
peterschreiber.media - stock.ado
Schlüsselfaktoren für eine optimale Data-Lake-Integration
Von der Technologie bis zu Governance: Eine Data-Lake-Implementierung besteht aus vielen Schritten. Erfahren Sie, welche Faktoren für eine Implementierungsstrategie wichtig sind.

Data-Lake-Plattformen werden für Unternehmen jeder Größe immer attraktiver. Dafür sind mehrere Entwicklungen verantwortlich. Abgesehen von den allgemeinen Business-Treibern führte vor allem die Fähigkeit der Cloud, riesige Mengen an Speicher- und Verarbeitungsleistung zu immer niedrigeren Preisen anzubieten, zum Wachstum von Data Lakes.
Entsprechend befinden sich Data-Lake-Implementierung weiterhin im Aufwind. Ein Analysebericht von Markets and Markets prognostiziert, dass der Data-Lake-Markt pro Jahr durchschnittlich um 26 Prozent wachsen und bis 2024 20,1 Milliarden US-Dollar an Umsatz erreichen wird.
Eine Data-Lake-Implementierung ist aber kein Kinderspiel. Wenn Ihr Unternehmen einen Data Lake einführen will, sollten Sie einige Dinge beachten.
Was ist ein Data Lake?
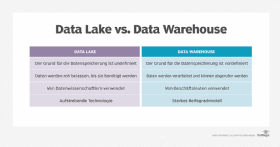
Das beste Verständnis für Data Lake ergibt sich aus einem Vergleich mit Data Warehouses. Obwohl sowohl Data Warehouses als auch Data Lakes zum Speichern großer Datenmengen verwendet werden, unterscheiden sich beide Konzepte erheblich.
In Data Lakes können Unternehmen die gespeicherten Informationen auf vielfältige Weise nutzen. Um sich für die Aufnahme in einen Data Lake zu qualifizieren, benötigen die Datenquellen keinen vordefinierten Zweck. Die Strategie für eine Data Lake-Implementierung besteht darin, Daten von praktisch jedem System, das Informationen generiert, aufzunehmen und zu analysieren.
In Data Warehouses hingegen werden Daten immer nur für einen bestimmten Zweck aufgenommen. Dazu führen Data-Warehouse-Spezialisten häufig im Vorfeld Analysen durch. Für die Aufnahme von Daten verwenden Data Warehouses vordefinierte Schemata. In einem Data Lake wenden Analysten Schemata hingegen erst nach Abschluss des Aufnahmevorgangs an.
Data Lakes speichern Daten immer in Rohform. Infolgedessen ist die Datenaufnahme ein unkomplizierter Prozess. In einem Data Warehouse hingegen werden Daten während der Aufnahme stark verarbeitet, um sicherzustellen, dass sie dem Schema und seinem vordefinierten Zweck entsprechen.
Data Lakes sind auf die Aufnahme strukturierter, semistrukturierter und unstrukturierter Daten spezialisiert. Sie bieten – zusätzlich zu Batch Loads – auch Mechanismen für die einfache Integration von Streaming-Daten. Data Warehouses können zwar prinzipiell viele verschiedene Arten von Daten akzeptieren, nehmen in der Regel aber nur strukturierte Daten über Batch Loads auf.
Der erste Schritt
Der erste Schritt bei der Implementierung von Data Lakes besteht darin, sich über Data-Lake-Architekturen, -Plattformen, -Produkte und -Workflows zu informieren. Das geht am besten über Anbieter-Websites oder Literatur.
Wie bei jeder Produktbewertung sollten Sie eine gründliche Analyse der konkurrierenden Angebote durchführen. Hier ist eine Starterliste mit Bewertungskriterien, die Ihnen bei Ihrer Analyse helfen:
Technologie. Apache Hadoop und seine Suite unterstützender Produkte gehören für viele Unternehmen zu den Favoriten. Inzwischen ist aber eine wachsende Anzahl von Alternativen verfügbar. Viele Anbieter, die Hadoop für ihre Data-Lake-Produkte verwenden, bieten eigene Anpassungen und Edge-Produkte an. Diese sollen die Verwaltung und Analyse rationalisieren und vereinfachen.
Zur Verfügung steht eine breite Palette von Plattformen, darunter Amazon Data-Lake-Lösungen, Microsoft Azure Data Lake, Google Data Lakes, Snowflake for Data Lakes und Oracle Data Lake.
Sicherheit und Zugangskontrolle. Data Lakes bergen einen wertvollen Informationsschatz. Wie jeden Unternehmensspeicher sollten Sie auch Data Lakes vor unbefugtem Zugriff schützen.
Datenaufnahme. Bei der Datenaufnahme gibt es mehrere Fragen zu klären. Nimmt die Plattform strukturierte, semistrukturierte und unstrukturierte Daten einfach und schnell auf? Ist sie in der Lage, Datenströme, Micro Batch und Mega Batch Data Loads effizient einzulesen?
Verwaltung von Metadaten. Big-Data-Spezialisten verwenden Metadaten, um Datensätze im Data Lake zu suchen, zu identifizieren und besser zu verstehen. Wie erfasst und speichert die Plattform Metadaten?
Datenverarbeitung, Leistung und Skalierbarkeit. Welche Tools und Prozesse bietet die Plattform den Benutzern für die Interaktion mit den Daten? Auf welche Weise erfolgt die Datenexploration? Welche Hintergrundprozesse werden während des täglichen Betriebs ausgeführt? Wie schnell sind diese Prozesse und werden sie skalierbar sein, um Ihre Workload-Anforderungen zu erfüllen?
Management und Überwachung. Bietet die Plattform eine starke Benutzeroberfläche für die Systemadministration und -überwachung? Welche Workload-Management-Funktionen stellt sie bereit?
Data Governance. Verfügt die Plattform über Mechanismen, um sicherzustellen, dass die Daten konsistent und zuverlässig sind? Gibt es die Möglichkeit, Sandbox-Umgebungen zu erstellen, in denen Benutzer mit Daten experimentieren können, ohne den Inhalt des Data Lakes auf irgendeine Weise zu beeinflussen?
Datenanalyse und Zugänglichkeit. Welche Mechanismen bietet die Plattform zur Analyse der Daten? Ermöglicht sie die einfache Einbindung von Machine Learning? Welche Funktionen für die Datenanalyse stellt sie bereit? Lassen sich problemlos Analyse-Tools von Drittanbietern integrieren?
Strategien zur Kostenberechnung. Wie stellt Ihnen der Anbieter die Kosten in Rechnung?
Implementierung von Data Lakes
Nach der Auswahl der Plattform besteht der nächste Schritt darin, die organisatorische Infrastruktur sowie die Prozesse und Verfahren zum Laden, Verwalten und Analysieren von Daten im Data Lake aufzubauen.
Dies sind die wichtigsten Schritte einer Data-Lake-Implementierungsstrategie:
- Informieren Sie sich über das Fachwissen, das Sie benötigen, um die Plattform effektiv zu unterstützen. Wie viele komplexe Technologien haben Data Lakes eine steile Lernkurve. Stellen Sie erfahrenes Personal ein und schulen Sie internes Personal. Ihr Unternehmen muss neue Organisationsrollen und Berichtsstrukturen für die Implementierung von Data Lakes definieren.
- Um eine durchdachte Strategie und ein durchdachtes Design für die Implementierung eines Data Lakes umzusetzen, muss Ihr Unternehmen einen traditionellen Projektplan mit Zielen, Meilensteinen und zugewiesenen Aktionselementen entwickeln. Sie müssen die Kriterien festlegen, anhand derer der Erfolg des Data-Lake-Projekts bewertet werden soll. Entwerfen Sie das System so, dass es die Self-Service-Datenanalyse fördert. Sie sollten auch Standards für die Datenklassifizierung zur Speicherung und Archivierung von Daten entwickeln.
- Nahezu alle von einem Unternehmen generierten Daten können in einen Data Lake aufgenommen werden. Die Herausforderung liegt in der richtigen Priorisierung. Ein guter Ansatz ist es, die Quelle, aus der die Daten generiert werden, zu bewerten und ihre Bedeutung für das Unternehmen zu ermitteln.
- Sie sollten festlegen, ob die Informationen gerade analysiert werden und auf welcher Ebene die Analyse stattfindet. Hochgradig analysierte Daten sind zwar immer noch eine potenzielle Quelle für die Aufnahme. Sie haben jedoch möglicherweise eine geringere Bedeutung als Daten aus einem System, das nicht ausgewertet wird.
- Entwickeln, implementieren und erzwingen Sie Strategien zur Data Governance, um sicherzustellen, dass die Daten sicher, vollständig, konsistent und genau sind.
- Legen Sie Standards für die Datenexploration, das Experimentieren und die Analyse fest. Data Scientists sollten einem standardisierten, aber flexiblen Prozess folgen, um die Daten auszuwerten. Sie sollten auch die Anwendungsfälle identifizieren, die den größten Nutzen für das Unternehmen generieren. Mögliche Ziele für die Daten sind andere Business-Intelligence-Plattformen sowie neue und vorhandene Geschäftsanwendungen.







