
iaremenko - stock.adobe.com
Was Datenmodellierung und Datenarchitekturen unterscheidet
Datenmodellierer und Datenarchitekten haben unterschiedliche Aufgaben, die sich jedoch ergänzen. Beide unterstützen Unternehmen dabei, den Geschäftswert von Daten zu erschließen.

Die potenziellen Vorteile des Cloud Computing veranlassen leitende IT- und Unternehmensverantwortliche dazu, ihre Datenstrategie zu überdenken. Dabei überlegen sie, wie die Migration von Daten und Anwendungen in die Cloud die Modernisierung einer Datenarchitektur fördern kann.
In der Vergangenheit wurde das Konzept der Datenorganisation und -architektur in der Regel von der IT-Abteilung übernommen. Doch mit dem gestiegenen Bewusstsein für den geschäftlichen Wert von Daten wächst auch die Erkenntnis, dass eine effektive Datenstrategie Einfluss darauf hat, wie Transaktions- und Betriebsdaten dazu beitragen, Analyse-Anwendungen voranzutreiben, die zu einer vernünftigen Entscheidungsfindung und profitablen Ergebnissen führen.
Diese verstärkte Aufmerksamkeit wirft Fragen zu den verschiedenen Aspekten der Organisation und Verwaltung von Daten auf, insbesondere zur Datenmodellierung und zur Datenarchitektur. Wir untersuchen im Folgenden den Unterschied zwischen Datenmodellierung und Datenarchitektur, die Beziehung zwischen Datenmodellierung und Datenarchitektur als Teil des Datenmanagementprozesses und die verschiedenen Rollen von Datenmodellierern und Datenarchitekten.
Grundlagen der Datenmodellierung
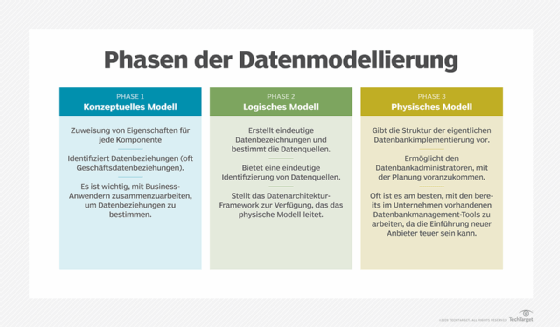
Ein Datenmodell ist eine abstrakte Darstellung der realen Entitäten, die innerhalb der Geschäftsumgebung eines Unternehmens zusammenwirken. Es stellt Dateneinheiten, ihre Attribute und die Beziehungen zwischen diesen Einheiten dar. Es gibt drei Arten von Datenmodellen: konzeptuelle, logische und physische.
Konzeptuelles Datenmodell. Dieses Modell zeigt eine Übersicht über die Daten, die das Unternehmen zur Unterstützung der Geschäftsprozesse verwendet. Obwohl dieses Modell die konzeptuellen Objekte darstellt, die von der Organisation verwendet werden, ist es im Allgemeinen nicht mit einer bestimmten Anwendung oder einem Datenbankmanagementsystem (DBMS) verknüpft. Vielmehr soll es den gesamten Informationsbedarf des Unternehmens erfassen. Das konzeptuelle Datenmodell wird zur Kommunikation mit dem Unternehmen verwendet, um sicherzustellen, dass die Anforderungen an die Informationsverarbeitung erfüllt werden, zum Beispiel die Definition konzeptueller Entitäten wie Kunde, Produkt und Standort sowie die Beziehungen zwischen diesen Entitäten: Ein Kunde, der an einem Ort lebt, hat ein Produkt gekauft.
Logisches Datenmodell. In diesem Modell werden die Merkmale, Attribute und Beziehungen zwischen den verschiedenen Entitäten detailliert beschrieben. Es bietet die technische Perspektive der im konzeptuellen Modell beschriebenen Datenobjekte mit der Definition spezifischer Attribute jeder Entität, zum Beispiel die Verknüpfung von Attributen eines Kunden, wie Nachname, Vorname und Kundennummer, sowie die Verknüpfung eines Kunden mit einem bestimmten Wohnort, der die Attribute Straße, Stadt, Bundesland und Postleitzahl umfasst.
Physisches Datenmodell. Dieses Modell ist spezifisch für die Anwendung und das Storage Framework, welches für diese Daten verwendet wird. Für jede modellierte Entität listet das physische Datenmodell die Datenelemente, ihre Datentypen, Längen und andere Merkmale auf, die für das zugrunde liegende Datenbankmanagementsystem oder die alternative Speicherumgebung relevant sind.
Aufgaben eines Datenmodellierers
Datenmodelle werden von Datenmodellierern entwickelt und verfeinert, die mit den Nutzern der Geschäftsdaten zusammenarbeiten und deren Anforderungen erfragen, um die konzeptuellen, logischen und physischen Datenmodelle iterativ zu verfeinern. Datenmodellierer arbeiten mit Entwicklern zusammen, um die von der entwickelten Anwendung implementierten Geschäftsprozesse zu verstehen und die beste Darstellung für die Daten zu finden, die diese Anwendung unterstützen. Zu den Aufgaben eines Datenmodellierers gehören:
- Kontaktaufnahme mit den Geschäftsanwendern, um deren Informationsbedarf zu ermitteln.
- Zusammenarbeit mit den Anwendungsentwicklern, um die implementierten Geschäftsprozesse zu verstehen.
- Überprüfung des Geschäftsprozesses und Konzeptualisierung der Entitäten, die innerhalb des Geschäftsprozesses interagieren.
- Bestimmen, wie die verschiedenen Entitäten miteinander in Beziehung stehen und Entwicklung von Beziehungsdiagrammen, die die Verbindungen zwischen den Entitäten darstellen.
- Identifizieren der Merkmale und Eigenschaften jeder Entität und Sicherstellung, dass die Entitäten innerhalb des Modells unterschieden werden können.
- Entwicklung eines logischen Datenmodells und dessen Validierung, um sicherzustellen, dass es den Anforderungen der Geschäftsanwendung und ihrer Benutzer entspricht.
- Umwandlung der logischen Darstellung in eine physische Darstellung und Zusammenarbeit mit Datenbankadministratoren zur Instanziierung und Verwaltung der Daten.
- Optimierung des Modells, um eine vorhersehbare Leistung zu gewährleisten.
- Pflege der Metadaten, die das Datenmodell, seine Struktur und Semantik beschreiben.
Grundlagen der Datenarchitektur
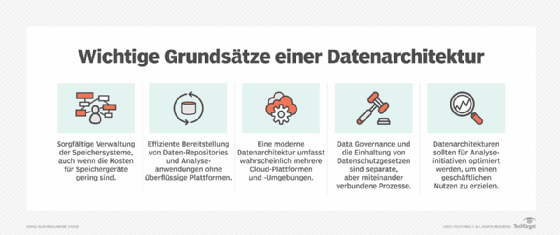
Laut dem Guide to the Data Management Body of Knowledge von DAMA International umfasst die Datenarchitektur Spezifikationen zur Beschreibung des bestehenden Zustands, zur Definition von Datenanforderungen, zur Steuerung der Datenintegration und zur Kontrolle der Datenbestände, wie sie in einer Datenstrategie festgelegt sind. Im Wesentlichen umfasst die Datenarchitektur die folgenden Strategien und Taktiken zur Verwaltung der End-to-End-Datenlebenszyklen eines Unternehmens, welche die operativen Geschäftsprozesse und die analytische Entscheidungsfindung informieren und vorantreiben:
- Die Datenauswahl konzentriert sich darauf, welche Datensätze innerhalb der Organisation erstellt und welche von außerhalb des Unternehmens erworben werden.
- Die Dateninfrastruktur umfasst die Bewertung und Auswahl von Datenplattformen und der zugehörigen Datenmanagement-Tools und -diensten, die Implementierung von Systemen in lokalen Rechenzentren und in der Cloud sowie die Netzwerkkonfiguration.
- Bei der Datenübernahme und -integration geht es darum, Daten aus externen Quellen aufzunehmen, sie anhand definierter Datenqualitätskriterien zu validieren, sie in nutzbare Formate umzuwandeln und sie mit Daten aus internen Geschäftsanwendungen zu integrieren.
- Die Datenspeicherung umfasst die Verwendung von relationalen Datenbankmanagementsystemen (RDBMS) für strukturierte Daten, Textdateien und Dateien mit kommagetrennten Werten, halbstrukturierte und unstrukturierte Daten, die in NoSQL-Datenbanken verwaltet werden, Big Data Frameworks und Cloud-Objektspeicherdienste.
- Datennutzung identifiziert die verschiedenen Datenkonsumenten, bewertet ihre Anforderungen und unterstützt ihre Nutzungsszenarien.
- Der Datenzugriff konzentriert sich auf die Zugriffsmethoden wie direkte Abfragen, Extrakte und Datendienste.
- Die Datenanalyse und -präsentation umfasst Methoden zur Datenorganisation für Berichts- und Analysezwecke, wie zum Beispiel die Verwendung eines Data Warehouse und Visualisierungs-Tools für Endbenutzer.
- Der Datensicherheit umfasst Sicherheitsvorkehrungen an der Peripherie, Verschlüsselungsmethoden sowie rollen- und attributbasierte Zugriffskontrollen.
- Data Governance und Stewardship überwachen die Einhaltung von Modellen, Regeln und definierten Richtlinien für die Sammlung, Verwaltung und Nutzung von Unternehmensdaten.
Aufgaben eines Datenarchitekten
Die Rolle des Datenarchitekten ist viel umfassender als die des Datenmodellierers. Die Aufgabe umfasst eine Reihe von Verantwortlichkeiten im Zusammenhang mit dem Umfang der Datenstrategie eines Unternehmens, die eine Kombination aus lokalen Plattformen und Cloud-Daten- und Anwendungsdiensten umfasst. Zu den Aufgaben eines Datenarchitekten gehören:
- Skizzieren der Datenstandards und -prinzipien, die für die Datenverwaltung in verschiedenen Datenumgebungen gelten, einschließlich hybrider On-Premises- und Multi-Cloud-Umgebungen.
- Festlegung der zu verwendenden Datenmanagement-Frameworks, einschließlich RDBMS für die transaktionale und operative Verarbeitung, Data Warehouses, Data Marts und Data Lakes für die analytische Verarbeitung sowie Tools für die Datenabfrage und -visualisierung durch Endbenutzer.
- Berücksichtigung der betrieblichen Anforderungen, Leistungserwartungen und Kosten sowie Entwicklung einer Strategie für die Verwaltung von Daten und Anwendungen.
- Implementierung eines Datenkatalogs zur Auflistung der Unternehmensdaten mit ihren Merkmalen, dem Standort dieser Daten, den Zugriffskontrollen und der Klassifizierung der Datensensibilität.
- Beaufsichtigung des Einsatzes von Datenmodellierungs-Tools und -Technologien, Anleitung der Datenmodellierer bei der Entwicklung ihrer Modelle, Beaufsichtigung der Datenmodellierungsprozesse und Pflege eines Metadaten-Repository zur Erfassung der Datenintelligenz über die Unternehmensdatenlandschaft.
- Beaufsichtigung der Auswahl und Implementierung von Datenmanagement-Tools, die mit den Entwicklungsprozessen und -methodiken in Einklang stehen.
- Entwicklung und Pflege einer Referenzarchitektur, die die Spezifikation von Datendomänen enthält, die in verschiedenen Geschäftsanwendungen und Unternehmensbereichen verwendet werden. Dieses Framework trägt zur Entwicklung einer Strategie für die Verwaltung von Unternehmensstammdaten bei, um die Darstellung von Domänen zu vereinheitlichen und unnötige Datenreplikationen zu reduzieren.
- Dokumentation, wie Daten von Ursprungs- und Erfassungspunkten über Systeme und Anwendungen hinweg fließen, und Überwachung der Entwicklung, Verwaltung und Überwachung von Datenpipelines.
- Umreißen von Datenintegrationstechniken und -prozessen sowie Auswahl von Tools für die Implementierung und Überwachung von Integrationsbemühungen.
- Spezifizierung von Datenzugriffsmethoden und Entwerfen von Datendiensten zur Unterstützung des nachgelagerten Self-Service-Zugriffs für Datenwissenschaftler und -analysten.
- Dokumentieren von Datenqualitätsregeln und -erwartungen sowie Auswahl und Implementierung von Tools für die Verwaltung und Berichterstattung über die Einhaltung der Datenqualitätsanforderungen.
- Definition von Datenschutzrichtlinien und Auswahl der richtigen Technologien zur Umsetzung der Richtlinien.
- Überwachung, Prüfung und Berichterstattung über die Einhaltung interner Datenstandards, extern definierter Vorschriften und Richtlinien sowie Leistungserwartungen.
Datenmodellierung und Datenarchitektur: Unterschiedlich und doch komplementär
Es gibt einige Unterschiede zwischen Datenmodellierung und Datenarchitektur, die im Wesentlichen eine Mikroperspektive (Modellierung) und eine Makroperspektive (Architektur) widerspiegeln.
Die Datenmodellierung konzentriert sich auf die Details, den Inhalt und die Struktur aller Unternehmensdaten. Das Ziel ist die Darstellung von Geschäftskonzepten, ihren Beziehungen und den Wertedomänen, die die Attribute der einzelnen Entitäten füllen können.
Die Datenarchitektur konzentriert sich auf die globale Ebene der Datenplattformen und -Tools sowie auf Standards und Richtlinien, Prozesse und die Aufsicht über die Verwaltung der Unternehmensdaten. Ziel ist es, einen soliden Rahmen für die Verarbeitung, Organisation und Nutzung von Unternehmensdaten zu schaffen.

Datenmodellierung und Datenarchitektur ergänzen sich dabei gegenseitig. Gut definierte Datenmodelle bilden nicht nur die Grundlage für die Ausarbeitung von Richtlinien für die Speicherung, den Zugriff und den Schutz von Unternehmensdaten, sondern beeinflussen auch die Auswahl von Plattformen, Tools und Technologien durch den Datenarchitekten. Eine etablierte Datenarchitektur vereinfacht die Arbeit des Datenmodellierers, insbesondere dann, wenn gute Tools und Best Practices zur Verfügung stehen, die den Rahmen für die Definition und Zuordnung von Unternehmensdatenkonzepten bilden.
Ein integrativer Ansatz für Datenmodellierung und Datenarchitektur zeigt, dass ein Unternehmen einen hohen Reifegrad im Datenmanagement erreicht hat.







