
Gorodenkoff - stock.adobe.com
Apache Kylin: Analytical Data Warehouse für Big Data
Mit Apache Kylin lassen sich große Datenmengen analysieren und für Machine Learning verarbeiten. Der Artikel deckt die Funktionen der Open-Source-Software auf.

Apache Kylin ist eine Open Source OLAP-Engine (Online Analytical Processing), die für die Analyse von Big Data entwickelt wurde. Mit der Technologie lassen sich große Datensätze in Echtzeit verarbeiten und komplexe Abfragen auf multidimensionalen Datenwürfeln ausführen. Mit Kylin lässt sich ein Data Warehouse aufbauen, um komplexe Datenstrukturen zu analysieren.
Die Stärke von Apache Kylin liegt in seiner Fähigkeit, schnelle und interaktive Abfragen auf großen Datensätzen durchzuführen, ohne die Notwendigkeit komplexer ETL-Prozesse oder den Einsatz proprietärer Hardware. Indem die Lösung ein verteiltes und skalierbares Architekturmodell nutzt, kann Kylin große Datensätze in einem verteilten Cluster-Setup parallel verarbeiten.
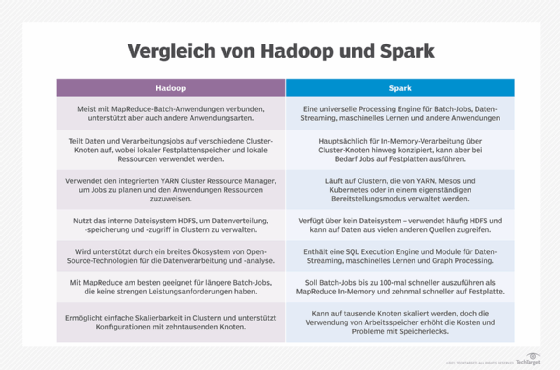
Datenanalysen mit Cubes, Spark und Hadoop
Der zentrale Bestandteil von Kylin ist sein Cube-Mechanismus, der gewährleistet, dass große Datensätze voraufbereitetet und mehrdimensionale Würfel gespeichert werden. Diese Vorberechnung erlaubt es Kylin, die Antwortzeiten zu reduzieren und interaktive Analyseabfragen in Sekundenschnelle auszuführen, anstatt auf langwierige Abfragezeiten warten zu müssen.
Ein weiteres Merkmal von Apache Kylin ist seine Integration mit Big-Data-Plattformen wie Apache Hadoop und Apache Spark. Dies erlaubt es Unternehmen, Kylin in bestehende Big-Data-Umgebungen zu integrieren und von OLAP-Analysen zu profitieren. Durch die Nutzung von Apache Kylin können Datenanalysten komplexe Geschäftsfragen beantworten und Einblicke aus ihren Big-Data-Datensätzen gewinnen.
Für Analyseprofis bietet die Integration mit Hadoop und Spark eine leistungsstarke und flexible Umgebung für die Big-Data-Analyse. Dadurch lassen sich Daten aus verschiedenen Quellen effizient speichern und verwalten. Hadoop dient als robustes, verteiltes Dateisystem, das die Grundlage für die Datenspeicherung bildet, während Spark als leistungsstarke Computing Engine fungiert, die schnelle Datenverarbeitung und Transformationen durchführt.
Durch die Kombination von Kylin und Spark können Datenanalysten von der parallelen Verarbeitung und der In-Memory-Verarbeitungsfähigkeit von Spark profitieren. Spark ermöglicht es, Daten in Echtzeit zu verarbeiten und die Ergebnisse in den zuvor berechneten Würfeln von Kylin zu speichern, was zu schnellen Abfragezeiten und interaktiven Analyseergebnissen führt.
Die Kombination aus Kylin, Hadoop und Spark schafft eine leistungsstarke End-to-End-Analyseplattform, die es Analysten erlaubt, große Datensätze in Echtzeit zu verarbeiten, um Einblicke und Erkenntnisse zu gewinnen und fundierte Geschäftsentscheidungen zu treffen.
Apache Hive, Kafka und Flink zusammen mit Kylin verwenden
Kylin ist ebenfalls mit Apache Hive kompatibel, ein Data-Warehouse-System auf Hadoop, das eine SQL-ähnliche Abfragesprache verwendet. Die Integration mit Hive erlaubt es Kylin, auf strukturierte Daten zuzugreifen, die in Hive-Tabellen gespeichert sind, und diese Daten in multidimensionale Würfel umzuwandeln.
Eine weitere wichtige Verbindung besteht zu Apache Kafka, einem verteilten Event-Streaming-System. Kylin kann Daten aus Kafka verarbeiten und analysieren, was besonders wertvoll ist, wenn es um die Echtzeitanalyse von strukturierten Streaming-Daten geht. Durch die Integration mit Kafka kann Kylin diese Daten in Echtzeit verarbeiten und die Ergebnisse in den voraufbereiteten Würfeln speichern. Dadurch stehen die Analyseergebnisse unmittelbar zur Verfügung.
Ein weiteres Tool, mit dem Kylin zusammenarbeitet, ist Apache Flink. Flink ist ein verteiltes Verarbeitungssystem, das sowohl Echtzeitdatenströme als auch Batch-Daten verarbeiten kann. Durch die Integration von Flink und Kylin lassen sich komplexe Analyseaufgaben auf Streaming-Daten ausführen und die Ergebnisse in die multidimensionalen Würfel integrieren.
Kylin integriert sich in andere BI-Plattformen
Ein weiterer wichtiger Aspekt von Apache Kylin ist seine Unterstützung für verschiedene Analysewerkzeuge und BI-Plattformen. Kylin arbeitet mit gängigen Tools wie Tableau, Power BI und Excel zusammen, wodurch Unternehmen ihre bestehenden Analyse-Workflows beibehalten können, während sie von den Funktionen von Kylin profitieren.
Eine der bemerkenswertesten Funktionen von Kylin ist das Cube Incremental Build. Diese ermöglicht es, nur die aktualisierten Daten in den vorberechneten Würfeln zu verarbeiten, anstatt den gesamten Datenbestand neu zu berechnen. Dies führt zu Zeitersparnissen bei der Aktualisierung der Analyseergebnisse und gestattet Datenanalysen in Echtzeit.
Die Sicherheit der Daten ist ein wesentlicher Pfeiler von Apache Kylin. Es bietet erweiterte Sicherheitsfunktionen wie Zugriffskontrolllisten (Access Control List, ACL) und Datenverschlüsselung, um sicherzustellen, dass sensible Unternehmensdaten geschützt bleiben und nur autorisierten Benutzern zugänglich sind.
Vielfältige Einsatzmöglichkeiten durch aktive Community
Apache Kylin hat eine lebendige Community von Entwicklern und Nutzern, die kontinuierlich an der Weiterentwicklung der Plattform arbeiten. Neue Versionen, Bugfixes und Erweiterungen werden regelmäßig veröffentlicht, um die Funktionalität und Leistung von Kylin zu optimieren.
Die Einsatzmöglichkeiten von Apache Kylin sind vielfältig. Die Lösung wird von Unternehmen in verschiedenen Branchen eingesetzt, darunter E-Commerce, Finanzdienstleistungen, Gesundheitswesen und Telekommunikation. Kylin hat sich als effektives Werkzeug für die Analyse von Verkaufsdaten, Kundenverhalten, Finanztransaktionen und anderen großen Datenmengen erwiesen.
Einstieg in Apache Kylin
Kylin basiert auf Hadoop und Spark, daher sollten grundlegende Kenntnisse dieser Lösungen vorhanden sein. Außerdem benötigt man Zugriff auf Hadoop-Cluster oder eine Spark-Infrastruktur. Im Rahmen der Einführung wird Apache Kylin auf dem Hadoop-Cluster oder Spark-Setup installiert. Der Download ist über die Website des Tools möglich. Dort findet man auch eine Dokumentation mit Anleitungen zu Installation und Konfiguration.
Nach der Einrichtung ist es wichtig, die Daten vorzubereiten, um mit Kylin zu arbeiten. Die relevanten Daten werden in das Hadoop-Dateisystem oder in die Hive-Tabellen geladen, je nachdem, wie die Daten gespeichert werden sollen. Die Daten müssen in einem für Kylin lesbaren Format vorliegen.
Ein entscheidender Schritt besteht in der Erstellung eines Cube in Kylin. Ein Cube ist ein multidimensionaler Würfel, der vorberechnete aggregierte Daten enthält und schnelle OLAP-Analysen ermöglicht. Hierfür müssen die Daten in einem Cube-Modell organisiert werden, bevor der Cube in Kylin erstellt wird. Kylin bietet hierfür eine benutzerfreundliche Benutzeroberfläche oder eine REST API zur Unterstützung. Nach Erstellung des ersten Cube können OLAP-Abfragen ausgeführt werden.




