Wie man Predictive Modeling mit Machine Learning realisiert
Machine Learning ist ein unschätzbares Werkzeug zur Lösung von Geschäftsproblemen. Im Zusammenhang mit Predictive Analytics sollte man verschiedene Faktoren berücksichtigen.
Machine Learning wird verwendet, um prädiktive Algorithmen zu entwickeln – von Börsenprognosen über Werbung bis hin zu Vorhersagen, wann Produktionsmaschinen wahrscheinlich ausfallen.
Bei so vielen möglichen Anwendungen ist es kein Wunder, dass Führungskräfte wollen, dass ihre IT-Teams mit Machine-Learning-Projekten starten. Viele Machine-Learning-Anwender warnen aber davor, dass die Technologie nicht die Lösung für jedes Problem ist.
Wann man Machine Learning einsetzt, um Predictive-Algorithmen zu entwickeln, und wie man diese zum Laufen bringt, sind häufige Fragen, mit denen sich Nick Patience, Mitbegründer und Research Vice President bei 451 Research, beschäftigen muss. Er erklärt, dass es vier Komponenten gibt, die man benötigt, bevor man in Machine Learning für Predictive Modeling einsteigt:
einen ausgewählten Algorithmus, mit dem gearbeitet werden soll;
eine große Menge an guten Daten, die nicht isoliert sind;
Compute-Ressourcen, hauptsächlich in der Cloud; und
ein Team mit den richtigen Fähigkeiten.
Machine-Learning-Voraussetzungen
Maschinelles Lernen funktioniert nur, wenn man das Geschäftsproblem und die etablierten Regeln versteht. Wenn man diese beiden Dinge hat, weiß man, dass der betreffende Prozess wertvoll ist, da er hart codiert wurde. „Geschäftsregeln sind allerdings im Laufe der Zeit oft zu starr, so dass man sie flexibler gestalten muss“, sagt Patience.
„Es ist wichtig, zu Beginn eines Projekts klare Erfolgskriterien festzulegen und etwas auszuwählen, das mit hinreichender Wahrscheinlichkeit erfolgreich sein wird.“
William MarkSRI International
Ein großer Teil der Machine-Learning-Daten wird in der Cloud gespeichert, so dass Unternehmen wissen müssen, ob sie ihre Daten außerhalb ihrer eigenen Rechenzentren speichern wollen. „Andernfalls wird die Investition in eine lokale Infrastruktur enorm sein“, sagt der Analyst.
Ein weiterer wichtiger Faktor ist, dass die Daten, die für die Analyse mit einem prädiktiven Algorithmus bestimmt sind, nicht in verschiedenen proprietären Systemen gespeichert werden können. Sie müssen integriert werden, also muss es einen Datenaufbereitungsprozess geben. Hier kommen Hadoop Data Lakes, Spark und andere Big-Data-Plattformen sowie Data Warehouses ins Spiel.
Man muss auch sicherstellen, dass man nicht nur Daten und Plattformen integriert, sondern auch Fachleute, die wertvolle Informationen und Fähigkeiten in das Data-Science-Team einbringen, sagt David Ledbetter, Data Scientist am Children's Hospital Los Angeles.
„Die Machine Learning Community grenzt sich oft selbst aus und denkt, dass sie alle Probleme allein lösen kann, doch spezielle Fachleute bringen einen Mehrwert", sagt Ledbetter während einer Podiumsdiskussion auf der AI World Conference & Expo in Boston im Dezember 2018. „Jedes Mal, wenn wir uns mit dem klinischen Team treffen, erfahren wir etwas darüber, was mit den Daten passiert.“
Machine-Learning-Algorithmen und -Ergebnisse
Das Projektteam mit seinen unterschiedlichen Fähigkeiten muss auch gute und schlechte Ergebnisse basierend auf dem Geschäftsproblem, das diese mit einem prädiktiven Algorithmus zu lösen versuchen, identifizieren.
„Es ist wichtig, zu Beginn eines Projekts klare Erfolgskriterien festzulegen und etwas auszuwählen, das mit hinreichender Wahrscheinlichkeit erfolgreich sein wird“, sagt William Mark, President von SRI International, einem Forschungs- und Entwicklungsunternehmen, das KI-Projekte betreut. „Dies erfordert eine Diskussion mit technischen Experten, um ein Problem zu definieren, das mit hinreichender Wahrscheinlichkeit zu lösen ist.“
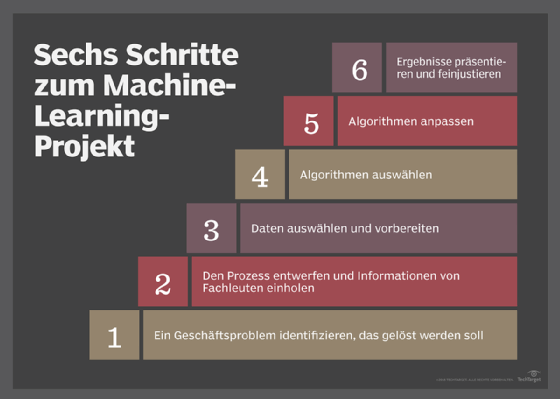
Abbildung 1: Sechs Schritte zum Machine-Learning-Projekt
Ein weiterer kritischer Aspekt ist die mögliche Auswirkung auf die Benutzererfahrung sowie die Kommunikation mit den Geschäftsführern, wie die Daten zu interpretieren sind, die sich aus einem prädiktiven Algorithmus ergeben.
„Da ist vieles noch nicht durchdacht“, sagt Patience. „Stellen Sie sich vor, Sie betrachten ein Lead-Scoring oder eine Predictive-Anwendung in einem Verkaufsautomatisierungsprozess und erhalten 78 Prozent als Wert auf ihrem Bildschirm. Das ist dann ein Wert für diesen speziellen Kunden, und Sie müssen sicherstellen, dass der Benutzer versteht, was er mit diesen Daten macht. Es ist toll, all diese intelligenten Daten produzieren zu können, aber man muss sich Gedanken über die Auswirkungen auf die Benutzerfreundlichkeit machen.“
Die Wahl des richtigen Machine-Learning-Algorithmus ist entscheidend – und es gibt viel zu beachten, da die meisten davon Open Source sind. Im Bereich des überwachten Machine Learning kann man aus Klassifizierungsalgorithmen auswählen, darunter Support Vector Machines, Nearest Neighbor, Naive Bayes und Diskriminanzanalyse, oder Regressionsalgorithmen wie Entscheidungsbäume und neuronale Netze.