
Gorodenkoff - stock.adobe.com
Datenmanagement und -schutz in Multi-Cloud-Umgebungen
Datenmanagement und -schutzlösungen für Multi-Cloud-Umgebungen ermöglichen mit KI-Algorithmen vertiefte Geschäftseinsichten und helfen, mehr Kontrolle zu gewinnen.
Unternehmen nutzen heute eine Mischung aus zentralen und Edge-Rechenzentren, privaten und Public-Cloud-Umgebungen. Backup-Administratoren müssen Daten über all diese Ressourcen hinweg kohärent verwalten. Dadurch wandelt sich die Rolle des Backup-Administrators inzwischen hin zum Datenadministrator mit Verantwortung für die Data Protection.
Unterschiedliche Hersteller arbeiten daran, das Multi-Cloud-Datenmanagement ganzheitlicher anzugehen. Insbesondere die Anbieter von Lösungen für Data Protection gehen hier voran, da die nötigen Funktionen natürliche Erweiterungen ihrer bisherigen Kernfähigkeiten sind und daraus hervorgehen. Allerdings ist das volle Anforderungsspektrum des Multi-Cloud-Datenmanagements sehr breit, und es gibt derzeit kein Einzelprodukt, Programm oder System, das alle diese Anforderungen erfüllt.
Datenlokalisierung und -mobilität
Backup-Administratoren müssen sich mehrerer Storage-Infrastrukturen bedienen, um die vielfältigen Anforderungen ihrer Organisationen, etwa sofortige und Hochgeschwindigkeits-Wiederherstellung, langfristige Datenhaltung und Compliance, zu erfüllen.
Das alles lässt sich mit traditionellen Datenschutztechnologien nur zu hohen Kosten realisieren, vor allem, weil Daten in Silos gespeichert werden. Sie lassen sich nicht einfach über die Storage-Infrastrukturressourcen verschieben, so wie es die Zugriffs- und Datenhaltungs-Anforderungen erfordern. Um dieses Problem zu adressieren, investieren viele Anbieter von Datenschutzprodukten in Datenmobilitätslösungen für den Datentransfer zwischen On-Premises- und Cloud-basierten Infrastrukturen. Viele ermöglichen auch die Erzeugung eines zentralisierten Namensraums über diverse Storage-Infrastrukturen hinweg.
Ebenfalls wichtig sind regelbasierte und zunehmend durch KI-Algorithmen optimierte Datenplatzierungs- und Tiering-Funktionen. Ihr hauptsächlicher Wert liegt darin, dass sie die Kosten senken und gleichzeitig alle Leistungsanforderungen erfüllen. Sie stellen sicher, dass die Daten auf einer Storage-Infrastruktur liegen, die die erforderlichen Leistungen beim Datenzugriff bringt. Sobald sie nicht mehr so häufig nachgefragt werden, verschieben sie die Daten auf eine kostengünstigere Ebene der Speicherinfrastruktur.
Ein automatisiertes Data Lifecycle Management sorgt dafür, dass Dateien, wenn nicht mehr benötigt, in Einklang mit den Datenhaltungsanforderungen gelöscht werden. Zudem verbessern solche Funktionen die Datenverfügbarkeit: Sie reduzieren die nötige Zeit, um auf Ausfälle und andere Datenzugriffsanforderungen von Anwendern zu reagieren. Selbst initiierte Datenwiederherstellungen spielen hier ebenfalls eine Rolle.
Datenzugriff, Compliance und Sichtbarkeit
Alle Daten, die eine Organisation erzeugt, speichert und schützt, in einen Katalog zu integrieren, ist eine Kernfunktion der Datenschutzlösungen. Diese Aufgabe wird durch verteilte Datenausweitung (Data Sprawl) erschwert. Als Reaktion kommen nun Lösungen mit ausgefeilten Mechanismen zur Verfolgung der Metadaten sowie zur automatischen Identifikation und Klassifikation von Daten auf den Markt.
Einige Hersteller wenden analytische Mechanismen auf Telemetriedaten an, um Themen wie die Ressourcenauslastung transparent zu machen. Insgesamt erzeugen solche Funktionen mehr Durchblick bezüglich der gespeicherten Daten und darüber, wie diese Daten gespeichert, geschützt und eingesetzt werden. Dieselben Fähigkeiten vereinfachen auch den Zugriffsprozess und bieten schnellere und granulare Wiederherstellungsoptionen.
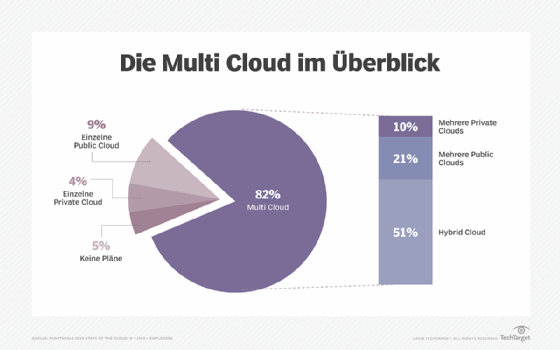
Schließlich, und dieses Thema ist nicht das unwichtigste, kann die durch umfassende Datenmanagementfunktionen erhöhte Transparenz und können die verbesserten Steuerungsmöglichkeiten den Backup-Administratoren dabei helfen, die wachsenden Compliance-Anforderungen zu erfüllen. Zu diesen Fähigkeiten gehören das automatisierte und dokumentierte Failover sowie Failback-Tests und die Möglichkeit, Daten schrittweise wiederherzustellen. Besseres Multi-Cloud-Datenmanagement schützt auch gegen ausgefeilte Cyberangriffsformen wie Ransomware.
Potentielle Risiken des Multi-Cloud-Datenmanagements
Mit ausgeweiteten Datenmanagementfunktionen lässt sich der Datenschutz von einer kostspieligen Absicherungsfunktion in einen Zugangsweg zu neuen geschäftsfördernden Erkenntnissen umwandeln. Allerdings steckt diese Veränderung von Multi-Cloud-Strategien für das Datenmanagement noch in einem frühen Entwicklungsstadium.
Laut einer Studie der Evaluator Group, an der 125 Anwender von Enterprise-Datenschutzlösungen teilnahmen, gaben weniger als 10 Prozent dieser IT-Profis an, dass ihre Organisation bereits Enterprise-Datenmanagement in irgendeiner Form nutzt. Der Markt befindet sich noch in der Entwicklung, was auf das Risiko hinauslaufen kann, Ressourcen beispielsweise zu stark oder zu wenig zu schützen, je nachdem, wie die gewählte Lösung implementiert wird. Das legt schon die Spannweite des Datenmanagements nahe: Es bezieht nicht nur die On-Premises- und Public-Cloud-Ressourcen ein, sondern auch die Ressourcen für Produktionsdaten und die Sekundärspeichersysteme.
37 Prozent der Teilnehmer der oben erwähnten Studie gaben an, sie gingen davon aus, ihre primäre Storage-Umgebung werde die Grundlage einer unternehmensweiten Datenmanagementstrategie werden. Darauf schon folgte mit 21 Prozent Backup. Doch bezüglich dessen gibt es kein Richtig oder Falsch, sondern nur individuell passende Wege. Wichtig ist es aber dass Backup-Administratoren, die strategischen Prioritäten in engem Kontakt mit den vertikalen Geschäftsbereichen planen.
Erfahren Sie mehr über Storage Management
-
![]()
So unterscheiden sich Datendeduplizierung und -kompression
Von: Damon Garn
-
![]()
Dies können Softwareplattformen für Data Protection bieten
Von: Chris Tozzi
-
![]()
Storage für Kubernetes und Container: Eine Herausforderung
Von: Tim McCarthy
-
![]()
Backup unstrukturierter Daten: Darauf muss geachtet werden
Von: Thomas Joos



