
Song_about_summer - stock.adobe.
Big Data Analytics mit Microsoft Azure Synapse Analytics
Mit Microsoft Azure Synapse Analytics können Unternehmen in der Cloud Datenabfragen aus verschiedenen Quellen zentral zusammenfassen und aufbereiten lassen.

Microsoft Azure Synapse Analytics ermöglich die Echtzeit-Analyse von Daten aus verschiedenen Quellen in der Cloud. Gleichzeitig ist die Integration von KI- und Machine-Learning-Lösungen, zum Beispiel Azure Machine Learning, vorgesehen. In Azure Synapse Analytics lassen sich die Daten und Berichte außerdem für die Zusammenarbeit teilen.
Azure Synapse Analytics soll dabei helfen, große Datenmengen schnell und übersichtlich zu analysieren, unabhängig davon, wo diese gespeichert sind.
Dazu kann der Cloud-Dienst auf die Funktionen von Microsoft Azure zugreifen. Data Warehousing, Visualisierung, Data Science und ETL-/ELT-Prozesse lassen sich im Synapse Studio, dem zentralen Arbeitsbereich innerhalb des Services, steuern.
Mit Azure Synapse Analytics erhalten Unternehmen ein Tool, mit dem sie unter anderem ihre wirtschaftlichen Kennzahlen analysieren können. Dabei sollen auch einfach lesbare Berichte und Analysen verfügbar gemacht werden, deren Basis alle relevanten Daten des Unternehmens sind.

Hierfür stehen Dienste wie zum Beispiel Azure Data Share, Microsoft 365/Office 365 sowie Power BI zur Verfügung. Die verschiedenen Datenquellen, die PowerBI unterstützt, sind somit ebenfalls in Azure Synapse Analytics nutzbar. Dienste außerhalb des Microsoft-Ökosystems sind kompatibel mit Azure Synapse Analytics. Microsoft unterstützt darüber hinaus die Open Data Initiative.
Azure Synapse Analytics bietet nach eigenen Angaben eine bessere Performance als Amazon Redshift und Google BigQuery. Nach Testabfragen mit sehr großen Datenmengen soll die Cloud-Lösung schnellere Antworten als die Konkurrenz liefern.
Mit Azure Synapse Analytics Daten analysieren
In Azure Synapse Analytics ist Azure Data Factory integriert. Hier ist das ETL-Tool Mapping Data Flows verfügbar. Generell können damit Daten, ähnlich wie die Integration Services in Microsoft SQL Server, angebunden und analysiert werden. SQL ist als Abfragesprache vorgesehen.
Azure Synapse Analytics lässt sich über das Azure-Portal konfigurieren. Dort erstellt man nach der Anmeldung mit einem Azure-Konto einen neuen Synapse-Arbeitsbereich. Wer Azure und Azure Synapse Analytics zuvor testen möchte, kann die Dienste kostenlos ausprobieren.
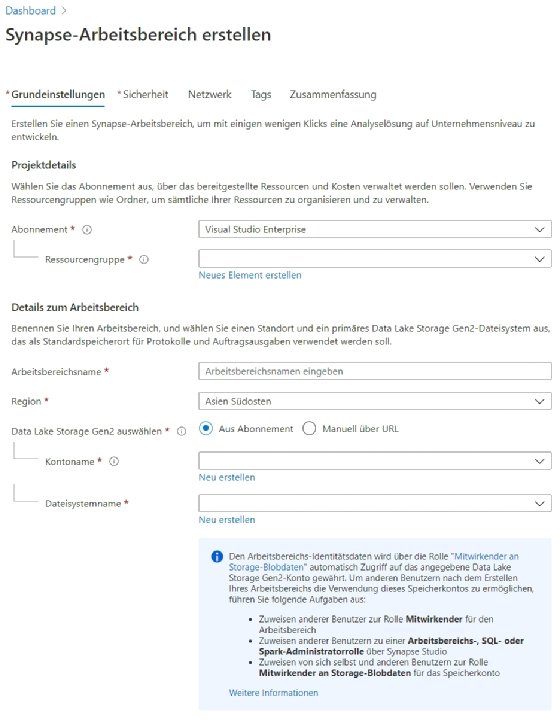
Beim Erstellen des Arbeitsbereiches lässt sich unter anderem Azure Data Lake Storage anbinden. Als Region für das Speichern der Daten kann Deutschland ausgewählt werden. Das spielt für den Datenschutz eine wichtige Rolle. Die Einrichtung des Arbeitsbereiches findet über einen Assistenten statt.
Sobald die Ressource bereitgestellt ist, kann in den Synapse-Arbeitsbereich gewechselt werden. Der wichtigste Bereich in Azure Synapse Analytics ist Synapse Studio. Dieses steht über das Dashboard des Arbeitsbereiches zur Verfügung. Mit dem Synapse Studio erhalten Anwender zentralen Zugriff auf Datenquellen, Pipelines, Analysen und andere Objekte. Die Anbindung an SQL ist genauso möglich wie an Apache Spark.
In Azure Synapse Analytics erfolgt die Abrechnung nach Verbrauch der Rechenkapazitäten. Die Rechendienste müssen nur dann bezahlt werden, wenn diese explizit laufen. Sind die Dienste nicht gestartet, weil sie aktuell nicht benötigt werden, erfolgt keine Abrechnung.
Um auf externe Tabellen zuzugreifen, kommt im Cloud-Dienst häufig PolyBase zum Einsatz. Die komplette Infrastruktur wurde so abgestimmt, dass Analysen so kostengünstig wie möglich sind. Die Abrechnung erfolgt dynamisch, zum Beispiel durch das zeitweise Hinzuschalten oder Deaktivieren nicht benötigter Ressourcen.
Zusätzlich besteht die Möglichkeit, einen Kopierauftrag von Connectoren innerhalb des Arbeitsbereichs zu erstellen. Hier sind die gleichen Connectoren zu finden, die aus Azure Data Factory bekannt sind.
Analyse-Pools erstellen
Über die Menüpunkte SQL-Pools und Apache Spark-Pools lassen sich Pools aus Daten innerhalb von Azure Synapse Analytics erstellen. Hier kann man Spark in die Umgebung integrieren.
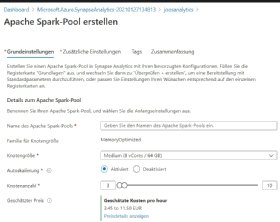
Neben dem dedizierten SQL-Pool können weitere Pools hinzugefügt werden. Damit lassen sich Data Warehouses und deren Funktionen mit Azure Synapse Studio abbilden sowie mehrere Warehouses anbinden. Mit SQL-Pools können Dimensionstabellen eingebunden werden. Hier besteht die Möglichkeit, die Rechenleistung für eine bessere Performance anzupassen oder den SQL-Pool zu pausieren, um Kosten zu sparen.
Mit Data Flow lassen sich Daten bereinigen. Damit sind zum Beispiel häufige Aufgabe wie Joins, Unions, Lookups, Select, Filter, Sort, Alter und weitere Aktionen möglich, ohne dass Code extra geschrieben werden muss.
SQL Script erlaubt es Anwendern, SQL-Anweisungen im Synapse Studio zu erstellen. Hier besteht die Möglichkeit, externe Datenquellen außerhalb des Synapse-Arbeitsbereichs zu verbinden. Dazu gehören zum Beispiel Hadoop, Azure Data Lake oder Azure Blob Storage.
Im Ergebnisfenster der SQL-Abfrage lassen sich schließlich die Ergebnisse visualisieren sowie die Ergebnisse und Diagramme anpassen.






