
Getty Images
Mit KI und ML die Komplexität von Kubernetes bewältigen
Erfahren Sie, wie DevOps-Teams die Leistung und Observability in Kubernetes mit KI und ML-Verfahren verbessern können. Bewerten Sie selber die Vor- und Nachteile und Anwendungsfälle.

Die verteilte und dynamische Natur von Kubernetes eignet sich gut für moderne Softwarearchitekturen. Die Komplexität der Plattform und die komplexe Struktur heutiger Cloud-nativer Anwendungen stellen jedoch Hindernisse für die Überwachung von Kubernetes-Bereitstellungen dar.
In Kubernetes-Umgebungen umfasst Observability (Beobachtbarkeit) das Sammeln und Analysieren von Metriken, Protokollen und Traces, um Probleme zu identifizieren, Fehler zu diagnostizieren und die Leistung des Clusters zu optimieren. Die Verfolgung von Anfragen über einen Microservices-basierten Anwendungsstapel hinweg kann jedoch schwierig sein. Der Umgang mit der schieren Menge an Daten, die von Kubernetes-Clustern und containerisiertenAnwendungen erzeugt werden, stellt eine zusätzliche Herausforderung dar.
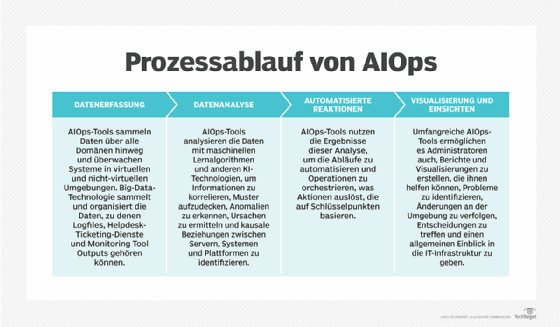
Die Anwendung von künstlicher Intelligenz (KI) und maschinellem Lernen (ML) kann IT-Teams dabei helfen, das Rauschen (Noise) zu sortieren und verwertbare Informationen über den Cluster-Betrieb und -zustand zu erhalten. Aber lassen Sie sich nicht von dem Hype anstecken. Um das Beste aus diesen Techniken in Kubernetes herauszuholen, ist es wichtig, die falschen Vorstellungen über KI und ML zu überwinden und ihre Grenzen sorgfältig abzuwägen.
Anwendungsfälle für KI und ML in Kubernetes-Umgebungen
Mehrere Bereiche der Observability und Verwaltung von Kubernetes eignen sich besonders gut für KI und ML. Unabhängig davon, wofür Sie sich entscheiden, sollten Sie vorsichtig sein und klein anfangen.
Beginnen Sie die Einführung von KI und ML in Kubernetes mit einem Pilotprojekt, das Input und Feedback von den wichtigsten Kubernetes-Experten Ihres Unternehmens einbezieht. Dokumentieren Sie die gewonnenen Erkenntnisse und weiten Sie diese dann auf andere Kubernetes-Projekte aus, die von der Observability und Leistungsverbesserung profitieren könnten.
1. Erkennung von Anomalien und Root Cause Analysis
KI- und ML-Modelle, die darauf trainiert sind, anomales Verhalten in Kubernetes-Clustern und -Anwendungen zu erkennen, können Betriebsteams helfen, Probleme proaktiv anzugehen, bevor sie eskalieren.
Die Erkennung von Anomalien ist ebenso eine Kunst wie eine Wissenschaft. Da KI-Systeme Muster und Korrelationen in Daten erkennen können, die Menschen möglicherweise übersehen, sind diese Modelle eine Option zur Unterstützung von Betriebsmitarbeitern, die nur über begrenzte Erfahrung in der Anomalieerkennung verfügen. KI ist zwar kein Ersatz für einen erfahrenen Kubernetes-Experten, aber der Einsatz von KI zur Unterstützung von Ingenieuren kann zu einer genaueren und effizienteren Problemerkennung und -analyse führen.
Ebenso kann der Einsatz eines KI-Tools zur Erkennung der Grundursachen (Root Cause) von Problemen in Kubernetes-Clustern und -Anwendungen den Zeit- und Arbeitsaufwand für die Fehlerbehebung verringern. Der anhaltende Mangel an Kubernetes-Fachwissen macht KI für die Root Cause Analysis besonders interessant für Unternehmen, die ihr begrenztes internes Kubernetes-Fachwissen erweitern und erhalten wollen.
2. Optimierung der Leistung
KI und ML können die Leistung von Kubernetes-Clustern und -Anwendungen verbessern, indem sie Engpässe identifizieren und Optimierungen vorschlagen. Auf der Grundlage von Systemdaten und Leistungsmetriken können KI-Tools potenzielle Problembereiche identifizieren und Möglichkeiten zur Verbesserung der Benutzererfahrung und -zufriedenheit vorschlagen.
KI kann einen erfahrenen Kubernetes-Administrator nicht ersetzen, wenn es um Leistungsoptimierung geht. Aber die Erkenntnisse von KI-Tools können weniger erfahrenen Kubernetes-Administratoren helfen, Entscheidungen zu treffen und mehr Aufgaben zur Leistungsoptimierung zu bewältigen.
3. Vorausschauende Kapazitätsplanung
KI-Systeme können die komplexen Beziehungen zwischen Workload-Merkmalen und bestehenden Ressourcennutzungsmustern erlernen, um die zukünftige Ressourcennutzung genauer vorherzusagen.
Auf der Grundlage dieser Analysen können KI-Tools dabei helfen, die Ressourcennutzung und den Bedarf in Kubernetes-Clustern vorherzusagen, so dass IT-Teams die Ressourcen effektiver und nachhaltiger planen und zuweisen können. Diese Art der KI-Unterstützung kann Mitgliedern von Ops-Teams aller Erfahrungsstufen helfen, indem sie neue Datenpunkte zur Verfügung stellt, die bei der Kapazitätsplanung berücksichtigt werden können.
Nachteile und Einschränkungen von KI und ML für Kubernetes
Der Hype um KI ist in der IT-Branche derzeit ungebremst und es gibt keine Anzeichen dafür, dass er aufhört. Daher ist es besonders wichtig, bei der Bewertung von KI- und ML-Tools für Kubernetes praxisnah vorzugehen und eine Due-Diligence-Prüfung durchzuführen.
Wie bei anderen KI-Anwendungsfällen ist das Potenzial für Modellverzerrungen (Bias) und ungenaue Vorhersagen eine eindeutige Einschränkung von KI für Kubernetes. Da Modelle nur so gut sind wie die Daten, mit denen sie trainiert wurden, können KI-Vorhersagen, die auf nicht repräsentativen oder anderweitig unzureichenden Daten basieren, unzuverlässig und ungenau sein. Modelle in der Produktion müssen neu trainiert werden, da ihre Leistung im Laufe der Zeit aufgrund von Änderungen der Workload-Merkmale oder der zugrunde liegenden Umgebung nachlässt.
Ein weiterer Nachteil ist die Interpretierbarkeit der Ergebnisse von Modellen. Aufgrund der Blackbox-Natur von KI und ML kann es schwierig sein zu verstehen, warum ein Modell eine bestimmte Entscheidung getroffen hat. Dies wiederum kann dazu führen, dass manche Teams den Erkenntnissen oder Vorschlägen eines KI-Systems weniger vertrauen.
Datenschutz- und Sicherheitsbedenken werden bei der Implementierung von KI und ML immer eine Rolle spielen. Der Einsatz dieser Technologien in Unternehmensumgebungen könnte die Erfassung sensibler Daten mit sich bringen, was Bedenken hinsichtlich des Datenschutzes, der Privatsphäre der Benutzer und der Compliance aufwirft.
Tooling-Optionen zum Testen von KI in Kubernetes
Verschiedene KI- und ML-Produkte, die für Kubernetes-Umgebungen entwickelt wurden, sind bereits auf dem Markt. Dazu gehören unter anderem:
- KubeLinter. Dabei handelt es sich um ein quelloffenes statisches Analyse-Tool für Kubernetes-YAML-Dateien und Helm-Diagramme. Es nutzt KI- und ML-Techniken, um Konsistenz zu gewährleisten und Fehler bei der Erstellung von Kubernetes-Ressourcen zu reduzieren.
- Prometheus. Dies ist ein Open-Source-Überwachungs- und Alarmierungs-Tool für die Beobachtung von Kubernetes auf Unternehmensebene. Es nutzt KI und ML, um Metriken zu sammeln und zu analysieren und Einblicke in die Leistung und den Zustand von Kubernetes-Clustern zu geben.
- Grafana. Dies ist eine Open-Source-Plattform zur Datenvisualisierung und -überwachung. Die KI- und ML-Funktionen umfassen die Erkennung von Anomalien und Vorhersagen.
- Dynatrace. Hierbei handelt es sich um eine Beobachtungsplattform, die einen umfassenden Einblick in Kubernetes-Umgebungen bietet. Dynatrace verwendet ML-Algorithmen, um Anomalien zu erkennen und umsetzbare Erkenntnisse zu liefern, die die Leistung verbessern und Ausfallzeiten reduzieren.







