
Getty Images
NoSQL-Datenbanktypen erklärt: spaltenorientierte Datenbanken
Erfahren Sie mehr über die Einsatzmöglichkeiten spaltenorientierter NoSQL-Datenbanken, das zugehörige Datenmodell, Data Warehouses und die Vorteile der Abfragefunktionen.

Organisationen benötigen Datenbanken, die den steigenden Anforderungen an die Datenspeicherung gerecht werden und die Datenvielfalt effizient bewältigen können. Spaltenorientierte Datenbanken erfüllen diese Zwecke
Spaltenorientierte Datenbanken sind eine Art von NoSQL-Datenbank, die für hochgradig analytische, komplexe Abfrageaufgaben entwickelt wurde. Im Gegensatz zu relationalen Datenbanken speichern spaltenorientierte Datenbanken ihre Daten nach Spalten und nicht nach Zeilen. Diese Spalten werden zu Untergruppen zusammengefasst.
Die Datenbank hat keine festen Schlüssel- und Spaltennamen. Spalten innerhalb derselben Spaltenfamilie oder eines Spaltenclusters können eine unterschiedliche Anzahl von Zeilen aufweisen und verschiedene Datentypen und Namen aufnehmen.
Spaltenorientierte Datenbanken sind für große Datenmodelle, wie zum Beispiel Data Warehouses, oder wenn eine hohe Leistung oder die Verarbeitung intensiver Abfragen erforderlich ist, effektiv.
Funktionsweise spaltenorientierter Datenbanken
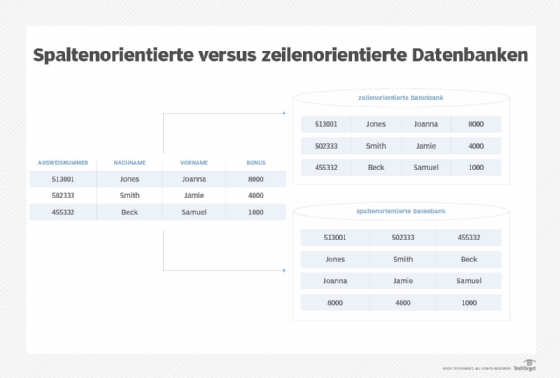
Relationale Datenbanken haben ein festgelegtes Schema und funktionieren als Tabellen mit Zeilen und Spalten. Breitspaltige Datenbanken haben auch Zeilen und Spalten, die nicht innerhalb einer Tabelle festgelegt sind; sie haben ein dynamisches Schema. Jede Spalte wird separat gespeichert. Verwandte Spalten bilden Spaltenfamilien und die Datenbank speichert Spaltenfamilien separat.
Der Zeilenschlüssel ist die erste Spalte in jeder Spaltenfamilie und dient als Kennung einer Zeile. Jede nachfolgende Spalte hat einen Spaltenschlüssel (Namen), der Spalten innerhalb von Zeilen identifiziert und Spaltenabfragen ermöglicht. Der Wert und der Zeitstempel folgen nach dem Spaltenschlüssel und hinterlassen eine Spur, wann die Daten eingegeben oder geändert wurden.
Nicht jede Spalte einer Spaltenfamilie hat die gleiche Anzahl von Zeilen. Sie können zwar den gleichen Namen haben, aber die Datenbank enthält jede Spalte innerhalb einer Zeile und erstreckt sich nicht über alle Zeilen.
Jede Spalte einer relationalen Datenbank hat die gleiche Anzahl von Zeilen, aber einige der Felder haben einen Nullwert oder scheinen leer zu sein. In breitspaltigen Datenbanken existieren leere Zeilen für eine bestimmte Spalte nicht.
Die Spaltenfamilien befinden sich in einem Schlüsselbereich. Jeder Schlüsselbereich enthält einen vollständigen NoSQL-Datenspeicher und hat eine ähnliche Rolle oder Bedeutung wie ein Schema für eine relationale Datenbank. NoSQL-Datenspeicher haben jedoch keine festgelegte Struktur, sodass Schlüsselbereiche eine schemalose Datenbank darstellen, die das Design eines Datenspeichers und einen eigenen Satz von Attributen enthält.
Arten von spaltenorientierten Datenbanken
Spaltenorientierte Datenbanken haben zwei Hauptfamilientypen:
- Die Standard-Spaltenfamilie ähnelt einer Tabelle. Sie enthält ein Schlüssel-Wert-Paar, wobei der Schlüssel der Zeilenschlüssel ist und die Werte ihre Namen als Kennungen verwenden.
- Die Super-Spaltenfamilie stellt ein Array von Spalten dar. Jede Super-Spalte hat einen Namen und einen Wert, der die Super-Spalte mehreren verschiedenen Spalten zuordnet. Die Datenbank fasst verwandte Super-Spalten unter einer einzigen Zeile zu Super-Spaltenfamilien zusammen.
Vorteile spaltenorientierter Datenbanken
Organisationen, die mit Big Data arbeiten und in Analysen investieren, sollten die Stärken spaltenorientierter Datenbanken in Betracht ziehen. Sie zeichnen sich durch die effiziente Speicherung und Abfrage großer Datensätze aus folgenden Gründen aus:
- Skalierbarkeit. Der Hauptvorteil einer spaltenorientierten Datenbank ist die Fähigkeit, große Datenmengen zu verarbeiten. Je nach Umfang der Datenbank kann sie Hunderte verschiedener Maschinen abdecken. Spaltenorientierte Datenbanken unterstützen die massiv-parallele Verarbeitung, bei der viele Prozessoren gleichzeitig an denselben Berechnungen arbeiten.
- Komprimierung. Die Komprimierung großer Datenmengen spart Speicherplatz.
- Reaktionsschnell. Die Ladezeit ist minimal und spaltenorientierte Datenbanken führen Abfragen schnell aus, was sie für große Datenmengen und Analysen praktisch macht.
- Aggregationsleistung. Spaltenorientierte Datenbanken können große Datenmengen in Spalten effizient scannen und aggregieren. Aggregationen wie Durchschnittswerte und Summen sind schneller, da die Datenbank-Engine nur die erforderlichen Spalten und nicht ganze Zeilen liest. Aggregationen, bei denen vor der Aktualisierung eines Werts die gesamte Spalte gelesen werden muss – wie zum Beispiel eine eindeutige Zählung oder Sortierung – sind in der Regel viel schneller als zeilenorientierte Datenbanken.
- Flexibilität. Im Allgemeinen sind spaltenorientierte Datenbanken für allgemeine Datenbankarbeiten weniger flexibel als zeilenorientierte Architekturen. Die spaltenorientierte Architektur ist jedoch in bestimmten Situationen anpassungsfähiger. So ist beispielsweise das Hinzufügen oder Entfernen von Spalten bei der Weiterentwicklung von Schemata im Allgemeinen einfacher als in einem zeilenbasierten System, da nur die betroffene Spalte geändert werden muss. In einer herkömmlichen Datenbank muss jede Datenzeile aktualisiert werden. Die Schemaflexibilität kann nützlich sein, wenn sich die Analyseanforderungen häufig ändern oder im Laufe der Zeit weiterentwickeln.
Nachteile spaltenorientierter Datenbanken
Spaltenorientierte Datenbanken haben mehrere Nachteile, mit denen Benutzer leben müssen. Neben potenziellen Sicherheitslücken haben sie Schwierigkeiten, Folgendes zu unterstützen:
- Online-Transaktionsverarbeitung. Spaltendatenbanken sind beim Online Transaction Processing (OLTP) nicht so effizient wie beim Online Analytical Processing (OLAP). Sie können Transaktionen analysieren, haben aber Schwierigkeiten, sie zu aktualisieren. Eine gängige Strategie besteht darin, die spaltenorientierte Datenbank die für die Geschäftsanalyse erforderlichen Daten enthalten zu lassen und die Daten in einer relationalen Datenbank im Backend zu speichern.
- Inkrementelles Laden von Daten. Spaltenorientierte Datenbanken können Daten schnell für die Analyse abrufen, selbst bei der Verarbeitung komplexer Abfragen. Inkrementelles Laden von Daten ist nicht unmöglich, aber spaltenorientierte Datenbanken führen dies nicht auf die effizienteste Weise aus. Sie müssen die Spalten durchsuchen, um die richtigen Zeilen zu identifizieren, und dann einen weiteren Scan durchführen, um die geänderten Daten zu finden, die überschrieben werden müssen.
- Zeilenspezifische Abfragen. Die Nachteile von spaltenorientierten Datenbanken laufen alle auf dasselbe Problem hinaus – die Verwendung des richtigen Datenbanktyps für die richtigen Zwecke. Zeilenspezifische Abfragen erfordern einen zusätzlichen Schritt, bei dem die Spalten durchsucht werden, um die Zeilen zu identifizieren und dann die abzurufenden Daten zu finden. Es dauert länger, einzelne Datensätze zu finden, die über mehrere Spalten verteilt sind, als auf gruppierte Datensätze in einer einzigen Spalte zuzugreifen. Häufige zeilenspezifische Abfragen können zu Leistungsproblemen führen, indem sie eine spaltenorientierte Datenbank verlangsamen, was dem Zweck der schnellen Bereitstellung von Informationen zuwiderläuft.
- Sicherheit. Spaltenorientierte Datenbanken sind etwas anfälliger für Sicherheitsprobleme als andere Datenbanktypen, da sie zur Leistungssteigerung auf Datenkomprimierung setzen – insbesondere bei häufig wiederholten Werten. Komprimierung kann mit Verschlüsselung in Konflikt stehen. Die Verschlüsselung ist möglicherweise weniger effektiv, wenn die Komprimierung zuerst erfolgt, da Muster in den komprimierten Daten möglicherweise erhalten bleiben. Wenn die Daten jedoch zuerst verschlüsselt werden, können die Leistungsvorteile der Komprimierung eingeschränkt werden. Ein mildernder Faktor für potenzielle Schwachstellen ist, dass die sensibelsten Daten, wie zum Beispiel eindeutige Kennungen, weniger wahrscheinlich effektiv komprimiert werden können.
Anwendungsfälle für spaltenorientierte Datenbanken
Spaltenorientierte Datenbanken bieten potenzielle Anwendungen in den Bereichen Data Warehouses, künstliche Intelligenz (KI) und maschinelles Lernen (ML):
- Data Warehouse. Die klassische Data-Warehouse-Architektur verbessert die Leistung von Aggregationen und analytischen Abfragen über historische Daten mit relationalen Datenbanken. Eine spaltenorientierte Datenbank verbessert die Effizienz, da sie nur die für eine Abfrage relevanten Spalten liest, wodurch der I/O-Overhead erheblich reduziert und Abfragen beschleunigt werden.
- Business Intelligence (BI). Auf dem Server laufen BI-Tools oft ähnlich wie Data Warehouses und bieten ähnliche Vorteile wie spaltenorientierte Datenbanken. Viele moderne BI-Anwendungen sind Desktop-Anwendungen für Daten- und Geschäftsanalysten. Die Komprimierung spaltenorientierter Architekturen ermöglicht die Speicherung und Verarbeitung großer Datenmengen im Arbeitsspeicher und bietet Analysefunktionen, die bisher nur auf leistungsstarken Servern verfügbar waren.
- Maschinelles Lernen (ML). Eine hervorragende Analyse-Performance ist ein allgemeiner Vorteil von ML, aber einige Szenarien profitieren von den Funktionen spaltenorientierter Architekturen. Beispielsweise ermöglichen spaltenorientierte Datenbanken eine effiziente Analyse von Trends und Mustern über bestimmte Spalten wie Zeitstempel und Metriken hinweg, da sie große Mengen sequenzieller Daten verarbeiten können. Sie können sich auf die Beziehungen zwischen bestimmten Datenspalten konzentrieren, was bei der Identifizierung von Anomalien hilft.
- Künstliche Intelligenz (KI). Die Datenarchitektur, die üblicherweise mit KI in Verbindung gebracht wird, ist eine Vektordatenbank. Spaltenorientierte Datenbanken können jedoch in wichtigen Phasen des Datenaufbereitungs-Workflows für KI eingesetzt werden. Dateningenieure erstellen häufig neue Datenmerkmale, mit denen KI-Systeme trainiert werden können. Beispiele hierfür sind die Berechnung von Durchschnitts-, Median-, Minimal- oder Maximalwerten oder von Verhältnissen zwischen Werten. Viele Datensätze enthalten zahlreiche fehlende Werte oder spärliche Daten. Spaltenspeicher arbeiten in solchen Szenarien außergewöhnlich gut.
- Internet der Dinge (Internet of Things, IoT). IoT-Geräte generieren kontinuierlich Datenströme, oft in strukturierten Formaten wie Sensorwerten für Temperatur, Luftfeuchtigkeit, Standort oder Gerätestatus. Jede Metrik kann eine separate Spalte in einer Datenbank sein, sodass spaltenorientierte Systeme eine natürliche Wahl sind.
Beispiele für spaltenorientierte Datenbanken
Die steigende Nachfrage nach leistungsstarken Analysen großer Datensätze erhöht die Nachfrage nach spaltenorientierten Datenbanken. Die Wahl zwischen Open-Source- und kommerziellen spaltenorientierten Datenbanken hängt oft vom Budget, den erforderlichen Funktionen, dem internen Fachwissen und den spezifischen Verwendungszwecken ab. Viele Organisationen verwenden eine Mischung aus beidem; sie können Open-Source-Tools für einige Anwendungen und kommerzielle Systeme für andere verwenden.
Hier sind einige Beispiele der beliebtesten Systeme, sowohl Open-Source- als auch kommerziell lizenzierte, die typischerweise für die häufigsten Anwendungsfälle verwendet werden. Die Tools wurden anhand von Erkenntnissen aus G2-Bewertungsrankings, Recherchen von IT Market Strategy und zusätzlicher Marktforschung von TechTarget ausgewählt. Diese nicht gerankte Liste ist in alphabetischer Reihenfolge.
Amazon Redshift ist eine vollständig verwaltete, Cloud-Spaltendatenbank, die von Organisationen häufig für Data Warehousing verwendet wird. Redshift ist für groß angelegte Analysen und Business-Intelligence-Anwendungsfälle gedacht. Es verarbeitet komplexe Abfragen über Datensätze im Petabyte-Bereich hinweg mithilfe von massiv paralleler Verarbeitung. Ein wesentlicher Vorteil von Redshift besteht darin, dass es sich nahtlos in das AWS-Ökosystem von Diensten und Anwendungen integrieren lässt und Hochgeschwindigkeitsabfragen, schnelle Datenkomprimierung, die die Speichergröße um bis zu 35 Prozent reduziert, und elastische Skalierung unterstützt. Amazon bietet eine nutzungsbasierte Bezahlung an, die kosteneffizient sein kann und dazu beiträgt, Redshift zu einem beliebten System für die Nutzung neben anderen Datenbanken zu machen. Es dient oft als kostengünstige Ablage für ältere, weniger häufig genutzte Daten in Data-Warehousing-, Berichts- und Analyseszenarien.
Apache Cassandra verfügt über lokale, Cloud- und Hybrid-Bereitstellungskonfigurationen. Die Open-Source-Lizenz bietet Community-Support über Planet Cassandra, das Ressourcen von monatlichen globalen Meetups bis hin zu regelmäßigen Onboarding-Meetings für neue Benutzer bietet. Der Lernaufwand für die Ersteinrichtung und Optimierung ist jedoch umfangreich. Das hoch skalierbare und fehlertolerante System kann große Datenmengen verarbeiten, die auf mehrere Knoten verteilt sind. Cassandra verfügt über einstellbare Konsistenzstufen, um den Kompromiss zwischen Daten, die auf allen Servern konsistent sind, oder Daten, die mit sehr geringer Latenz zur Verfügung stehen, individuell anzupassen. Es ist beliebt für IoT-Szenarien mit Streaming-Daten und seinen reduzierten Betriebskosten.
ClickHouse ist ein Open-Source-Spaltensystem, das ursprünglich vom russischen Internetunternehmen Yandex entwickelt wurde. Es zeichnet sich durch OLAP aus und verfügt über eine hochverfügbare, leistungsstarke Architektur für geschäftskritische Analysen in den Bereichen Echtzeitwerbung, Spot-Pricing und Telekommunikation. ClickHouse kann große Datensätze mit Echtzeit-Datenerfassung und schneller Abfrageleistung verarbeiten. Zu den Einschränkungen gehören das Fehlen einer nativen Volltextsuche und eine begrenztere Community und ein begrenzteres Ökosystem als bei Apache Cassandra, ein Nachteil von Open-Source-Software.
Microsoft Azure Cosmos DB ist eine Multi-Modell-Architektur, das heißt sie kann verschiedene Datenmodelle unterstützen, wie zum Beispiel Dokumenten-, Schlüsselwert- und Graphdatenbanken. Eine der wichtigsten und am häufigsten verwendeten Konfigurationen ist die spaltenorientierte. Die cloudbasierte Datenbank bietet mehrere APIs für Entwickler, darunter SQL, MongoDB und Cassandra. Um globale Anwendungen zu unterstützen, automatisiert Azure Cosmos DB die Replikation und verfügt über einstellbare Konsistenzstufen. Es ist eine beliebte Wahl für Webanwendungen, insbesondere für unternehmenskritische Anwendungen in mehreren Regionen.






