
Gorodenkoff - stock.adobe.com
Beim Troubleshooting mit Bedacht vorgehen
Wenn IT-Abteilungen sich bei der Fehlersuche und Problembehebung nach bewährten Vorgehensweisen richten, kann dies wertvolle Zeit sparen und Ausfallzeiten reduzieren.

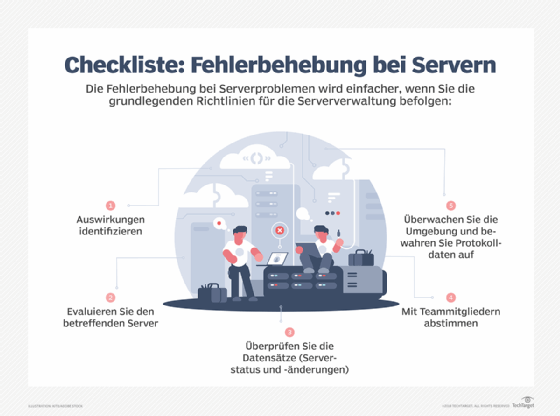
Die Fehlerbehebung bei Servern kann sich gerne mal beliebig komplex gestalten. Mit einigen bewährten Vorgehensweisen lassen sich die Abläufe jedoch einigermaßen reibungslos gestalten.
Methodiken wie ITIL können bei strukturierten Abläufen auch im Hinblick auf die Behebung von Fehlern ein hilfreiches Gerüst liefern. Aber auch ganz allgemein helfen ein paar einfache Regeln dabei, das Problem so schnell und effizient wie möglich einzugrenzen.
Es ist stets hilfreich, Problemen von Anfang an analytisch zu begegnen. Klagt beispielsweise ein Anwender darüber, dass er auf eine bestimmte Ressource nicht zugreifen kann, sollte zunächst geklärt werden, ob dies auf andere Nutzer auch zutrifft. So kann ausgeschlossen werden, dass es sich um ein Problem auf dem Endgerät des Anwenders handelt.
Folgende Tipps sollen dazu anregen, die eigenen Prozesse und Verfahren zur Fehlerbehebung bei Servern auf den Prüfstand zu stellen.
Das Problem und die Folgen eingrenzen
Zunächst gilt es die Auswirkungen und den Umfang des Problems oder Fehlers zu klären. So kann ein beschädigtes Netzwerkkabel die Verbindung zu einem einzelnen Endgerät beeinträchtigen oder aber auch negative Folgen für ein ganzes Segment haben.
Tritt das Problem bei mehreren Nutzern auf, kann man Hardwareprobleme auf einem Endgerät oder Anwenderfehler ausschließen. Falls das Unternehmen über mehrere Standorte verfügt, gilt es zu klären, ob alle gleichermaßen betroffen sind. Damit lässt sich eingrenzen, ob das Problem auf einem der lokalen Server auftritt.
Die Ursachen ermitteln
Bei großen IT-Infrastrukturen und ebensolchen IT-Abteilungen gibt es immer mal wieder die Tendenz, das Problem andernorts zu vermuten. Wenn beim Helpdesk Klagen über eine langsame Anwendung eingehen, verweist der Systemadministrator schon mal auf Netzwerkprobleme. Das Netzwerkadministrator verortet seinerseits die Probleme im Bereich Storage. Der Storage-Verantwortliche gibt hingegen der Anwendung selbst die Schuld. Bei vagen Symptomen, wie einer langsamen Anwendung, gilt es zunächst zu identifizieren, wo genau im Rechenzentrum das aktuelle Problem zu verorten ist. Sind mehrere Server und Anwendungen betroffen, weist dies eher auf Netzwerk- oder Storage-Probleme als auf ein eigentlichen Serverfehler hin. Bei virtualisierten Umgebungen sollte der physische Standort der betroffenen VMs (virtuelle Maschinen) überprüft werden, um sicherzustellen, dass nicht alle dieselbe, möglichweise beeinträchtigte, Hardware nutzen.
Das Ausschlussverfahren hilft dabei, das eigentliche Problem enger einzukreisen. Das klappt nicht immer auf Anhieb und kann sich ebenfalls komplex gestalten. Kombinieren Sie dabei unterschiedliche Faktoren, um die möglichen Ursachen einzugrenzen. Wenn beispielsweise das Kopieren von Dateien von einem Netzlaufwerk auf ein anderes sehr lange dauert, sollte man zunächst das Problem einordnen. Dabei sollten einige Fragen beantwortet werden: Dauert es auch lange, wenn von einem Server auf einen anderen am selben Standort kopiert wird? Wenn ja, dann liegt das Problem nicht am WAN. Ist die Performance auch beeinträchtigt, wenn auf demselben Server über verschiedene Laufwerke kopiert wird? Wenn ja, dann sind SAN oder LAN gleichfalls nicht das Problem. Wenn Sie den Fehler mit I/O-Messungen und anderen Tests weiter einkreisen, kann die Suche auf dem Server selbst durchaus noch einige Zeit in Anspruch nehmen.
Dokumentation richtig einsetzen
Eine saubere Dokumentation der eigenen IT ist im Falle eines Falles nahezu unbezahlbar und ein hilfreiches Werkzeug beim Troubleshooting. Wer die eigene Infrastruktur und Softwaretopologie auf einen Blick überschauen kann und so auch versteht, wie die einzelnen Anwendungen funktionieren und zusammenhängen, kann bei der Fehlerbehebung wertvolle Zeit sparen.
Die Zusammenhänge im Rechenzentrum zu verstehen, ist dabei von elementarer Bedeutung. Wie viele Server sind an jeder Anwendung tatsächlich beteiligt? Was sind die grundlegenden Netzwerkeinstellungen? Welche Infrastruktur ist an welcher Stelle lokalisiert? Die Klärung dieser Fragen kann beispielsweise wichtig sein, wenn zwei Server für eine Anwendung zum Einsatz kommen, bei denen sich die Clients im Rundlaufverfahren (Round Robin) damit verbinden. Wenn nun die Hälfte der Anwender Probleme meldet, können Sie von Anfang an davon ausgehen, dass die Probleme nur auf einem der Server auftreten und dort mit der Lösung ansetzen.
Richtig kommunizieren
Die richtige Kommunikation kann oft der Schlüssel zur Problemlösung sein. Wenn ein Kollege am Vorabend eine Servereinstellung geändert hat, und am nächsten Morgen eine Anwendung nicht wie gewohnt funktioniert, kann die Ursache unter Umständen sehr schnell gefunden werden. In großen Unternehmen werden derlei Eingriffe oft für alle gut zugänglich und bekanntermaßen dokumentiert. Das kann zwar zugebenermaßen aufwendig sein, sich aber durchaus lohnen.
Eine gut strukturierte Kommunikation ist auch dann hilfreich, wenn neue Anwendungen oder andere Änderungen in den produktiven Betrieb gehen. Das hilft bei der proaktiven Überwachung der Umgebung, entsprechende Auswirkungen sind sofort erkennbar. Erfolgt dies nicht, müssen Sie die Ressourcenzuteilung der neuen Anwendung unter Umständen reaktiv nach der Einführung anpassen, wenn sich Anwender über die nicht zufriedenstellende Geschwindigkeit beschweren.
Überwachung und Monitoring
Wenn aussagekräftige und aktuelle Informationen zum Betrieb des Rechenzentrums vorliegen, lässt sich das Problem häufig schnell lokalisieren und lösen. Entsprechende Tools fürs Monitoring existieren für alle Größen und Strukturen von Rechenzentren. Wenn diese Tools alle wichtigen Kennzahlen ständig erfassen, weiß man von Anfang an, ob man sich an den Netzwerkadministrator oder an den Storage-Verantwortlichen wenden muss. Zudem liefern diese Werkzeuge Informationen, die IT-Abteilungen bereits auf künftige Probleme hinweisen, so dass es für den Anwender gar nicht erst zu einem spürbaren Fehler kommt, sondern diese vorab vermieden werden kann.
Zudem können die Tools automatische Benachrichtigungen senden, wenn ein bestimmter Dienst nach definierten Regeln aus dem Takt gerät, oder diesen sogar automatisch neu starten.
Der richtige Umgang mit Log-Dateien
Zugegeben, wenn ein Fehler auftritt, gehen viele ITler davon aus, dass sie auf Anhieb wissen, was die eigentliche Ursache ist. Nachfolgend verbringen die Techniker dann Stunden damit, zu beweisen, dass ihre Theorie auch der Realität entspricht. Oft würde ein Blick in die Protokolldateien genügen, um festzustellen, dass die eigentliche Ursache des Problems schon dokumentiert ist. Gibt es beispielsweise ein Berechtigungsproblem, wenn zwei Dienste miteinander kommunizieren müssen, lässt sich dies anhand der Log-Dateien der entsprechenden Konten meist leicht ablesen.
So liefern die Ereignisanzeige unter Windows die Systemprotokolle unter Linux wertvolle Informationen. Dort finden sich oftmals gute Hinweise auf die eigentliche Fehlerursache. Sichern Sie die entsprechenden Log-Dateien an einem sicheren Speicherort, um auch langfristig das Verhalten der Server nachvollziehen zu können.
Die Bedingungen der SLAs kennen
Manche Admins scheuen sich davor, Supportanfragen an den jeweiligen Anbieter der betroffenen Lösung zu stellen. Nach dem die grundlegenden Informationen zum aufgetretenen Problem erfasst und geklärt sind, bietet es sich durchaus an, direkt mit dem Hersteller Kontakt aufzunehmen, anstatt mehrere Stunden damit zu warten.
Dafür sollte man sich jedoch in Zeiten, in denen weniger Probleme anliegen, mit den Service Level Agreements (SLAs) der einzelnen Anbieter beschäftigen. Wenn bestimmte Reaktionszeiten festgelegt sind, etwa am nächsten Werktag, dann muss das in die Abläufe einkalkuliert werden, um Verzögerungen zu vermeiden.
Zudem stellen viele Hersteller online Lösungen für bestimmte Probleme bei ihren Produkten parat. Checken Sie die Wissensdatenbanken und FAQs der Anbieter, ob das betroffene Problem dort Erwähnung findet. Es ist für IT-Abteilungen durchaus frustrierend, wenn die Fehlersuche und -behebung auf dem Server länger dauert. Im Falle eines Falles sollte man sich nicht scheuen, entsprechende Hilfe hinzuzuziehen.
Folgen Sie SearchDataCenter.de auch auf Twitter, Google+, Xing und Facebook!






