
weerapat1003 - stock.adobe.com
10 Gründe, die gegen den Einsatz von Microservices sprechen
Nicht jeder ist begeistert von einer Cloud-nativen Architektur. Die Nachteile von Microservices können Anwender davon überzeugen, bei einer traditionellen Architektur zu bleiben.

Cloud-native Architekturen, die auf Docker und Kubernetes aufbauen, sind heute der letzte Schrei. Entwicklungsteams, die Microservices einsetzen, profitieren von einigen Vorteilen, darunter:
- Microservices bieten die Freiheit, verschiedene Architekturen, Sprachen, Prozesse und Tools zu wählen.
- Eine Microservices-Architektur kodifiziert viele seit langem bewährte Verfahren für Softwarekomponenten, wie zum Beispiel domänenorientiertes Design und ereignisgesteuerte Architekturen.
- Microservices sind gekapselt und können unabhängig voneinander überarbeitet werden.
- Eine Microservices-Architektur unterstützt einen flexiblen und potenziell kürzeren Release-Zeitplan.
- Technologien, die Microservices zur Laufzeit unterstützen, wie zum Beispiel Docker und Kubernetes, laufen auf handelsüblicher Hardware.
Dennoch sollten Softwareentwicklungsteams sich darüber im Klaren sein, dass Microservices einige erhebliche Nachteile mit sich bringen. Bevor Sie einen zuverlässigen Monolithen in eine Vielzahl kleinerer, funktional identischer Mikrokomponenten zerlegen, sollten Sie sich über diese Herausforderungen einer Microservices-Architektur im Klaren sein und wissen, wie Sie sie umgehen – oder mit ihnen leben können.
Die zehn größten Nachteile von Microservices lassen sich in folgende Kategorien einteilen:
- Erhöhte Komplexität
- Bedarf an automatisierten Bereitstellungen
- Komplexer Integrations-Overhead und Abhängigkeiten
- Datenübersetzung und Inkompatibilitäten
- Überlastung des Netzwerks
- Abnehmende Leistung
- Erhöhte Kosten
- Komplexes Logging und Tracing
- Herausforderungen beim Testen und Debuggen
- Organisatorische Trägheit
Erhöhte Komplexität
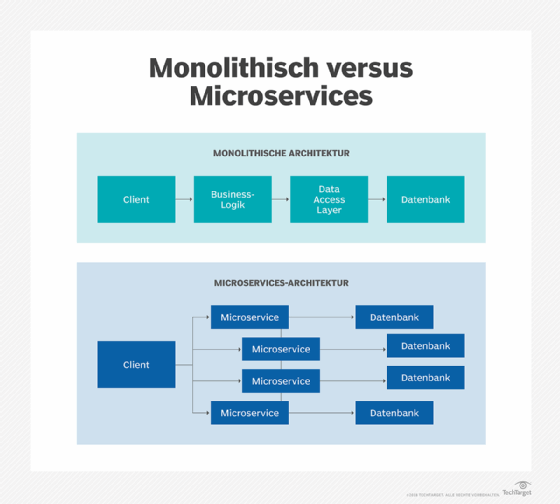
Wenn eine monolithische Anwendung in eine Untergruppe unabhängiger Microservices aufgeteilt wird, die über ein Netzwerk kommunizieren, erhöht sich die Komplexität der Anwendungsarchitektur erheblich.
Nehmen wir an, Sie möchten eine einzelne monolithische Anwendung in zehn Microservices aufteilen. Dadurch müssen Sie nun folgende Aufgaben aktualisieren:
- Skalieren Sie zehn Anwendungen anstelle von einer.
- Sichern Sie zehn API-Endpunkte anstelle von einem.
- Verwalten Sie zehn Git-Repositories statt einem.
- Erstellen Sie zehn Pakete anstelle von einem.
- Verteilen Sie zehn Artefakte statt einem.
Es ist schwieriger, eine Vielzahl kleinerer Programme zu verwalten als eine einzelne, monolithische Anwendung. Das ist einer der größten Nachteile von Microservices.
Automatisierte Bereitstellung
Microservices sind für Anwendungen, die im Web betrieben werden, von großem Nutzen, aber sie sind auch komplexer zu testen, bereitzustellen und zu warten. Dies ist keine manuelle Arbeit – sie muss automatisiert werden. Das schiere Volumen der Dienste in Unternehmensanwendungen macht dies erforderlich.
Unternehmen, die Microservices-Architekturen einführen wollen, müssen Automatisierungstechnologien wie GitHub, Jenkins und Terraform einsetzen. Darüber hinaus müssen die Mitarbeiter über das Fachwissen zur Erstellung von Skripten verfügen.
Es ist ein enormer Aufwand an Zeit und Ressourcen, die Automatisierung auf konsistente und umfassende Weise zu implementieren. Das ist der Preis, den Unternehmen zahlen müssen, wenn sie die Vorteile von Microservices auskosten möchten.
Mehraufwand für Integration und Abhängigkeiten
Die Standardisierung von Verträgen für den Datenaustausch zwischen Microservices ist eine Menge zusätzlicher Arbeit.
Microservices werden unabhängig entwickelt und in isolierten Containern bereitgestellt. Zur Laufzeit müssen alle isolierten und unabhängigen Microservices miteinander kommunizieren. Das bedeutet mehr Integration von RESTful-Endpunkten und standardisiertem JSON- oder XML-Austausch.
Außerdem ist die Verwaltung der Abhängigkeiten zwischen den Microservices ein großes Problem. RESTful-Endpunkte sind äußerst anfällig. Änderungen an einer Komponente können unbeabsichtigte Folgen für eine andere haben.
In einer monolithischen Anwendung interagieren die Komponenten direkt über Java- oder Python-basierte API-Aufrufe. Es besteht keine Notwendigkeit für ein gemeinsames Datenaustauschformat oder RESTful APIs. Darüber hinaus werden alle Interaktionen zur Kompilierungszeit typgeprüft und validiert.
Datenübersetzung
Es wäre schön, wenn alle Microservices die gleichen Datenstrukturen und Kommunikationsprotokolle verwenden würden, aber das ist oft nicht der Fall. So ist es zum Beispiel denkbar, dass ein REST-Microservice versucht, mit einem gRPC-Microservice zu kommunizieren, wobei beide unterschiedliche HTTP-Protokolle verwenden. Das ist eine grundlegende Inkompatibilität.
Eine Möglichkeit, diese Inkompatibilität zu überwinden, ist die Implementierung eines Übersetzungsmechanismus, zum Beispiel eines Proxys.
Auch die Datenübersetzung zwischen Microservices kann eine Herausforderung darstellen. Die Übersetzung von Datenkontexten ist ein Problem, das es schon seit Jahrzehnten gibt. Monolithische Anwendungen speichern all diese Daten in einer einzigen Datenbank, um dieses Problem zu minimieren. Eine Microservices-Architektur hingegen vergrößert das Problem. Eine Anwendung umfasst in der Regel Dutzende oder sogar Hunderte von Microservices, und die Implementierung der Datenübersetzung zwischen ihnen kann eine große Herausforderung darstellen.
Netzwerküberlastung
Microservices kommunizieren über RESTful APIs, die Daten im JSON- und XML-Format austauschen. Der gesamte Datenaustausch erfolgt über das HTTP-Protokoll. Ein zuvor ruhiges Netzwerk wird deutlich stärker belastet, wenn Microservices eingeführt werden. Das Ergebnis kann eine Überlastung des Netzwerks sein.
Glücklicherweise findet die Kommunikation der meisten Microservices in privaten, lokalen Subnetzen statt, in denen die Netzwerkbandbreite leicht erhöht werden kann. All diese XML- und JSON-Aktivitäten über das Netzwerk führen jedoch zum nächsten Nachteil von Microservices: Leistungseinbußen.
Geringere Leistung
Ein großer Nachteil von Microservices ist, dass sie mehr Speicher, Taktzyklen und Netzwerkbandbreite verbrauchen als eine vergleichbare monolithische Architektur.
Bei einer monolithischen Anwendung werden alle Komponenten im Rahmen eines einzigen Prozesses ausgeführt. Die Interaktionen zwischen den Komponenten finden auf Hardwareebene statt; eine Komponente ruft eine andere über einen Standardmethodenaufruf auf. Der einzige Leistungsmehraufwand besteht darin, jeden Aufruf auf der lokalen CPU zu planen. Komponenten, die innerhalb desselben Prozesses ausgeführt werden, tauschen Daten sofort aus, da es sich nur um einen Zeiger auf eine Referenz im Speicher handelt.
Monolithen und Microservices im Vergleich
Vergleichen Sie die Interaktionen innerhalb eines Monolithen mit dem folgenden Szenario: zwei Microservices, die über ein Netzwerk miteinander kommunizieren.
- Zunächst beschreibt eine Komponente ihre Daten in einer JSON-Datei.
- Die Komponente liefert die JSON-Datei über einen Netzwerkaufruf an den zweiten Microservice.
- Dieser zweite Microservice parst die JSON-Datei und extrahiert die Daten.
- Der zweite Microservice implementiert die erforderliche Funktionalität.
- Der zweite Microservice erstellt seine eigene JSON-Textdatei für die Antwortdaten.
- Der zweite Microservice richtet einen neuen Netzwerkaufruf an den ersten aufrufenden Microservice.
- Der erste Microservice empfängt und parst die JSON-Datei, um die Antwortdaten zu extrahieren.
Das ist eine Menge Overhead, um das zu erreichen, was in einer monolithischen Laufzeitumgebung sofort geschieht.
Der Nachteil von Microservices in Bezug auf Leistung und Ressourcennutzung führt uns zum nächsten Nachteil, nämlich den Kosten.
Erhöhte Computing-Kosten
Nach der Umstellung erfordert ein einzelner Monolith, der in mehrere Microservices aufgeteilt ist, Folgendes:
- Mehr Gesamtspeicher für die Ausführung.
- Doppelte Ressourcen bei der Verwendung mehrerer Container oder virtueller Maschinen (VM).
- Zusätzliche Bandbreite für den Aufruf von RESTful-Webservices.
- Mehr CPU-Zyklen für das Senden, Parsen, Lesen und Wiederzusammensetzen von JSON-Dateien.
Heutzutage zahlen Unternehmen für Cloud Computing wie für ein Dienstprogramm. Je mehr CPU oder Speicher eine Anwendung verwendet, desto höher ist die Rechnung für die Cloud-Ressource.
Die höhere Anzahl von Ressourcen, die zur Unterstützung einer Microservices-Architektur im Vergleich zu einer monolithischen Architektur erforderlich ist, bedeutet höhere Kosten. Das ist ein großer Nachteil von Microservices.
Komplexe Protokollierung, Nachverfolgung und Prüfung
Cloud-native Anwendungen werden in der Regel in Kubernetes-Clustern bereitgestellt, in denen ephemere Container die erforderliche Microservices-Laufzeit bereitstellen. Die ephemere Natur von Microservices, insbesondere in einem Netzwerk mit mehreren Knoten, macht es jedoch schwierig, sie zu protokollieren, zu verfolgen und zu überprüfen.
Wenn der Docker-Container, der einen Microservice beinhaltet, ausfällt, sind die Protokolldateien sofort verloren, es sei denn, ein Daemon-Prozess im Hintergrund verschiebt die Protokolldaten aktiv aus dem Container und legt sie an einem zuverlässigen Speicherort ab. Tools wie das quelloffene Fluentd unterstützen dabei, dieses Problem zu lösen, aber es ist immer noch ein Problem.
Bei einer monolithischen Architektur gibt es einen Ordner auf dem Server, in den alle Protokoll-, Tracing- und Auditing-Daten geschrieben werden, und die meisten herkömmlichen Server verfügen über integrierte Mechanismen zur Protokollrotation. Es ist viel einfacher, die Protokollierung und Verfolgung auf einem Monolithen zu verwalten.
Der zusätzliche Aufwand für die Verwaltung von Protokolldateien, Trace-Dateien und Audit-Daten in einem Cloud-nativen Cluster ist einer der größten Nachteile von Microservice-Architekturen.
Schwierige Fehlersuche und Problemerkennung
Die Fehlersuche ist bei Microservices aus denselben Gründen schwierig wie die Zusammenführung von Trace-Dateien und Protokollen. Wenn eine fehlgeschlagene Anfrage von mehreren Microservices bearbeitet wird, die innerhalb isolierter Laufzeiten gehostet werden, kann es schwierig sein, herauszufinden, wo die Anfrage fehlgeschlagen ist und warum. Vergleichen Sie das mit einer monolithischen Anwendung, bei der die Fehlersuche den Weg einer fehlgeschlagenen Anfrage auf einem einzigen Server verfolgt, der auf einem einzigen Computer gehostet wird.
Außerdem kann es mühsam sein, den genauen Weg der fehlgeschlagenen Anfrage zu replizieren, insbesondere wenn in Containern gehostete Microservices ständig hoch- und heruntergefahren werden.
Verteiltes Debugging
Auch das Debuggen einer Anwendung mit Microservices-Architektur ist schwierig. Denken Sie nur an die Notwendigkeit, den Weg einer Anfrage in und aus einer Architektur zu verfolgen, in der möglicherweise Hunderte von Microservices zusammenarbeiten und jeder Container unabhängig ist. Dies macht eine umfassende Überwachungsstrategie praktisch unumgänglich. Die Protokollierung der Interna einer Microservices-Architektur bietet einen begrenzten Einblick, aber die Überwachung muss das große Ganze im Blick haben.
Verschiedene Tools unterstützen bei der Fehlersuche in dienstübergreifenden Aktivitäten durch verteiltes Tracing. Zu den Optionen gehören Open-Source-Projekte wie Jaeger und Zipkin sowie kommerzielle Produkte wie Datadog und Dynatrace. Unabhängig davon, welche Tools Sie verwenden, ist eine Monitoring-Strategie erforderlich, um die internen und externen Aktivitäten mit den verschiedenen Microservices, aus denen die Anwendung besteht, zu beobachten.
Organisatorische Trägheit
Eines der größten Probleme im Zusammenhang mit Microservices ist die Überwindung der organisatorischen Trägheit und die Überzeugung eines Unternehmens, sie zu übernehmen.
Der Übergang von Monolithen zu einer auf Microservices basierenden Architektur ist eine große Verpflichtung: neue Tools müssen eingeführt, neue Entwicklungsansätze und neue Fähigkeiten erlernt werden. Wenn es keinen zwingenden Grund gibt, auf Cloud-native Anwendungen umzusteigen und einen Monolithen neu zu entwerfen, glauben viele Unternehmen, dass es einfacher ist, einfach das zu tun, was funktioniert, und einen Monolithen auch in Zukunft beizubehalten.
Überzeugende Argumente werden die organisatorische Trägheit überwinden. Wenn die IT-Abteilung nicht bereit ist, den Monolithen in Microservices aufzulösen, dann überwiegen vielleicht die Nachteile von Microservices die Vorteile – und das ist auch in Ordnung. Nicht jedes Unternehmen ist bereit oder muss in der Cloud-nativen Welt leben.





