
peterschreiber.media - stock.ado
Einen Data Lake in der Cloud oder On-Premises einsetzen?
On-Premises oder in der Cloud: Was ist der bessere Ort für einen Data Lake? Bevor man sich entscheidet, wo man eine Big-Data-Umgebung einsetzt, gibt es einiges zu beachten.

Große Unternehmen haben viele Anwendungen. Einige Konzerne setzen mehrere Hundert IT-Anwendungen ein, von denen nur eine das ERP-System ist. Um einen Eindruck von der Unternehmensleistung im gesamten Unternehmen zu erhalten, muss man Daten aus diesen Anwendungen aggregieren und Inkonsistenzen in den Datendefinitionen und -klassifikationen unter anderem von Produkten, Kunden und Lieferanten beheben.
Diese nicht-triviale Aufgabe, die die Behandlung von Datenqualitätsproblemen und anderen heiklen Fragen erfordert, führt häufig zu einem Data Warehouse. Das Data Warehouse bei Umstrukturierungen, Übernahmen und anderen geschäftlichen Veränderungen auf dem neuesten Stand zu halten, ist eine enorme Herausforderung für Datenmanagementteams. Doch es ist das, worauf sich Unternehmen – mit unterschiedlichem Erfolg – in erster Linie verlassen, um eine einheitliche Sicht auf ihr Geschäft zu erhalten.
Zumindest bis das Konzept des Data Lake entstand, um eine Big-Data-Alternative zum traditionellen Data Warehouse zur Verfügung zu stellen. Mittlerweile gibt es unter IT-Anbietern einen wachsenden Drang, die Einführung eines Data Lake in der Cloud zu unterstützen. Aber es gibt Fragen, die zu berücksichtigen sind, bevor Sie sich entscheiden, Ihren Data Lake dort einzusetzen.
Was genau ist Data Lake?
Das Aufkommen großer Datenmengen, die für herkömmliche Datenbanken zu groß und vielfältig sind, haben die technische und wirtschaftliche Verarbeitung für Manager kompliziert gemacht. Big Data entsteht aus intelligenten Zählern (Smart Meter), Sensoren, Weblogs, Telefonanlagen, sozialen Medien und vielen anderen Quellen, oft in unstrukturierter oder halbstrukturierter Form. Ein modernes Flugzeug erzeugt bis zu 5 TB Daten pro Flug, während ein autonomes Auto 40 TB pro Tag ausspuckt.
Relationale Datenbanken sind nicht für so große Mengen und so unterschiedliche Datensätze ausgelegt, und die Kosten können schnell steigen, wenn man versucht, sie für die Bewältigung großer Datenmengen zu skalieren.
Eine billigere und geeignetere Option kam mit Hadoop auf, einem Open Source Framework für DIE verteilte Verarbeitung von Daten mit einem integrierten Dateisystem. Hadoop ermöglicht es Anwendern, sehr große Datenmengen auf Clustern mit Commodity-Hardware zu speichern und zu verwalten.
Es wurde in Betrieb genommen, um mit Big Data umgehen zu können, das von großen Datenunternehmen erzeugt wurde, zusammen mit unterstützenden Technologien wie Spark und HBase. Big-Data-Systeme wuchsen in den vergangenen Jahren zu vollwertigen Data Lakes heran. Und es wurden mehr Bereitstellungsalternativen verfügbar. Eine weitere Option für einen Data Lake in der Cloud besteht beispielsweise darin, Hadoop zu umgehen und eine Processing Engine wie Spark gegen Daten in einem Cloud-Object-Storage-Dienst laufen zu lassen.
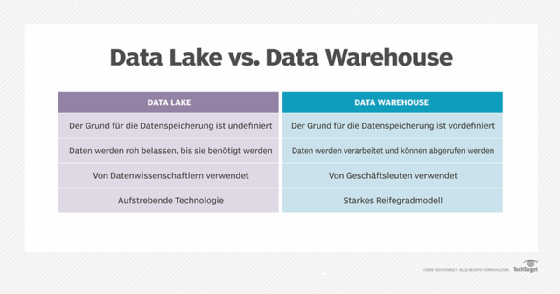
Bevor man mit einer Data-Lake-Bereitstellung beginnt, muss man sich darüber im Klaren sein, dass die Daten in einem Data Lake oft nicht im Voraus verarbeitet oder zusammengefasst werden, wie dies in einem Data Warehouse der Fall ist. Der Begriff Data Lake beschreibt in der Regel die Speicherung von Rohdaten, welche je nach Bedarf für bestimmte Analysezwecke aufbereitet werden können.
Um Data Lakes und Data Warehouses einander gegenüberzustellen, denken Sie an den Unterschied zwischen dem Wasser eines echten Sees und einer Flasche Wasser, die gefiltert und für den einfachen Gebrauch verpackt wurde.
Ursprünglich wurden die meisten Data Lakes innerhalb der Unternehmens-Firewall eingesetzt. Es erfordert jedoch eine Menge Ressourcen, einen wachsenden Data Lake zu unterhalten und weitere Server hinzuzufügen und zu verwalten, wenn die Daten einströmen. Genauso wie Cloud-Anbieter in andere Teile des IT-Marktes eingedrungen sind, die Unternehmen früher intern abgewickelt haben, ist es nicht überraschend, dass dasselbe mit Data Lakes geschehen ist.
Data Lakes in der Cloud
Die Verwaltung eines Data Lake im eigenen Rechenzentrum – einschließlich der Notwendigkeit, sich mit Backups, Sicherheit, Hardwareausfällen und anderen administrativen Aufgaben zu befassen – ist ein großer Aufwand. Aus diesem Grund sind Cloud-Bereitstellungen und gemanagte Services für Data Lakes zu einer immer beliebteren Alternative zu On-Premises-Hadoop-Clustern geworden.
AWS, Microsoft und Google gehören zu den Anbietern, die Data Lakes in der Cloud anbieten. Es gibt jedoch einige wichtige Probleme bei der Verwaltung von Data Lakes, die vor der Übergabe Ihrer Umgebung und Ihrer Daten an einen Cloud-Dienstanbieter zu berücksichtigen sind.
Auf der positiven Seite steht: die Verwaltung der Umgebung ist das Problem des Anbieters, und Sie können sie je nach Bedarf nach oben oder unten skalieren, ohne in neue Hardware investieren zu müssen. Andererseits müssen Sie sich überlegen, ob Sie dem Cloud-Anbieter die Sicherheit Ihrer Daten anvertrauen, von denen viele hochsensibel sein können, und ob Sie seiner Fähigkeit vertrauen, den Service zu betreiben und am Laufen zu halten.
Obwohl die meisten Anbieter immer zuverlässiger werden, gab es zum Beispiel 2019 größere Ausfälle von Cloud-Diensten bei Microsoft Azure (am 29. Januar) und Google Cloud (am 2. Juni). Aber ist es weniger wahrscheinlich, dass Ihr internes Rechenzentrum mit Ausfällen zu kämpfen hat? Das ist eine Frage, die sich Ihre Organisation stellen sollte.
In vielen Fällen hängt die Entscheidung, ob ein Data Lake in der Cloud oder intern betrieben werden soll, davon ab, ob Sie Vertrauen in einen Drittanbieter haben, der Ihre Daten sicher und geschützt aufbewahrt. In den frühen Tagen der Cloud waren Unternehmen oft nervös, ihre Daten außerhalb der Unternehmens-Firewall zu haben. Nach und nach haben jedoch die erhöhte Flexibilität und die potenziellen wirtschaftlichen Vorteile der Verlagerung von Datenplattformen in die Cloud für viele Unternehmen diese Bedenken überwogen.
Heutzutage werden immer mehr Anwendungen in die Cloud verlagert, darunter auch Data Lakes. Laut einem Bericht von IDC sind die weltweiten Ausgaben für Cloud Computing im Jahr 2019 um 24 Prozent gegenüber 2018 gestiegen. Bereits 2017 nutzten 90 Prozent der Unternehmen irgendeine Art von Cloud-Service.
Daten in einem Data Lake verwenden
Nach der Entscheidung, ob sie einen Data Lake in der Cloud oder In-house hosten möchten, besteht die andere große Hürde, vor der Unternehmen stehen, darin, wie sie die Daten, die ihre Data Lakes füllen, mit zunehmender Geschwindigkeit effektiv nutzen können.
Ein Datenanalyst zu sein, der mit einer so großen Datenmenge konfrontiert wird, ist wie der Versuch, aus einem Feuerwehrschlauch zu trinken. Sie müssen die Daten, die im Data Lake gespeichert werden, klassifizieren, ihre Datensätze mit Metadaten versehen, die die Informationen später identifizierbar machen, und damit beginnen, die Beziehung zwischen diesen Daten und Ihren anderen Unternehmensdaten abzubilden. Das Hinzufügen aussagekräftiger Metadaten zu den Rohdaten ist besonders wichtig. Wenn Sie das nicht tun, wird Ihr Data Lake eher zu einem Datensumpf.
Unternehmen richten ihre Data Lakes oft neben traditionellen Data Warehouses ein, wobei sie die Daten aus dem Lake in das Warehouse pumpen, wenn sie für Analyseanwendungen benötigt werden. Bevor Sie sich entscheiden, ob Sie sich für einen Cloud-Service für Ihren Data Lake entscheiden, müssen Sie auch überlegen, ob dieser Service eine gute Ergänzung zu Ihrem Data Warehouse darstellt.
Wenn Ihr Data Lake beispielsweise Social Media Feeds mit Kundenkommentaren zu Ihrer Marke aufnimmt, können Sie dann diese Stimmungsdaten mit Ihren Kundendaten in Beziehung setzen? Vielleicht sollten Sie jemandem, der sich über Produkt- oder Kundendienstprobleme beschwert, viel mehr Aufmerksamkeit schenken, wenn er ein geschätzter Kunde in Ihrem Loyalitätsprogramm ist. Doch zuerst müssen Sie diese Verbindung zwischen dem Data Lake und dem Data Warehouse herstellen.
Die Auseinandersetzung mit dem Rohdaten-Data-Lake und die Kombination mit Mainstream-Unternehmensdaten bietet viele Geschäftsmöglichkeiten, ist aber auch eine große Herausforderung für hart umkämpfte Datenmanagementmitarbeiter. Und das gilt unabhängig davon, ob die Daten in der Cloud oder vor Ort bereitgestellt werden.







