Apache Beam: Einstieg in das Parallel Computing Framework
Apache Beam ist ein Parallel Computing Framework zur Verarbeitung großer Datenmengen. Der Beitrag zeigt die Möglichkeiten und gibt einen Einblick in das Projekt.

Apache Beam ist ein Open Source Tool, mit dem sich große Datenmengen und Streaming-Daten über verschiedene Pipelines verarbeiten lassen. Dazu stehen verschiedene Software Development Kits (SDK) zur Verfügung, mit denen sich die Pipelines aufbauen und definieren lassen. Das Tool kommt vor allem im Big-Data-Bereich zum Einsatz, zum Beispiel zusammen mit Hadoop oder Spark.
Apache Beam ist im Wesentlichen eine Sammlung mehrerer SDKs für unterschiedliche Programmiersprachen. Das Unified Parallel Processing Concept ermöglicht die Verarbeitung mit mehreren Execution Engines mit verschiedenen Programmiersprachen. Dadurch lassen sich Pipelines in vielen Sprachen und für viele Execution Engines umsetzen. Zudem ist geplant, dass sich mit Apache Beam nahezu jede Programmiersprache und jede Execution Engine nutzen lässt.
Apache Beam und das Google Dataflow Model
Apache Beam stellt ein Parallel Computing Framework dar, mit dem sich das Google Dataflow Model im Unternehmen einsetzen lässt. Bei der Verarbeitung großer Datenmengen geht es vor allem darum, dass das Processing so schnell und korrekt wie möglich abläuft. Das ist eine der Stärken des Dataflow Models.
Wenn bei der Analyse von Streaming-Daten die Korrektheit der Daten kritisch ist, muss man länger auf die Analyse warten, damit genügend Daten vorliegen. Dadurch steigt die Latenz. Wenn aber die Analyse schnell beginnt, lassen sich schnell Ergebnisse erzielen. Allerdings liegen dann nicht genügend Daten vor, um ausreichend korrekte Ergebnisse zu erzielen. Dafür ist die Latenz niedrig. Hier gilt es das richtige Verhältnis zu finden.
Google hat 2015 das Data Flow Model vorgestellt und in seiner Google Cloud Platform über den Dienst Google Dataflow integriert. Apache Beam nutzt dieses Modell und kann es mit anderen Engines verbinden, die nicht auf der GCP laufen. Die Daten werden über eine Pipeline in das System übertragen.
Hierfür nutzt Apache Beam die Worker im System. Apache Beam kann über die verschiedenen Pipelines unterschiedliche Mengen an Daten von und zu den Execution Engines laufen lassen. Es gibt keine festen Vorgaben und es lassen sich sogar mehrere Engines parallel einsetzen.
SDKs für verschiedene Programmiersprachen
Für die Verbindung der Endpunkte stellt Beam SDKs für die verschiedenen Programmiersprachen zur Verfügung, darunter für Java, Python, Go oder Scala. Das ermöglicht die Integration von Java- oder Python-Programme in die Pipelines und das Einbinden in eigene Programme.
Sobald eine Pipeline erstellt und definiert ist, kann die Ausführungslogik auf unterschiedlichen oder mehreren Execution Engines laufen. Ein Wechsel der Execution Engines ist mit überschaubarem Aufwand möglich. Die Unabhängigkeit zur ausführenden Engine ist eine der Stärken von Apache Beam.
Als Execution Engine sind unter anderem Google Dataflow, Apache Flink, Apache Spark und Hadoop vorgesehen. Zusammen mit den verschiedenen Programmiersprachen kann Apache Beam als Zentrale für eine umfassende Datenanalyse mit zahlreichen Quellen, Sprachen und Engines genutzt werden. Innerhalb einer Pipeline können mehrere Engines laufen und Apache Beam kann dafür sorgen, dass die Stärken jeder angebunden Engine für die jeweilige Sprache zur Verfügung stehen.
Erste Schritte mit Python und Apache Beam
Um Python mit Apache Beam zu verbinden, ist es sinnvoll, auf den Paketmanager pip zu setzen. Die aktuelle Version von pip kann Apache Beam einbinden. Das funktioniert auf Linux und Windows über die PowerShell. Bei der Verwendung von Beam mit Python ist eine virtuelle Umgebung mit Python notwendig. Eine virtuelle Umgebung ist ein Verzeichnisbaum, der seine eigene Python-Distribution enthält. Auf Linux erfolgt das über folgenden Befehl:
python -m venv /<Verzeichnis>
. /<Verzeichnis>/bin/activate
Die Installation von Apache Beam erfolgt im Anschluss mit:
pip install apache-beam
In der PowerShell unter Windows kann Apache Beam mit folgendem Befehl installiert werden:
python -m pip install apache-beam
Um anschließend eine Pipeline zu starten, wird folgender Befehl verwendet:
python -m apache_beam.examples.wordcount --input /path/to/inputfile --output /path/to/write/counts
Pipelines für Apache Flink lassen sich zum Beispiel folgendermaßen anstoßen:
python -m apache_beam.examples.wordcount --input /path/to/inputfile \
--output /path/to/write/counts \
--runner FlinkRunner
Bei der Verwendung von Spark sieht der Befehl so aus:
python -m apache_beam.examples.wordcount --input /path/to/inputfile \
--output /path/to/write/counts \
--runner SparkRunner
Bei der Verwendung von Java kann man auf Apache Maven setzen. Um ein Beispielprojekt aufzubauen, ist folgender Befehl möglich:
mvn archetype:generate \
-DarchetypeGroupId=org.apache.beam \
-DarchetypeArtifactId=beam-sdks-java-maven-archetypes-examples \
-DarchetypeVersion=2.40.0 \
-DgroupId=org.example \
-DartifactId=word-count-beam \
-Dversion="0.1" \
-Dpackage=org.apache.beam.examples \
-DinteractiveMode=false
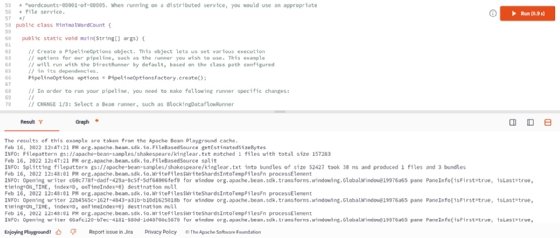
Mit dem Apache Beam PlayGround kann ebenfalls eine Umgebung aktiviert werden. Der Playground lässt sich über die Website von Apache Beam starten.