
vege - stock.adobe.com
NoSQL-Datenbanktypen erklärt: Graphdatenbank
NoSQL-Graphdatenbanken konzentrieren sich auf die Beziehungen zwischen Datenelementen. Der Datenbanktyp bietet verschiedene Vor- und Nachteile gegenüber relationalen Datenbanken.

Das Hauptziel von NoSQL-Datenbanken ist eine verbesserte Effizienz. Dies wird durch den Einsatz neuer Technologien und unkonventionelles Denken erreicht.
Ein Beispiel für die Anwendung neuer Technologien kann die Entscheidung für Lösungen sein, die mehr Speicherplatz benötigen. Früher haben wir uns mehr Gedanken über die Speicheranforderungen gemacht, aber in letzter Zeit ist dies aufgrund der deutlich gesunkenen Kosten für diese Ressource weniger wichtig geworden. Heute sind strengen Grenzen des SQL-Schemas eine größere Hürde.
Was ist eine Graphdatenbank?
Eine Graphdatenbank konzentriert sich ebenso sehr auf die Beziehungen zwischen Datenelementen wie auf die Daten selbst und ermöglicht so eine gezielte Datenspeicherung. Die Verwendung eines grafischen Datenmodells trägt positiv zur Visualisierung von Daten bei. Es wird in der Big-Data-Welt geschätzt, da es immer gut ist, die Daten vor sich schnell erfassen zu können.
Die Elemente
Basierend auf der Graphentheorie bestehen diese Datenbanken aus Knoten und Kanten. Knoten sind die Entitäten einer Graphdatenbank. Einfach ausgedrückt sind sie die Agenten und Objekte von Beziehungen und können als Antworten auf die Fragen Wer und Wen dargestellt werden.
Jede dieser Entitäten verfügt über eine eindeutige Kennung. Sie können auch Eigenschaften aufweisen, die aus Schlüssel-Wert-Paaren bestehen, und sie können mit oder ohne Metadaten gelabelt sein, die einem bestimmten Knoten in einer Domäne eine Rolle zuweisen. Es gibt auch eingehende und ausgehende Kanten. Stellen Sie sich diese als verschiedene Enden eines Pfeils vor, die Ihnen zeigen, wer der Agent und wer das Objekt einer Beziehung ist.
Kanten sind genauso wichtig wie Knoten, da sie wichtige Informationen enthalten. Sie stellen Beziehungen zwischen Entitäten dar. Eine SQL-Datenbank würde wahrscheinlich für jede Beziehungsklasse eine eigene Tabelle haben. Eine Graphdatenbank benötigt eine solche Vermittlung nicht, da sie ihre Entitäten direkt miteinander verbindet. Kanten haben auch eindeutige Kennungen und können, genau wie Knoten, neben dem definierten Typ, der Richtung und dem Start- und Endknoten auch andere Eigenschaften haben.
Graphdatenbankmodelle
Es gibt zwei gängige Graphdatenbankmodelle: Resource Description Framework (RDF) und Property-Graph (Labeled-Property-Graph). Sie haben Ähnlichkeiten, sind aber für unterschiedliche Zwecke konzipiert. Das eine Modell konzentriert sich auf die Datenintegration, das andere auf die Analyse.
RDF-Graphen konzentrieren sich auf die Datenintegration. Sie bestehen aus dem RDF-Tripel – zwei Knoten und einer Kante, die sie verbindet (Subjekt, Prädikat, Objekt). Jedes der drei Elemente wird durch einen Uniform Resource Identifier (URI) identifiziert. Man findet sie in Wissensgraphen und sie werden verwendet, um Daten miteinander zu verknüpfen. RDFs werden häufig von Unternehmen unter anderem im Gesundheitswesen oder Statistikämtern verwendet.
Property-Graphen sind deskriptiv und jedes der Elemente trägt Eigenschaften, Attribute, die seine Entitäten weiter bestimmen. Sie bestehen auch aus Knoten und Kanten, die die Knoten verbinden, und eignen sich besser für die Datenanalyse.
Vorteile
Die Betonung der Kanten eines Graphendatenbankmodells bedeutet, dass diese Datenbanken eine leistungsstarke Möglichkeit darstellen, selbst die komplexesten Beziehungen zwischen Daten zu verstehen. Der Vorteil daran ist, dass diese Art der Speicherung von Beziehungen auch eine schnelle Ausführung von Abfragen ermöglicht.
Durch die klare Darstellung von Beziehungen in einer Graphdatenbank lassen sich Trends und Elemente mit dem größten Einfluss leichter erkennen.
Nachteile
Graphdatenbanken haben dasselbe Problem wie NoSQL-Datenbanken: Es fehlt eine einheitliche Abfragesprache. Dies kann zwar ein Hindernis für die Verwendung einer Datenbank darstellen, beeinträchtigt jedoch nicht die Leistung dieses Datenbanktyps. Bestimmte Graphdatenbanken sind bekannter als andere, ebenso wie die von ihnen verwendeten Sprachen. Zu den gängigsten Graphdatenbanksprachen gehören zum Beispiel PGQL, Gremlin, SPARQL und AQL.
Ein weiterer Nachteil ist die Skalierbarkeit dieser Datenbanken, da sie für eine einstufige Architektur konzipiert sind, was bedeutet, dass sie nur schwer über mehrere Server hinweg skaliert werden können.
Wie alle anderen NoSQL-Datenbanken sind sie für einen bestimmten Zweck konzipiert und zeichnen sich durch ihre hervorragende Leistung aus. Sie sind keine universelle Lösung, die alle anderen Datenbanken ersetzen soll.
Anwendungsfälle und Beispiele
Graphdatenbanken sind mit einem Fokus auf Beziehungen konzipiert, und soziale Netzwerke sind dies auch. Eine Graphdatenbank ist eine gute Möglichkeit, alle Benutzer einer bestimmten sozialen Plattform und ihre Interaktionen zu speichern, um sie zu analysieren. Anhand des Aktivitätsvolumens der Benutzer können Sie feststellen, wie lebhaft oder aktiv eine soziale Medienplattform ist. Darüber hinaus können Sie die Influencer identifizieren, das Benutzerverhalten analysieren, Zielgruppen für Marketingzwecke isolieren usw.
Da sie in der Lage sind, die komplexesten Beziehungsgeflechte zu verfolgen und abzubilden, sind Graphdatenbanken ein gutes Werkzeug zur Aufdeckung von Betrug. Verbindungen zwischen Elementen, die mit herkömmlichen Datenbanken nur schwer zu erkennen sind, werden mit Graphdatenbanken plötzlich deutlich.
Einige der beliebtesten Graphdatenbanken – sowie Multi-Modell-Datenbanken, die Graphdatenmodelle enthalten – sind Neo4j, das sich für eine Vielzahl von geschäftlichen Zwecken eignet, gefolgt von Microsoft Azure Cosmos DB, OrientDB und ArangoDB.
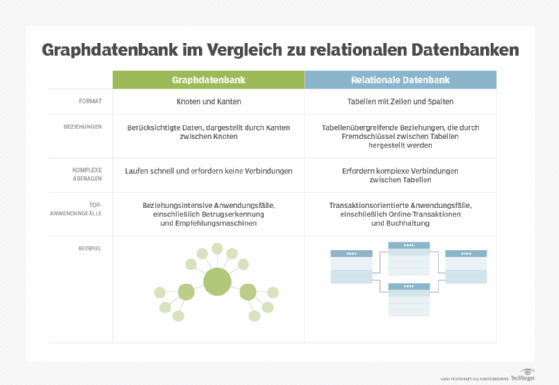
Graphdatenbanken versus relationale Datenbanken
Ein großer Vorteil jeder NoSQL- gegenüber einer SQL-Datenbank ist die Flexibilität der Datenspeicherung mit NoSQL. Immer wenn es um weniger strukturierte oder hochkomplexe Daten geht, ist Platz für eine NoSQL-Anwendung. Wenn Sie erwägen, neue Beziehungstypen und Eigenschaften einzuführen, um sie in einer SQL-Datenbank zu speichern, müssten Sie je nach Art der Daten neue Tabellen hinzufügen.
Bei einer Graphdatenbank hingegen ist es so einfach wie das Hinzufügen einer neuen Kante oder Eigenschaft. Durch das Verfolgen der Kanten zwischen Knoten können Sie die komplexesten Beziehungen zwischen zwei Knoten in einer Datenbank bis in die Tiefe nachvollziehen.
Der Bedarf an einer Graphdatenbank wird durch den Grad der Vernetzung zwischen Daten erkannt – wenn die Daten stark vernetzt sind, kann eine Graphdatenbank sinnvoll sein. Da diese Verbindungen so leistungsstark sind, ist eine Graphdatenbank eine bessere Wahl für die Datenanalyse als eine einfache Datenspeicherung. Wenn Sie mit Daten, die sich häufig ändern, flexibel sein möchten, ist eine NoSQL-Graphdatenbank wahrscheinlich die bessere Option für Sie.







