
3dkombinat - stock.adobe.com
Azure, Google, Amazon: Vergleich der SAP-Backup-Optionen
SAP-HANA-Datenbanken lassen sich auch in der Public Cloud sichern. AWS, Microsoft Azure und Google Cloud bieten hierfür entsprechende Agenten, die wir hier kurz vergleichen.

SAP HANA ist wohl eine der bekanntesten und weit verbreiteten Datenbanken, die derzeit zur Verfügung stehen. Die hier erzeugten Daten müssen natürlich auch durch ein Backup gesichert werden, so dass sie in einem Notfall mit der Sicherungskopie zügig wiederherzustellen sind.
Zunächst gab es hier nur die Möglichkeit der lokalen Sicherung, aber mit dem Aufkommen von Public-Cloud-Diensten gibt es nun auch die Option, SAP-HANA-Daten in der Cloud abzulegen. Die drei großen Cloud-Anbieter Amazon Web Services, Google Cloud Plattform und Microsoft Azure bieten hierfür spezielle Lösungen an, die in diesem Beitrag kurz beleuchtet werden sollen.
AWS Backint Agent for SAP HANA
AWS Backint Agent for SAP HANA ist eine SAP-zertifizierte Backup- und Recovery-Anwendung, bei der die SAP-HANA-Workloads auf Amazon EC2 in der Cloud gespeichert werden. Der Agent fungiert als Standalone-Applikation und integriert sich mit existierenden Workloads, um die SAP-Daten nach Amazon S3 zu verschieben. Für eine Wiederherstellung kann SAP HANA Cockpit, SAP HANA Studio und SQL Commands genutzt werden.
Der Agent unterstützt vollständige, inkrementelle und differentielle Backups. Darüber hinaus können Log Files und Kataloge in Amazon S3 sichern. Der Agent läuft dabei auf einer SAP-HANA-Datenbank und die Backups und Kataloge werden an den Backint-Agenten gesendet.
Der AWS Backint-Agent speichert Ihre Dateien in dem Amazon S3-Bucket, das in der Konfigurationsdatei des Agenten angegeben ist. Bei einer Wiederherstellung liest SAP HANA mittels des Agenten die in dem S3-Bucket gesicherten Katalogdateien. Danach wird eine Anfrage zur Wiederherstellung der erforderlichen Dateien aus S3 initiiert. Für die Sicherung mit AWS Backint kann der Administrator den AWS Launch Wizard nutzen. Der Wizard hilft dabei, Dimensionierung, Konfiguration und Bereitstellung von SAP-Anwendungen auf AWS umzusetzen, und stellt Best Practises zur Verfügung.
Der Agent kann über die AWS Systems Manager (SSM)-Konsole auf den SAP-HANA-Instanzen bereitgestellt werden. Von der AWS SSM-Konsole aus wird ein AWS SSM-Dokument auf den Instanzen ausgeführt, um den Agenten zu installieren. In dem Dokument gibt der Administrator die Konfigurationsinformationen als Parameter an.
Allerdings lässt sich der Agent auch herunterladen und manuell installieren und konfigurieren. Nach der Installation kann der Nutzer seine Datenbank direkt in S3 sichern. Der Anbieter verspricht hohe Skalierbarkeit durch das parallele Ausführen von Backup- und Recovery-Prozessen, was auch besseren Durchsatz und reduzierte RTO-Werte gewährleisten soll.
Unterstützte Betriebssysteme sind SUSE Linux Enterprise Server, SUSE Linux Enterprise Server for SAP und Red Hat Enterprise Linux for SAP. Die Lösung bietet zudem Support für die Datenbanken SAP HANA 1.0 SP12 (Single oder Multi Node) und SAP HANA 2.0 und spätere Versionen, auch jeweils als Single oder Multi Node. Der Agent ist kostenfrei, der Anwender zahlt nur für die darunter liegenden AWS-Services, zum Beispiel für Amazon S3. Eine genaue Erläuterung der Preismodelle der drei große Cloud-Anbieter und worauf sie hier achten müssen, finden sie in diesem Artikel. Der Agent ist in allen Amazon-Regionen erhältlich.
Installation und Konfiguration
Der AWS Backint-Agent lässt sich auf drei Arten installieren: Mithilfe des AWS Systems Manager-Dokuments, mittels des AWS Backint Installers im interaktiven Modus oder mit dem Installer im stillen Modus. Wir fokussieren an dieser Stelle auf die Installation mit dem AWS SSM-Dokument. Der Hersteller gibt eine deutliche Empfehlung, bevor man diese Installation startet: Jegliche bestehenden Backup-Prozesse sollten deaktiviert sein, inklusive der Log-Backups. Sind diese Sicherungsprozesse nicht deaktiviert bevor das SSM-Dokument genutzt wird, so könnte es zu Korruption von laufenden Backups kommen, was natürlich mögliche Wiederherstellungen gefährdet.
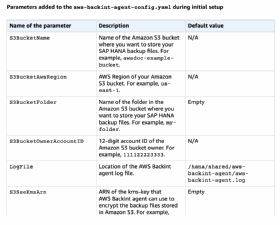
Im ersten Schritt wählt der Admin „System Manager“ unter „Management & Governance“ in der AWS-Management-Konsole aus. Dies lässt sich auch durch eine Suche nach Systems Manager in den „Find Services“ umsetzen. In der Systems-Manager-Konsole wird dann „Documents“ unter „Shared Resources“ in der linken Navigationsleiste ausgewählt. Auf der Dokumentenseite findet der Anwender ein Dokument mit dem Namen „AWSSAP-InstallBackint“ unter dem Reiter „Owned by Amazon“. In diesem Dokument wird dann „Run command“ ausgewählt. Hier werden dann die folgenden Kommandoparameter eingegeben:
- Bucket Name. Hier wird der Name des S3-Buckets angegeben, auf dem das SAP-HANA-Backup gespeichert werden soll.
- BucketFolder. Optional kann der Admin hier den Namen des Ordners im S3-Bucket eintragen, in dem die Daten gesichert werden.
- System ID. Hier füllt der Nutzer die ID des SAP-HANA-Systems ein, zum Beispiel HDB.
- Bucket Region. Hier wird die AWS-Region des AmazonS3-Buckets angegeben, in der die Backups gespeichert werden sollen. Der AWS Backint-Agent unterstützt regionen- und kontoübergreifende Sicherungen. Dafür muss man die AWS-Region und die Konto-ID des Eigentümers des Amazon S3-Buckets zusammen mit dem Namen des Amazon S3-Buckets angeben, damit der Agent erfolgreich arbeiten kann.
- Bucket Owner Account ID. Hier befindet sich die Account-ID des S3-Bucket.
- Kms Key. Der Admin muss hier den Amazon-Ressourcen-Namen von AWS KMS eingeben, damit der Backint-Agent die Backup-Daten verschlüsseln kann.
- Installation Directory. Hier steht der Pfad des Directory-Standorts, auf dem der Agent installiert werden soll. Dabei empfiehlt der Anbieter, nicht den Pfad /tmp zu nutzen.
- Agent Version. An dieser Stelle muss die Versionsnummer des zu installierenden Agenten eingetragen werden. Wird hier keine Versionsnummer angegeben, wird die letzte veröffentlichte Version des Agenten installiert.
- Modify Global ini file. Der Admin wählt hier, wie er die global.ini-Datei modifiziert haben will. Diese Datei der SAP HANA SYSTEM DB muss aktuell sein, damit das Setup abgeschlossen werden kann. Es gibt drei Arten dies zu tun: „modify“, „sql“ oder „none“.
modify – SSM aktualisiert die globa.ini-Datei sofort aktualisieren.
sql – SSM erstellt eine Datei namens modify_global_ini.sql mit SQL Statements. Diese Datei läuft auf dem SAP-HANA-Zielsystem, wo dann die nötigen Parameter definiert werden. Die Datei modify_global_ini.sql ist im Ordner <installation directory>/aws-backint- agent/ zu finden.
none – Hierbei unternimmt der SSM keine Änderungen der global.ini-Datei. Der Admin muss dann die Datei manuell aktualisieren, um das Setup abzuschließen.
- Ignore Bucket Checks. Man wählt hier „yes“, damit die Unbedenklichkeitsprüfungen (Sanity Checks) des S3-Bucket ignoriert werden. Diese Überprüfungen verifzieren üblicherweise, dass der Bucket im Account existiert, dass die Bucket-Region korrekt ist sowie dass der Bucket öffentlich (public) ist.
- Debug Mode. Um diesen Modus zu aktivieren, wählt der Admin „yes“ aus.
- Keine laufenden Backups. Erneut muss hier ein „Yes“ ausgewählt werden, mit dem bestätigt wird, dass sämtliche Backup-Prozesse deaktiviert wurden und die Installation ausgeführt werden kann. Wird hier „No“ ausgewählt, so wird das SSM-Dokument keine erfolgreiche Installation durchführen.
Unter „Target“ selektiert man die Installationsmethode für den Agenten und dann die Instanz, auf der er installiert wird. Falls sich die Instanz nicht finden lässt, muss der Admin prüfen, ob er alle vorbereitenden Schritte richtig ausgeführt hat. Dazu gehört unter anderem die Installation des SSM-Agenten.
Das Feld „Other Parameters“ wird das Feld freigelassen und „Run“ ausgewählt. Auch hier gibt es eine Warnung des Anbieters: Ist der SSM-Agent nicht auf den aktuellen Stand, so wird der Run-Befehl fehlschlagen. Wurde der Agent erfolgreich installiert, so sieht der Admin dies als „Success“-Status unter der Comman ID.
Die Installation kann man überprüfen, indem man sich bei seiner Instanz anmeldet und das Verzeichnis /<Installationsverzeichnis>/aws- backint-agent öffnet. Dort finden sich die Dateien AWS-Backint-Agent-Binärdatei, THIRD_PARTY_LICENSES.txt (enthält die Lizenzen der vom Agenten verwendeten Bibliotheken), das Launcher-Skript, die YAML-Konfigurationsdatei und modify_global_ini.sql (optional). Darüber hinaus ist im Paketverzeichnis eine Quelldatei (aws-backint-agent.tar.gz) des AWS Backint-Agenten gespeichert.
Das SSM-Dokument erstellt symbolische Links (Symlinks) im globalen SAP HANA-Verzeichnis für die Backint-Konfiguration. Der Admin muss sicherstellen, dass der Symlink für hdbbackint im Verzeichnis /usr/sap/<SID>/ SYS/global/hdb/opt und der Symlink für aws-backint-agent-config.yaml im Verzeichnis /usr/sap/<SID>/SYS/global/hdb/opt/hdbconfig existiert.
Die Installation mit dem Backup-Installer ist etwas komplexer, da hier über Befehlszeilen gearbeitet werden muss. Darüber hinaus lässt sich auch eine Proxy-Adresse für die Installation nutzen. Nach der Installation stehen dem Admin natürlich zahlreiche Konfigurationsoptionen zur Verfügung, wie die Nutzung anderer S3-Buckets oder kürzerer Pfade sowie Leistungsoptimierung. In diesem Beitrag soll aber nur das Backup und Restore eines SAP-HANA-Systems beleuchtet werden.
Backup und Recovery
Das Backup und Recovery von SAP-HANA-Datenbanken kann in drei verschiedenen Verfahren umgesetzt werden: Mit SQL-Statements, mit SAP Cockpit oder mit SAP Studio. Wir betrachten hier einige Beispiele mit SQL-Statements. Im Folgenden listen wir einige Befehlszeilen, mit denen sich Backups und Recoverys initiieren lassen. Mit dieser Syntax stößt der Admin ein vollständiges Backup (Full Backup) der Systemdatenbank an:
BACKUP DATA USING BACKINT ('/usr/sap/<SID>/SYS/global/hdb/backint/SYSTEMDB/<MY_PREFIX>')
Für ein inkrementelles Backup einer Tenant-Datenbank sieht der Befehl so aus:
BACKUP DATA INCREMENTAL FOR <TENANT DB ID> USING BACKINT ('/usr/sap/<SID>/SYS/global/hdb/
backint/DB_<TENANT DB ID>/<MY_PREFIX >')
Für die Tenant-Datenbank lassen sich natürlich auch vollständige und differenzielle Datensicherungen einrichten. Die Wiederherstellungsoptionen sind vielfältig und einige sind nachfolgend aufgelistet. Um Daten eines bestimmten Zeitpunktes einer Tenant-Datenbank wiederherzustellen, gibt der IT-Verantwortliche diese Zeilen ein:
RECOVER DATABASE FOR <TENANT DB ID> UNTIL TIMESTAMP 'YYYY-MM-DD HH:MM:SS' USING DATA PATH
('/usr/sap/<SID>/SYS/global/hdb/backint/DB_<TENANT DB ID>/') USING LOG PATH ('/usr/sap/
<SID>/SYS/global/hdb/backint/DB_<TENANT DB ID>') USING BACKUP_ID 1234567890123 CHECK ACCESS
USING BACKINT
Das folgende Beispiel zeigt die Syntax zur Wiederherstellung einer Tenant-Datenbank mit einem spezifischen Backup unter Verwendung von in S3 gespeicherten Katalogen.
RECOVER DATA FOR <TENANT DB ID> USING BACKUP_ID 1234567890123 USING CATALOG BACKINT USING
DATA PATH ('/usr/sap/<SID>/SYS/global/hdb/backint/DB_<TENANT DB ID>/') CLEAR LOG
Ohne den Katalog zu nutzen, sieht der Befehl so aus:
RECOVER DATA FOR <TENANT DB ID> USING BACKINT ('/usr/sap/<SID>/SYS/global/hdb/backint/
DB_<TENANT DB ID>/<MY_PREFIX >') CLEAR LOG
Mit dem AWS-Backint-Agent lassen sich Systemkopien anlegen, indem ein Backup der Quelldatenbank in der Zieldatenbank wiedergestellt wird. Um dies durchführen zu können, müssen einige Bedingungen erfüllt sein. So muss der Agent auf beiden Systemen installiert und konfiguriert sein. Ebenso die Kompatibilität der SAP-HANA-Softwareversionen von Quell- und Zielsystem überprüft und sichergestellt sein.
Der AWS-Backint-Agent auf dem Zielsystem sollte auf den Amazon S3-Bucket zugreifen können, in dem die Backups des Quellsystems gespeichert sind. Wenn der Anwender im Quell- und Zielsystem einen anderen Amazon S3-Bucket für Sicherungen verwendet, muss er die Konfigurationsparameter des AWS Backint-Agenten im Zielsystem so anpassen, dass er vorübergehend auf den Amazon S3-Bucket verweist, in dem die Sicherungen im Quellsystem gespeichert sind.
Wird eine Systemkopie über verschiedene AWS-Konten ausgeführt, muss gewährleistet sein, dass die entsprechenden IAM-Berechtigungen und Amazon S3-Bucket-Richtlinien eingerichtet sind.
RECOVER DATA FOR <TARGET TENANT DB ID> USING SOURCE '<SOURCE TENANT DB ID>@<SOURCE SYSTEM
ID>' USING BACKUP_ID 1234567890123 USING CATALOG BACKINT USING DATA PATH ('/usr/sap/
<SOURCE SYSTEM ID>/SYS/global/hdb/backint/DB_<SOURCE TENANT DB ID>/') CLEAR LOG
Mit diesem Befehl stellt man ein spezifisches Backup eines Quellsystems (Tenant) auf dem Zielsystem (Tenant) wieder her. Das nächste Beispiel zeigt eine SQL-Anweisung zur Wiederherstellung eines bestimmten Backups der Quelldatenbank SRC im Quellsystem QAS in der Zieldatenbank TGT.
RECOVER DATA FOR TGT USING SOURCE 'SRC@QAS' USING BACKUP_ID 1234567890123 USING CATALOG
BACKINT USING DATA PATH ('/usr/sap/QAS/SYS/global/hdb/backint/DB_SRC/') CLEAR LOG
Es folgt ein Beispiel für eine SQL-Anweisung zur Durchführung einer Point-in-Time-Wiederherstellung einer Quell-Tenant-Datenbank namens SRC in einem Quellsystem QAS in einer Ziel-Tenant-Datenbank namens TGT.
RECOVER DATABASE FOR TGT UNTIL TIMESTAMP '2020-01-31 01:00:00' CLEAR LOG USING SOURCE
'SRC@QAS' USING CATALOG BACKINT USING LOG PATH ('/usr/sap/QAS/SYS/global/hdb/backint/
DB_SRC') USING DATA PATH ('/usr/sap/QAS/SYS/global/hdb/backint/DB_SRC/') USING BACKUP_ID
1234567890123 CHECK ACCESS USING BACKINT
Wie bereits erwähnt, können Backups und Wiederherstellungen auch mit SAP HANA Cockpit oder SAP HANA Studio durchgeführt werden. Auch hier wird mit entsprechenden Befehlen gearbeitet. Der Administrator kann zudem den Status von Backups und Recoverys abfragen, Datensicherungen zeitlich festlegen und verwalten sowie eine Richtlinie definieren, wie lange Backup-Daten vorgehalten werden sollen.
Die vollständige Dokumentation, wie der AWS-Backint-Agent zu nutzen ist, finden Sie hier.
Google Cloud Storage Backint-Agent für SAP HANA
Google bietet ebenso einen Backint-Agenten für SAP-HANA-Datenbanken, um Backups in der Cloud zu ermöglichen. Dabei ist es unerheblich ob die Datenbanken in einer Bare-Metal-Lösung, am lokalen Standort oder in einer andere Cloud-Plattform abgelegt sind. Der Agent ermöglicht es, Backups mit den nativen SAP-Funktionen für Sicherungen und Wiederherstellungen in Google Cloud Storage zu speichern und von dort abzurufen.
Allerdings weist der Anbieter darauf hin, für den Agenten keinen nichtflüchtigen Speicher zu verwenden. Das soll dafür sorgen, dass bei einem Abbruch der Stromzufuhr – gewollt oder ungewollt – der Agent nach wie vor gespeichert ist und genutzt werden kann.
Google gibt zudem eine Liste zertifizierter Drittanbieter an, deren Tools mit dem Backup verbunden werden können, beispielsweise von Actifio, Commvault, IBM, Rubrik oder Veeam. Die vollständige Liste ist hier zu finden. Darüber hinaus steht dem Anwender eine Übersicht zum Agenten unter diesem Link zur Verfügung.
Auch bei Google legt der Anwender Parameter in einer Klartextdatei fest, um den Backint-Agenten zu konfigurieren. Die Standardkonfigurationsdatei heißt parameters.txt und der Standardspeicherort ist /usr/sap/SID/SYS/global/hdb/opt/backint/backint-gcs/parameters.txt. Beim ersten Herunterladen sind nur zwei Parameter festzulegen: #Bucket und #Disable_Compression. Zu weiteren abgefragten Parametern gehören:
- #BUCKET (Bucket-Name)
- #CHUNK_SIZE_MB (Größe von HTTPS-Anfragen während Backup- und Recovery-Proessen)
- #DISABLE_COMPRESSION (Komprimierung deaktivieren oder aktivieren)
- #ENCRYPTION_KEY (Pfad zum Verschlüsselungsschlüssel des Kunden)
- #KMS_KEY_NAME (Pfad zu einem Vom Kunden verwalteten Verschlüsselungsschlüssel)
- #MAX_GCS_RETRY (Definiert, wie oft der Backint-Agent einen fehlgeschlagenen Versuch, in Cloud Storage zu lesen und zu schreiben, wiederholt.)
- #PARALLEL_FACTOR (ermöglicht parallele Uploads)
- #PARALLEL_PART_SIZE_MB (Größe in MB für parallele Uploads)
- #RATE_LIMIT_MB (Obergrenze in MB für die ausgehende Bandbreite von Compute Engine während Backup- oder Recovery-Prozessen)
- #SERVICE_ACCOUNT (Pfad zum JSON-codierten Google-Cloud-Dienstkontoschlüssel)
- #THREADS (Anzahl der Worker-Threads)
- #READ_IDLE_TIMEOUT (maximale Zeit in Millisekunden, die der Backint-Agent wartet, bevor er die Sicherungsdatei öffnet)
Es lassen sich multiple Konfigurationsdateien angeben, wobei jede Datei einen anderen Namen erhält. So könnte eine Konfiguration für Log-Backups in einer Datei namens backint-log-backups.txt und eine Konfiguration für Datensicherungen in einer Datei namens backint-data-backups.txt angelegt werden.
Wie auch bei Amazon speichert der Agent die Backups in einem Bucket. Hier kann der Admin den Standort und die Speicherklasse des Buckets auswählen. Der Standort kann regional, dual-regional oder multiregional sein. Die Wahl wird dabei von den spezifischen Anforderungen an Latenz, Redundanz oder Data Protection bestimmt.
In der Regel umgeht der Agent Proxy-Server, aber auch hier besteht die Option, Backups über einen Proxy zu senden. Dafür muss der Admin die Parameter für Proxy-Host und Portnummer in der Datei /usr/sap/SID/SYS/global/hdb/opt/backint/backint-gcs/jre/conf/net.properties eintragen. Eine Skalierung mit dem Agenten kann über das Hinzufügen von weiteren Knoten, die ebenso den Agenten installiert haben.
Weitere Funktionen, die sich mit dem Backint-Agenten einrichten sind unter anderem Multi-Streaming-Backups, parallele Uploads, Authentifizierung und Zugriffskontrolle sowie Backup-Verschlüsselung und Logging.
Vor der Installation des Agenten, muss zunächst der Storage Bucket erstellt werden. Dies lässt sich in einfachen Schritten umsetzen, wie es in Abbildung 2 zu sehen ist.

Der Agent wird in demselben freigegebenen Dateisystem wie die SAP HANA-Datenbank installiert. Dann muss der Admin eine SSH-Verbindung zum SAP-HANA-Host herstellen und zum SAP-HANA-Systemadministrator wechseln: sudo su – sid adm. Der Agent wird mit folgendem Befehl heruntergeladen und installiert:
curl -O https://storage.googleapis.com/cloudsapdeploy/backint-gcs/install.sh
chmod +x install.sh
./install.sh
Danach werden verschiedene Aktionen durch das Skript install.sh ausgeführt, darunter die Installation des Agenten als JAR-Datei, das Herunterladen einer kompatiblen Version der Java-Laufzeitumgebung und das Einrichten des backint-Skriptes. Bei Bedarf lässt sich ein Dienstkonto einrichten, beispielsweise, wenn der Backint-Agent auf einer Bare-Metal-Lösung läuft.
Der Konfigurationsprozess erfolgt wie unter AWS, indem die Parameter als erstes in die Klartext-Konfigurationsdatei eingegeben werden. Wenn gewünscht, kann der Administrator auch einen Proxy-Server einrichten. Generell bietet der Agent natürlich die gleichen Funktionalitäten wie unter AWS. Die vollständigen Installationsinformationen finden sich unter diesem Link.
Microsoft Azure Backup für SAP-HANA-Datenbanken
Die Lösung von Microsft Azure sichert Datenbanken, die auf virtuellen Azure-Maschinen laufen. Dafür ist Azure Backup Backint-zertifiziert, was die Nutzung des Agenten ermöglicht. Der Anbieter verspricht zahlreiche Vorteile, darunter Recovery Point Objectives von 15 Minuten, schnelle Zeitpunktwiederherstellungen, Compliance-konforme Langzeitaufbewahrung und einfache Backup-Verwaltung.
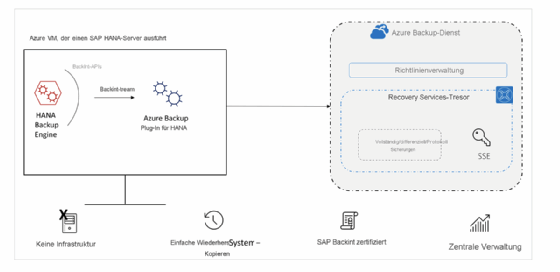
Die zu sichernden Datenbanken benötigen eine zuverlässige Verbindung zum Azure Backup-Dienst, zu Azure Storage und zu Azure Active Directory. Dies kann über private Endpunkte, Netzwerksicherheitsgruppen, Azure-Firewall-Tags oder über FQDNs erfolgen. Die Nutzung eines Proxy-Servers ist bei Azure auch umsetzbar.
Backup einrichten
Im ersten Schritt muss ein Recovery Services-Tresor eingerichtet werden. Dies ist eine Verwaltungsentität, auf der die kreierten Wiederherstellungspunkte gespeichert sind. Der Tresor stellt die Benutzeroberfläche zur Verfügung, von der aus alle Backup-relevanten Prozesse durchgeführt werden, zum Beispiel Backups, Recoverys und das Einrichten von Backup-Policys.
Für das Einrichten eines Tresors meldet sich der Admin in seinem Abo beim Azure-Portal an und sucht nach dem Backup Center im Dashboard. Auf der Overview-Seite findet er verschiedene Optionen im Kopfmenü, aus denen er Vault auswählt (Abbildung 4).
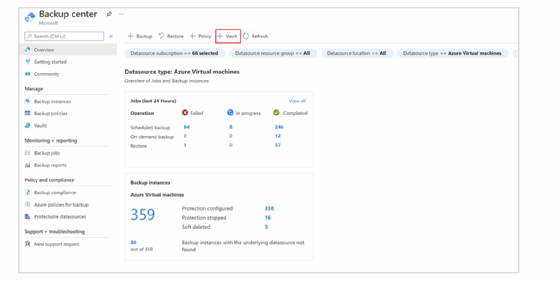
Klickt der Anwender auf weiter, landet er auf der Seite Start: Create Vault und kann hier zwischen einem Recovery Services vault oder einem Backup vault wählen. Für SAP benötigen Unternehmen das Recovery Services Vault. Hier müssen zusätzlich noch das Abonnement, die Ressourcengruppe, der Tresorname und die Region angegeben werden. Sind diese Parameter eingetragen, geht es mit Review + create weiter. Nach der Überprüfung der Angaben, wird der Tresor mit Create erstellt. Der Status des Erstellungsprozesses lässt sich im Benachrichtigungsbereich des Portals nachverfolgen.
Die Lösung ermöglicht regionsübergreifende Wiederherstelllungen, die der Admin aktivieren muss. Dazu wählt er auf der Overview-Seite den Reiter Backup aus. Danach gibt man als Datenquellentyp SAP HANA auf Azure-VM an und wählt den Tresor aus. Mit einem Klick auf Weiter landet der Admin auf der Seite Start: Sicherung konfigurieren.
Im Anschluss erscheint die Oberfläche Backup Goal, auf der eingetragen wird, wo die Workload läuft (Azure) und was gesichert werden soll SAP HANA in Azure VM). Ebenso gibt es hier den Button Start Discovery, mit dem die Suche nach ungeschützten VMs angestoßen wird. Die Lösung listet die in der Tresorregion gefundenen VMs auf.
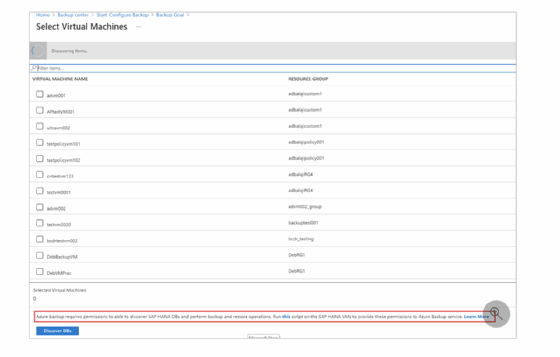
Auf der Seite Select Virtual Machines wird zunächst das Skript heruntergeladen, das dem Azure Backup-Dienst Berechtigungen zum Zugreifen auf die SAP HANA-VMs für die Ermittlung von Datenbanken erteilt. Das Skript wird auf der virtuellen Maschine ausgeführt, die die SAP-Datenbanken hostet. Über die Schaltfläche Discover DBs werden alle Datenbanken dieser VM aufgelistet und der Admin wählt die aus, für die das Backup eingerichtet werden soll (Abbildung 5).
Nach diesem Schritt lässt sich das Backup selbst konfigurieren. Dafür wird auf Configure Backup geklickt. Es erscheint der Bildschirm Select items to backup, auf der die Datenbanken ausgewählt werden. Auf der nächsten Oberfläche befinden sich dann die weiteren Backup-Parameter wie die Backup Policy und deren Details wie die Backup-Frequenz und verschiedene Aufbewahrungsangaben (Abbildung 6).
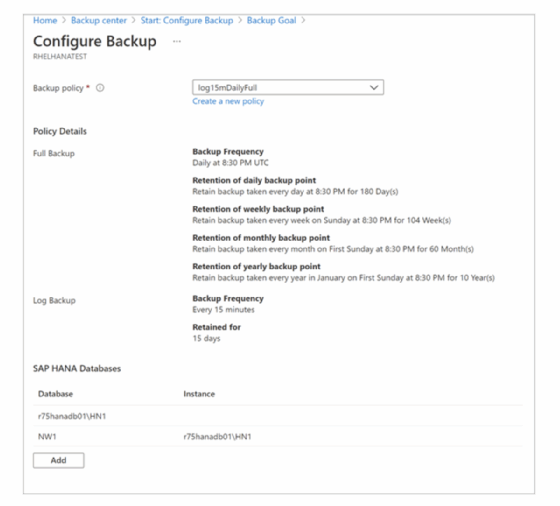
Im Menü Backup wird dann die Datensicherung über Enable backup aktiviert. Auch hier lässt sich der Konfigurationsfortschritt im Bereich Benachrichtigungen nachverfolgen. Ist dieser Schritt abgeschlossen, erfolgt die Einrichtung der einzelnen Details wie zum Beispiel der Backup-Frequenz (Abbildung 7).
Darüber hinaus kann der Admin über dieses Tool auch differenzielle und inkrementelle Backups sowie das Log-Backup einrichten. Für ein Backup, dass nur bei Bedarf ausgeführt werden soll, gibt Microsoft die folgenden Konfigurationsschritte an:
- Wählen Sie im Tresormenü die Option Sicherungselemente aus.
- Wählen Sie unter Sicherungselemente den virtuellen Computer, auf dem die SAP HANA-Datenbank ausgeführt wird, und dann Jetzt sichern aus.
- Wählen Sie in Jetzt sichern den Sicherungstyp aus, den Sie durchführen möchten. Klicken Sie anschließend auf OK. Diese Sicherung wird für 45 Tage aufbewahrt.
- Überwachen Sie die Portalbenachrichtigungen. Sie können den Auftragsstatus im Dashboard des Tresors unter >Sicherungsaufträge>In Bearbeitung überwachen. Je nach Größe Ihrer Datenbank kann das Erstellen der ersten Sicherung einige Zeit dauern.
Hier ist allerdings zu beachten, dass der Anbieter die Menüpunkte und Befehle in deutsch angibt, die Nutzeroberfläche aber in Englisch gestaltet ist, worauf der Backup-Verantwortliche achten muss. Die vollständigen Anweisungen für das Einrichten des SAP-Backups sind unter diesem Link nachzulesen.
Recovery durchführen
Es gibt verschiedene Wiederherstellungsoptionen für die SAP-HANA-Datenbanken. So kann zum einen ein bestimmtes Datum oder eine Uhrzeit mit Log-Backups wiederhergestellt werden. Azure Backup ermittelt dafür die richtige vollständige differenzielle Sicherung.
Darüber kann der Admin eine bestimmte differenzielle Sicherung auswählen, um gezielt ein Recovery eines Wiederherstellungspunktes zu unternehmen. Dazu muss die SA-Instanz aber in der gleichen Region angesiedelt und die Zielinstanz im gleichen Vault wie die Quelle registriert sein. Der Administrator muss zuvor dafür sorgen, dass die Ziel-Instanz für das Recovery bereit ist, indem er die Sicherungsbereitschaft überprüft.
Danach kann die Wiederherstellung der Datenbank erfolgen, wofür zuvor bestimmte Berechtigungen eingerichtet sein müssen, zum Beispiel die des Sicherungsoperators im Recovery-Vault.
Für das Recovery wählt der Admin im Backup Center den Reiter Restore aus (Abbildung 8).
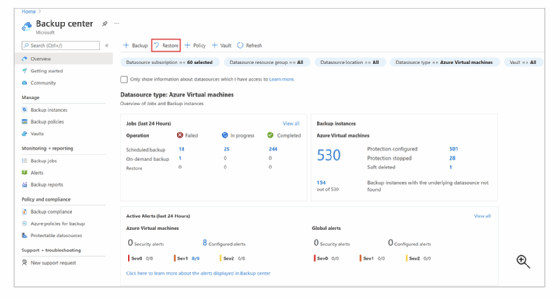
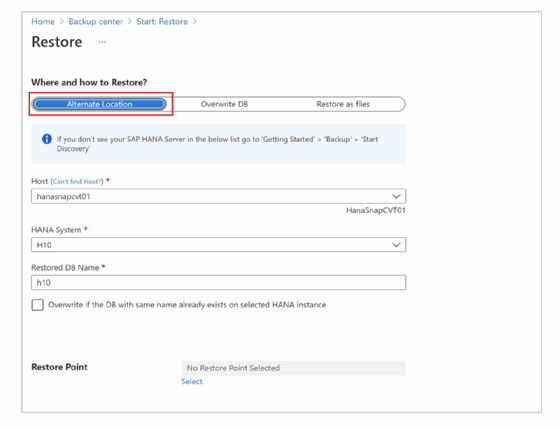
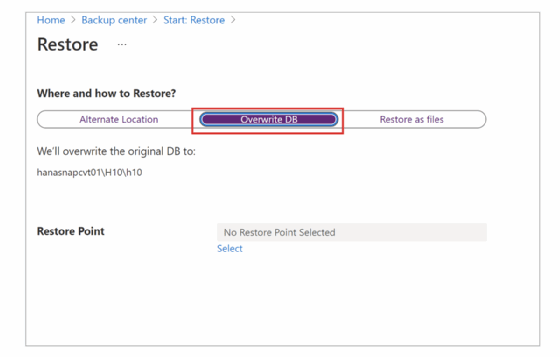
Danach wählt er SAP HANA in Azure-VM als Datenquellentyp und die Datenbank aus, die er wiederherstellen will, und klickt auf Weiter. Im darauf erscheinenden Restore-Fenster gbt der Anwender an wo oder wie er die Daten wiederherstellen möchte (Where and how to Restore). Dabei stehen Alternate Location (alternativer Speicherstandort), Overwrite DB (Datenbank überschreiben) oder Restore as files (Wiederherstellung als Dateien) zur Verfügung.
Wählt man den alternativen Speicherstandort, so muss der IT-Verantwortliche zunächst den SAP-HANA-Host-Namen und die Zielinstanz definieren. Letztere muss natürlich für ein Recovery bereitstehen. Unter Restored DB Name wird der Name der Zielinstanz eingetragen. Im Feld Restore Point kann dann angegeben werden, ob ein bestimmter Zeitpunkt (Protokolle) oder Wiederherstellungspunkt (vollständig oder differenziell) das Ziel des Recoverys ist (Abbildung 9).
Für das Wiederherstellen und Überschreiben, klickt der Admin Overwrite DB im Restore-Bildschirm an. Danach ist nur noch der Restore Point auszuwählen (Abbildung 10).
Das Restore als Files gestaltet sich etwas komplexer und wird in diesem Beitrag nicht geschrieben. Die vollständige Dokumentation der Recovery-Optionen für SAP HANA in Azure finden Sie unter diesem Link.
Wie bereits angeführt, wählt der Admin für das Restore eines bestimmten Zeitpunktes Logs (Point in Time) und für das Recovery eines Wiederherstellungszeitpunkts Full & Differential aus (Abbildungen 11 und 12).
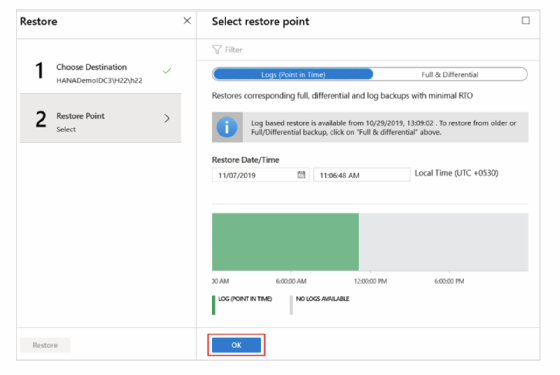
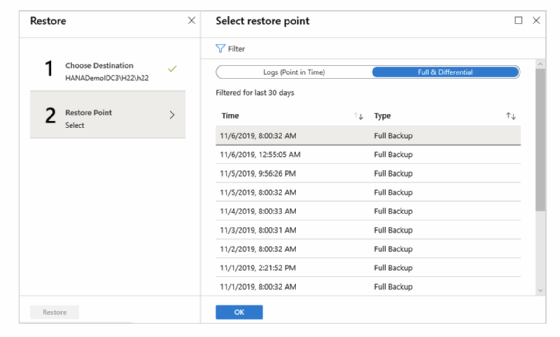
Ein Klick auf OK öffnet eine Maske, mit den Angaben zu Ziel und Restore Point sowie dem Button Restore, mit dem letztlich die Wiederherstellung angestoßen wird. Im Bereich Benachrichtigungen oder im Datenbankmenü unter der Option Wiederherstellungsaufträge lässt sich der Fortschritt des Recovery verfolgen. Eine regionsübergreifende Wiederherstellung ist ebenso machbar, allerdings müssen die Azure-Regionen gekoppelt sein. Die Übersichtseite zu den Informationen rund ums Backup und Restore für SAP HANA unter Azure findet sich hinter diesem Link.
Kurzfazit
Alle drei Cloud-Anbieter offerieren umfassende Optionen und gute Dokumentationen und Anleitungen für das Backup und die Wiederherstellung von SAP-HANA-Datenbanken. Obwohl alle den Backint-Agenten unterstützen, unterscheidet sich die Handlungsweise bei Azure deutlich von Google und AWS, die deutlich ähnlich zueinander aufgebaut sind.
Obwohl die Anweisungen klar und einfach sind, sollte hier ein geübter Administrator die Regie führen, um Flüchtigkeitsfehler oder versehentliches Überschreiben oder gar Löschen zu verhindern. So wie es scheint lässt derzeit nur Google ein Backup von lokalen SAP-HANA-Instanzen zu, in den Konfigurationsanweisungen der beiden Mitbewerber war dazu nichts zu lesen oder eventuell im Kleingedruckten versteckt. Zumindest bei AWS, Microsoftt sagt klar, dass dies eine Backup-Lösung für SAP-HANA-Datenbanken auf virtuellen Azure-Instanzen ist.





