
sommersby - stock.adobe.com
Diese 3 Hürden bei Cloud-Datenmanagement müssen sie beachten
Wenn Firmen Daten in der Cloud haben, gibt es oft noch Bedenken, wie sie und ihre Datenschutzanbieter diese Daten verwalten, um Leistung und Kosten optimal auszubalancieren.

Cloud-Datenmanagement ist die Fähigkeit, Daten in die Cloud zu migrieren, Daten zwischen Speicherebenen (Storage Tiers) innerhalb der Cloud zu verschieben, Daten zwischen Cloud-Anbietern zu verschieben und diese Daten anderen Anwendungen oder Arbeitslasten zu präsentieren. Die meisten Datenschutzanbieter geben an, eine Form der Cloud-basierten Datenverwaltung anzubieten.
Die Fähigkeiten innerhalb der einzelnen Produkte variieren, daher ist es wichtig zu verstehen, welche Aspekte der Cloud-Datenverwaltung ein Unternehmen benötigt. Es ist auch wichtig zu erkennen, welche Herausforderungen die Cloud-Anbieter selbst stellen, wenn ein Unternehmen versucht, seine Cloud-Daten zu verwalten.
Warum Cloud-Daten verwalten?
Cloud-Anbieter haben, noch mehr als traditionelle Rechenzentren, mehrere Speicherebenen oder -klassen (Tiers). Kunden werden für die von ihnen verbrauchte Kapazität und die Anzahl der von ihnen ausgeführten I/O-Transaktionen berechnet. Jede Ebene innerhalb der Cloud bietet unterschiedliche Leistungsprofile, und die Kosten für die Nutzung dieses Speichers stehen in direktem Zusammenhang mit dem Leistungsniveau, das der Kunde benötigt.
Diese Tiers haben die Datenverwaltung überhaupt erst hervorgebracht. Anders als bei der Datenverwaltung im eigenen lokalen RZ gibt es echte und unmittelbare Kosteneinsparungen, wenn ein Unternehmen Daten identifizieren und in eine niedrigere Speicherklasse verschieben kann.
Herausforderung 1. Daten in die Cloud transferieren
Wenn eine Organisation möchte, dass ihr Data-Protection-Provider ein Cloud-basiertes Datenmanagement anbietet, sind IT-Fachleute oft gezwungen, zwischen zwei Methoden zur Verlagerung von Daten in die Cloud zu wählen: die Behandlung von Cloud-Storage als primärer Speicherbereich für geschützte Datenkopien oder als Archiv von Daten aus der lokalen Infrastruktur.
Bei der ersten Methode können Datensicherungsanbieter eine Kopie auch On-Premises aufbewahren oder auch nicht, aber in beiden Fällen landen 100 Prozent der Daten auf dem Cloud-Speicher. Bei der Archivmethode werden ältere Sicherungskopien in der Regel in die Cloud verschoben, und der Anbieter bewahrt nur die Daten auf, die für die Wiederherstellung am ehesten vor Ort benötigt werden. Der Vorteil der Archivierungsmethode besteht darin, dass sie die getätigten Investitionen in lokale Ressourcen für Kosten und Stellfläche für die physische Datensicherung reduziert.

Um die Cloud sowohl hinsichtlich der Speicher- als auch der Rechenressourcen voll auszunutzen, möchte ein Unternehmen wahrscheinlich eine vollständige Kopie der Daten auf dem Cloud-Speicher haben, und es möchte auf jeden Fall, dass die neuesten Änderungen auch in den Cloud-Daten wiederzufinden sind.
Die meisten Datenschutzprodukte können eine vollständige Basiskopie der Daten schnell aktualisieren, selbst wenn die Software diese Kopie in der Cloud lokalisiert. Folglich ist jedes Produkt, das über eine schnelle Aktualisierungsfunktion verfügt, geeignet, die Herausforderung zu meistern, Daten in die Cloud zu transferieren.
Ein potenzielles Problem ist die Häufigkeit einer Sicherung. Die meisten Datenschutzanwendungen werden nur mehrmals täglich ausgeführt, so dass die Kopie, mit der Cloud-basierte Anwendungen möglicherweise arbeiten, Stunden hinter der Produktionskopie zurückbleiben kann und nicht auf dem neusten Stand ist. In Situationen wie Tests, Entwicklung, Berichterstellung und Analyse ist diese Verzögerungszeit oft akzeptabel. In Fällen wie Cloud-Bursting oder Cloud-Failover ist sie es nicht.
Herausforderung 2. Verschieben von Daten innerhalb der Cloud
Es besteht ein erheblicher Kostenunterschied zwischen den verschiedenen Cloud-Ebenen, so dass es von entscheidender Bedeutung ist, zu verstehen, wo Daten zuerst platziert und wann sie auf eine andere Ebene verschoben werden müssen. Die Versuchung könnte darin bestehen, Daten zunächst auf der am wenigsten teuren Speicherebene zu platzieren. Das Problem besteht darin, dass nicht alle Anwendungen mit jeder Schicht zusammenarbeiten können und nicht jede Schicht die Leistung erbringen kann, die die Anwendung zur Verarbeitung der Daten benötigt.
Wenn ein Unternehmen beispielsweise eine Kopie der Cloud-Daten verwendet, um die nächste Version seiner Anwendung zu testen, läuft die Anwendung möglicherweise nur auf dem schnellsten und teuersten Block-Tier des Cloud-Speichers und nicht auf dem langsameren, aber preisgünstigeren Cloud-Objekt-Tier. Das Verschieben dieser Daten von einem kostengünstigen Tier ist mit Kosten verbunden, und es dauert eine gewisse Zeit, bis die Kopie vollständig transferiert ist.
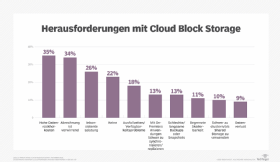
IT-Fachleute müssen für jeden Anwendungsfall entscheiden, wo die Daten zunächst gespeichert werden sollen. Sie müssen auch festlegen, wie die Daten bei Bedarf in eine andere Schicht verschoben werden können.
Nicht alle Cloud-basierten Datenmanagement-Angebote können Daten zwischen Ebenen innerhalb der Cloud übertragen, und noch weniger können Daten automatisiert verschieben. Das Verschieben von Daten zwischen Ebenen kann auch ein Cloud-Datenmanagement-Produkt erfordern, um die Daten in ein Format zu konvertieren, das von Cloud-basierten Anwendungen oder Diensten genutzt werden kann.
Die Entscheidung, wo Daten gespeichert werden sollen, hängt davon ab, wie oft die Cloud-Anwendung die aktuellste Datenkopie benötigt und wie groß der aktualisierte Datensatz ist. Die Cloud-Datenverwaltungsprozesse können der Anwendung am besten dienen, indem sie die Daten direkt auf dem Speicher der Anwendung ablegen, auch wenn der Speicher aus Sicht der Kosten pro Gigabyte teurer ist. Die Kosten für das Verschieben der Daten und die dafür erforderliche Zeit können die Einsparungen im Vergleich zur direkten Speicherung der Daten dort, wo sie benötigt werden, ausgleichen.
Herausforderung 3. Verschieben von Daten zwischen Clouds
Die Bedenken bei diesem Ansatz sind ähnlich wie beim Verschieben von Daten innerhalb einer Cloud, mit der zusätzlichen Sorge um die Konvertierung zwischen den Anbietern. Die I/O-Gebühren für das Verschieben von Daten aus der Cloud heraus sind deutlich höher, wenn Daten zwischen Clouds verschoben werden. Die für einen Umzug erforderliche Zeit ist wahrscheinlich erheblich länger.
Unabhängig davon, wie oft Kunden Daten zwischen Cloud-Anbietern verschieben oder kopieren, müssen sie die damit verbundenen Kosten verstehen. Wenn es sich bei dem Umzug um einen einmaligen Vorgang handelt, kann es für ein Unternehmen günstiger sein, eine neue Kopie in der neuen Cloud aus dem Vor-Ort-Datensatz zu erstellen und dann die Kopie der Daten in der Cloud des ursprünglichen Anbieters zu löschen.
Wenn die Cloud-basierte Anwendung immer die neueste Datenkopie erfordert, kann es für eine Organisation kostengünstiger sein, die Daten zu spiegeln und sie zu Beginn in beide Clouds zu senden. Wenn die Bewegung zwischen den Clouds gelegentlich oder unvorhersehbar ist, ist die Möglichkeit, eine Cloud-zu-Cloud-Migration durchzuführen, eine Voraussetzung und ein zu berücksichtigendes Schlüsselmerkmal.
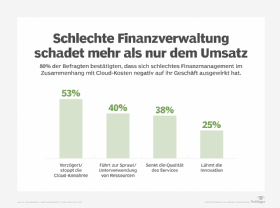
Unternehmen benötigen ein Cloud-Datenverwaltungsprodukt, um Daten an mehrere Cloud-Anbieter zu senden. Obwohl dies eine offensichtliche Anforderung zu sein scheint, unterstützen viele Angebote nur einen Cloud-Anbieter.
Eine zweite Anforderung besteht darin, Daten – vorzugsweise Teilbereiche der Daten – gleichzeitig an zwei verschiedene Clouds zu senden. Schließlich sollte das Produkt die Möglichkeit unterstützen, Daten direkt zwischen Clouds zu verschieben. Auch hier gilt, dass viele Datenmanagementprodukte, auch wenn dies offensichtlich ist, keine direkte Kopie zwischen Cloud-Anbietern durchführen können.
Es ist immer sinnvoll, die Fähigkeit eines Unternehmens zur Datenverwaltung zu verbessern. In der Cloud sind die Vorteile sofort verfügbar. Die Cloud-basierte Datenverwaltung stellt die IT-Abteilung vor eine Reihe einzigartiger Herausforderungen, denen sie sich stellen muss. Der Schlüssel liegt darin zu verstehen, wie Daten in die Cloud gelangen, wie das Unternehmen sie nutzt und wie Daten innerhalb der Cloud und über die Cloud hinweg bewegt werden.







