Mit optimierter Datenklassifizierung Dark Data eindämmen
Dark Data entsteht, wenn Daten unkontrolliert und ohne Bewertung gespeichert werden. Sinnvolle Kategorisierung und Management können hier Abhilfe schaffen.
von
Johnny Yu
Zuletzt aktualisiert: 16 Aug. 2019
„Dark Data“ stellt nicht nur ein Problem für das Datenmanagement dar. Diese Daten verursachen Probleme beim Speichern, beim Backup, bei der Compliance und Security, da die Belastung durch nicht klassifizierte Daten zu zusätzlichen Kosten und Verpflichtungen führt.
Die Consulting- und Marktforschungsfirma Gartner definiert Dark Data als „Informationsgüter, die Unternehmen während ihrer normalen Geschäftsaktivitäten sammeln, verarbeiten und speichern, die sie aber in der Regel nicht für andere Zwecke benutzen können“.
IT-Experten haben die „dunkle“ Seite der Definition erweitert, indem sie den Begriff für unzureichend definierte oder nicht kategorisierbare Daten verwenden. In einem von SearchSecurity veröffentlichten Interview hat Tim Tully, CTO bei Splunk, „Dark Data“ als „unbekannte, nicht identifizierte oder nicht genutzte Daten“ bezeichnet. Veritas, Anbieter von Datenschutztechnologie für Unternehmen, bezieht sich in ähnlicher Weise auf sie als nicht klassifizierte oder nicht markierte Daten.
Eine Studie, die im Auftrag von Veritas durch die britische Marktforschungsfirma Vanson Bourne durchgeführt wurde, fand heraus, dass 52 Prozent der Daten in den Unternehmen als „Dark“ zu bezeichnen sind. Bei der Studie wurden 1.500 IT-Entscheidungsträger aus 15 Ländern über ihre Probleme beim Datenmanagement befragt. Andere Studienergebnisse umfassen einen durchschnittlichen Verlust von zwei Millionen Dollar pro Jahr, der durch ineffizientes Datenmanagement verursacht wird, und einen Produktivitätsverlust von zwei Stunden pro Tag, verursacht durch die Suche nach relevanten Daten.
Um mit einem bestehenden Reservoir an Dark Data zurecht zu kommen, werden Analytic Tools benötigt, um sie zu durchsuchen und im Nachhinein zu klassifizieren.
Die Studie hebt hervor, wie sehr es sich um ein Problem des Datenmanagements handelt, aber die unbekannte Natur der Dark Data verursacht viele Probleme auf mehreren IT-Gebieten. Zum Beispiel könnten die Dark Data unter Sicherheitsgesichtspunkten Server-Logs enthalten, die im Detail zeigen, von woher ein Angriff auf das IT-System des Unternehmens gekommen ist.
Jyothi Swaroop, Vice President of Product and Solutions bei Veritas, ist der Ansicht, dass eine andere Security-Problematik entsteht, wenn eine Ransomware-Attacke die Dark Data eines Unternehmens verschlüsselt.
„Man ist stärker beunruhigt, wenn man nicht genau weiß, was eigentlich passiert ist“, sagt Swaroop und fügt hinzu, dass es für ein Unternehmen leichter ist, etwas zu planen oder ein Restore zu veranlassen, wenn es genau weiß, was man verloren hat.
Andere Probleme liegen in dem Betrieb oder der Erhaltung der Dark Data. Ein Unternehmen kann nicht sagen, ob es sich lohnt, diese Informationen zu behalten, aber es zahlt weiter für deren Speicherung und Backup, als wüsste man genau, ob es sich um klar identifizierte geschäftskritische Daten handeln würde. Von einem Compliance-Standpunkt aus sind Dark Data potentiell eine Belastung, weil Unternehmen nicht genau wissen können, ob sie jede Kopie von irgendetwas gelöscht haben.
Laut George Crump, dem Gründer der auf Storage spezialisierten Analystenfirma Storage Switzerland, ist die Fähigkeit zum Sammeln von Daten dank der Ausbreitung von Sensoren für das Internet of Things, Edge-Geräten, Kameras und anderen Aufnahmegeräten wesentlich größer als die, sie zu kategorisieren und weiterzuverarbeiten.
„Wir sammeln zu viele Daten“, sagt Crump. Und fügt hinzu, dass die meisten dieser Daten durch sekundäre Systeme und Prozesse wie zum Beispiel Log Files erzeugt werden.
Crump schlägt mehrere Ansätze vor, um diesen Engpass zu vermeiden oder ihn zu eliminieren. Einer sieht vor, unbenutzte Computerkapazitäten für Datenanalyse und Klassifikationsprozesse zu verwenden. Ein anderer empfiehlt, mehr Vernunft beim Erfassen von Daten zu zeigen. Man müsste so schnell wie möglich bestimmen, ob es sich lohnt, Daten weiter zu behalten, nachdem sie verarbeitet worden sind. So ließe sich auch das Ansammeln von Dark Data aufhalten.
Um mit einem bestehenden Reservoir an Dark Data zurecht zu kommen, werden Analytic Tools benötigt, um sie zu durchsuchen und im Nachhinein zu klassifizieren. Für Swaroop besteht die beste Methode, Dark Data zu verhindern, darin, ein intelligentes, integriertes Datenmanagementsystem aufzubauen: Es stellt eine Übersicht über die Daten von ihrer Entstehung bis zu ihrer Außerkraftsetzung oder Löschung zur Verfügung.
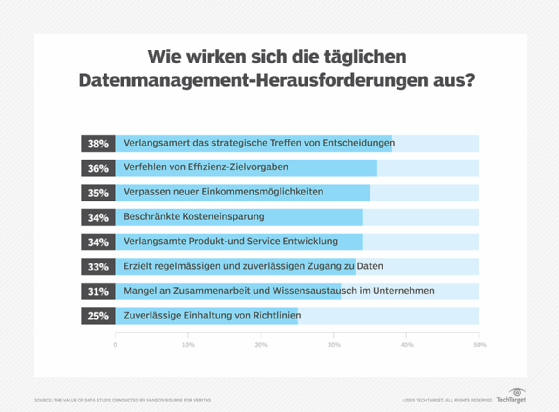
Abbildung 1: So beeinflussen die täglichen Datenmanagement-Herausforderungen Geschäftsprozesse
Das Problem ignorieren
Laut Crump war vor 20 Jahren Data Management notwendig, weil Unternehmen keine Storage-Systeme hatten, die groß genug für alle gesammelten Daten waren. Seitdem hat sich die Speichertechnologie verbessert und sie wurde billiger.
„Man konnte eigentlich kein Speichersystem erstellen, das groß genug war, aber heute können wir es“, berichtet Crump. „Anstatt auf der Managementseite effizient zu sein, setzt man auf mehr Storage-Systeme, um das Problem zu lösen. Wir können Daten nun für immer aufbewahren, aber es fehlt uns an der Fähigkeit, die Daten schnell zu analysieren.“
Diese Situation hat auch zu der Einstellung geführt, nie etwas zu löschen, da es so wenig kostet, die Daten für immer zu behalten. So erzeugt zum Beispiel das Unternehmen Palmaz Vineyard jede Stunde über ein Gigabyte an Umgebungsdaten, um für den auf Machine Learning basierten Reifungsprozess der Weine genug Informationen zu besitzen. CEO Christian Gastón Palmaz sagt, dass man alle diese Daten behält.
„Es ist etwas falsch daran, Daten zu löschen, für die man so hart gearbeitet hat, um sie überhaupt zu erzeugen“, sagt Palmaz. „Es gibt immer einen Weg, um sie aufzubewahren. Wenn sie weg sind, sind sie für immer weg. Und meiner Meinung nach sollten sie für immer existieren.“
Ein anderes Problem stellt sich mit der Art und Weise, wie Unternehmen die Technologie von Datenmanagement annehmen. Es fällt IT-Administratoren oft schwer, hierfür ihre Vorgesetzten mit an Bord zu holen, erläutert Christophe Bertrand, Senior Analyst bei der Enterprise Strategy Group.
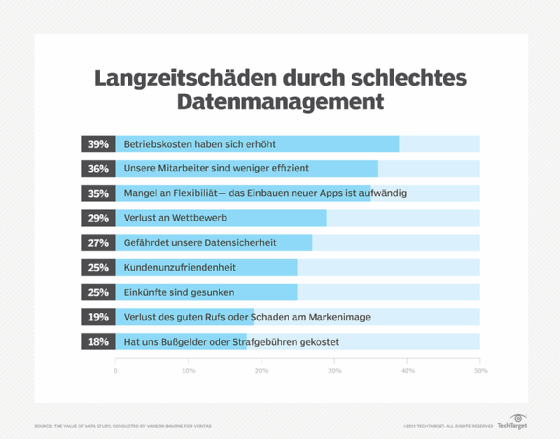
Abbildung 2: Langzeitschäden durch schlechtes Datenmanagement
„Solche Lösungen treten nicht mit einem genügend sichtbaren RoI (Return on Investment) an“, fährt Bertrand fort, wodurch es schwerer falle, sie der Geschäftsführung schmackhaft zu machen. Dark Data zu identifizieren, sei nun mal nicht profitabel, aber diese Daten in etwas Nützliches zu verwandeln – sie zum Beispiel für Analytics oder Test/Dev zu verwenden – könnte der Schlüssel dazu sein, die Meinungen zu verändern.
Aber laut Crump werden die Unternehmen wohl weiter versuchen, das Problem der Dark Data mit weiteren traditionellen Speichersystemen zu erschlagen, weil das als die einfachste Lösung erscheint. Wie er berichtet, habe ihm seine Consulting-Erfahrung mit Unternehmen, die dieses Problem haben, gezeigt, dass sie keinen besseren Weg wissen und auch nicht die Zeit haben, einen geeigneten Service zu suchen und einzurichten. Und solange die erhöhte Komplexität nicht größer sei als die bekannten Nachteile, mehr Storage zu kaufen, werde man mit dieser Praxis fortfahren.