Storage Container können viele Dinge aufnehmen und werden oft falsch eingeschätzt. Hier sind fünf gängige Mythen über Storage Container, die verschwinden müssen.
Während eine wachsende Zahl von Unternehmen sich für ihre Speicheranforderungen an Container wendet, sind sich viele Anwender immer noch nicht sicher, wie die Technologie funktioniert und was sie letztendlich leisten kann. Diese weit verbreitete Unkenntnis und Unerfahrenheit hat zu einer Reihe von potenziell destruktiven und teuren Fehleinschätzungen über die Fähigkeiten und Funktionen der Storage-Container geführt.
Sind Sie sich unsicher, wenn es um den Einsatz von Storage-Containern geht? In diesem Tipp werfen wir einen Blick auf fünf allgegenwärtige Mythen über Storage-Container, die vielen Storage-Manager schlechte Leistung und unnötige Kosten eingebrockt haben.
Die Aufklärung dieser häufigen Missverständnisse soll eine genauere Bewertung der Technologie ermöglichen und zeigen, wie man sie am besten in die Speicherstrategie eines Unternehmens integrieren kann.
1. Die Anwendungen, die im Storage ausgeführt werden, sind temporär und erfordern daher keinen dauerhaften Speicher.
Stellen Sie sich vor, ein Unternehmen betreibt eine Datenbank, wie PostgreSQL, MySQL oder Microsoft SQL, innerhalb eines Containers und die Datenbank enthält Kundendaten, Patientenakten oder andere äußerst wichtige Informationen.
„Das Herunterfahren des Containers, auf dem diese Datenbank läuft, was absichtlich vom Host durchgeführt werden kann, oder durch einen unerwarteten Benutzerfehler, Hardwarefehler oder Stromausfall verursacht wird, führt zu einem massiven Datenverlust“, sagt Itzik Reich, Dell EMC Vice President of Technology für die Produktlinien XtremIO und VxFlex OS.
Ohne persistenten Speicher können diese kritischen Daten für immer verloren gehen. „Und, wie wir alle wissen, kann ein Verlust gespeicherter Daten einen sehr, sehr schlechten Tag für einen Datenbankadministrator bedeuten“, betont Reich.
2. Storage-Container sind nicht gefährdet und müssen nicht in Risikominderungsstrategien einbezogen werden.
Mit dem Verständnis, dass ein Container ein partitionierter Anwendungsbereich innerhalb eines anderen Servers ist, ist es leicht zu übersehen, dass das Schreiben in das Container-Dateisystem dazu führt, dass Festplatten-Writes auf dem zugrunde liegenden Host-Server-Dateisystem durchgeführt werden, erklärt Peter Duthie, Co-CEO und Chefarchitekt bei Ground Labs, einem Anbieter von Datenerfassungssoftware.
„Auch wenn die Änderungen am Dateisystem bei Beendigung der Containerinstanz verworfen werden können, sind die während der Lebensdauer des Containers geschriebenen Dateien genauso verfügbar wie alle anderen Dateien während der Lebensdauer dieses Containers“, sagt er.
Interne und externe Bedrohungen existieren und attackieren unabhängig davon, ob der Zielspeicher temporär oder dauerhaft ist.
Interne und externe Bedrohungen existieren und attackieren unabhängig davon, ob der Zielspeicher temporär oder dauerhaft ist. „Ein Angreifer kann nach erfolgreichem Zugriff auf den Container- oder Container-Server-Host auf das Container-Dateisystem genauso zugreifen wie auf jede andere virtuelle Maschine oder jeden anderen Server“, warnt Duthie.
„Gesperrte Container können eine kleinere Angriffsfläche bieten, was jedoch einen erfolgreichen Angriff auf die Anwendungen und Dienste, die auf dem Container oder Container-Host verbleiben, nicht ausschließt. In diesem Fall sind alle sensiblen Daten, die auf dem Container-Dateisystem gespeichert sind, wie temporäre Dateien, Protokolldateien und lokale Datencaches, gefährdet.“
3. CSI, das kürzlich zu Kubernetes hinzugefügte und von großen Storage-Anbietern übernommene Container Storage Interface, kann jedes Speichersystem automatisch zum „Container-nativen Speicher“ machen.
CSI ist eine wichtige Schnittstelle zwischen einem Speichersystem und Kubernetes. „Es bietet Kubernetes die Möglichkeit, mit einem zugrundeliegenden Speichersystem zu kommunizieren, um die für den Betrieb von Datendiensten wie Datenbanken in Containern notwendigen Speicherressourcen bereitzustellen und darauf zuzugreifen“, sagt Michael Ferranti, Vice President of Product Marketing bei der Portworx, Anbieter von Container-Storage-Software.
Der Fehler, den einige Leute machen, ist zu glauben, dass CSI sofort aus einem traditionellen Storage-System ein Container-natives Storage macht. „So wie die USB-3-Schnittstelle kein USB-kompatibles Gerät zu einem Smartphone macht, so macht ein CSI-Plug-in auch keinen Container-nativen Speicher“, fügt er an.
CSI bietet zwar eine Schnittstelle für jedes Speichersystem zur Kommunikation mit Kubernetes, definiert aber kein bestimmtes Verhalten für das Speichersystem selbst. „Infolgedessen haben Speichersysteme, die für relativ statische VM-basierte Anwendungen entwickelt wurden, Schwierigkeiten, mit der Dynamik von Containerimplementierungen Schritt zu halten“, meint Ferranti.
Er weist zudem darauf hin, dass Speichermanager, die Microservices und DevOps-Praktiken zusammen mit Storage-Containern einsetzen, äußerst vorsichtig sein sollten, wenn sie ein traditionelles Speicher-Array mit einem CSI-Plug-in zur Sicherung ihrer Container-Implementierungen verwenden. „Sie werden feststellen, dass die Skalierbarkeit und Flexibilität von Containern nicht zu traditionellen Storage-Systemen passt, selbst mit einem CSI-Plug-in nicht“, mahnt er.
4. Bestehende externe Speichersysteme können Sie einfach an einen Container-Cluster anbinden.
Obwohl es beispielsweise möglich ist, Datenbanken und persistente externe Volumes an einen Kubernetes-Cluster anzubinden, ist dieser Speicher nicht unbedingt für ein großes Cluster von kleinen Prozessen ausgelegt. „Es ist wichtig zu erkennen, dass der Grund für die Verwendung von Containern typischerweise darin besteht, dass man Code in viele kleine Dienste – Mikroservices – zerlegen und dann replizieren kann, um die Widerstandsfähigkeit und Leistung zu erhöhen“, erklärt Tom Petrocelli, ein wissenschaftlicher Mitarbeiter des Technologieberatungsunternehmens Amalgam Insights.
Ein großes Cluster könnte leicht eine überdurchschnittliche Anzahl von Verbindungen zum Speicher erzeugen. „Die Anzahl der Verbindungen wird ebenfalls zunehmen und abnehmen, wenn das Cluster nach oben und unten skaliert, sagte er. „Die meisten Speichersysteme sind nicht für so viele Verbindungen oder diese Art der schnellen Skalierung ausgelegt.“
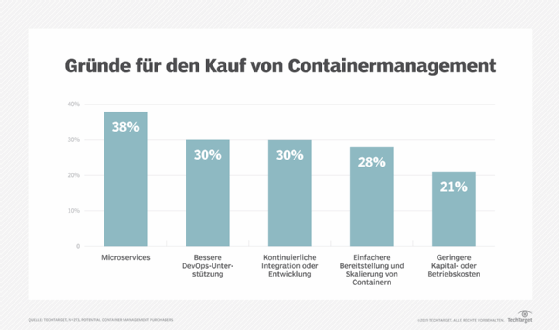
Abbildung 1: Das sind die treibenden Faktoren für den Erwerb von Container-Management-Lösungen.
5. Sie sollten keine stateful Workloads, wie zum Beispiel relationale Datenbanken, mit Container-Orchestrierungs-Frameworks wie Kubernetes ausführen.
Dieser Irrglaube hat Unternehmen daran gehindert, ihre Datenbanken in Kubernetes zu migrieren und damit ihre Infrastrukturimplementierungen aufzuteilen, bemerkt Jitendra Vaidya, Mitbegründerin und CEO von PlanetScale, einem Datenbankas-a-Service-Anbieter. „Sie betreiben ihre zustandslosen (stateless) Dienste in Kubernetes, verwalten aber die Datenbanken außerhalb von Kubernetes und müssen daher zwei verschiedene Tools pflegen und verwalten.“
Ein Datenbank-Clustering-System wie Vitess kann dieses Problem lösen, indem es eine zustandslose Proxy-Schicht bereitstellt und ein etcd-Cluster zum Speichern der Cluster-Topologie verwendet, was schnelle Master-Failover ermöglicht, ohne dass die Anwendungen Datenverluste erleiden.