el proveedor de servicios de nube pública. Muchos proveedores de almacenamiento tienen servicios "adyacentes a la nube" en los que pueden colocar sus sistemas en el mismo lugar o muy cerca del proveedor de servicios de nube pública; se vinculan a través de un conducto de 10 Gbps de alto rendimiento. Además, la mayoría de los proveedores de almacenamiento tienen programas de suscripción elásticos PAYG que reflejan las tarifas de almacenamiento en la nube, pero con más rendimiento y servicios de almacenamiento.
Investigue más sobre Almacenamiento en la nube
-
![]()
Cinco consejos para mejorar la eficiencia del almacenamiento de datos
-
![]()
Gestión de almacenamiento de datos: ¿Qué es y por qué es importante?
Por: Paul Crocetti
-
![]()
Plataformas de almacenamiento de IA satisfacen las necesidades de ML y análisis de datos
-
![]()
Comprender los usos de blockchain en los centros de datos
Por: Jacob Roundy



