
alunablue - stock.adobe.com
Wichtige Faktoren für die Planung einer HPC-Infrastruktur
High Performance Computing ist die Grundlage für viele moderne IT-Anwendungen. Doch bei der Umsetzung im eigenen Rechenzentrum gibt es zahlreiche Herausforderungen zu meistern.

High Performance Computing entstand vor Jahrzehnten als erschwingliche und skalierbare Methode zum Lösen schwieriger mathematischer Probleme. Heutzutage verwenden viele Unternehmen HPC, um komplexe Rechenaufgaben wie das Modellieren von Finanzrisiken, das Nachverfolgen von Regierungsressourcen, Fluganalysen in der Raumfahrt und viele andere Big-Data-Projekte zu bewältigen.
High Performance Computing (HPC) kombiniert Hardware, Software, Systemverwaltung und Rechenzentrumseinrichtungen, um eine große Anzahl von Computern miteinander zu verbinden, die kooperativ an einer gemeinsamen Aufgabe arbeiten, die zu komplex ist, als dass ein einzelner Computer sie bewältigen könnte. Einige Unternehmen leasen HPC, und andere Unternehmen bauen eine HPC-Infrastruktur in ihren eigenen Rechenzentren auf.
Sie sollten die Stärken, Schwächen und Voraussetzungen einer HPC-Infrastruktur genau kennen, um zu entscheiden, ob HPC für Ihr Unternehmen geeignet ist und wie Sie es am besten implementieren.
Was ist HPC?
Im Allgemeinen ist HPC der Einsatz großer und leistungsstarker Computer, die darauf ausgelegt sind, mathematisch intensive Aufgaben effizient zu bewältigen. HPC-Supercomputer lohnen sich meistens nur für sehr große Unternehmen.
Stattdessen implementieren die meisten Organisationen HPC als eine Gruppe relativ kostengünstiger, eng integrierter Computer oder Knoten, die für den Betrieb in einem Cluster konfiguriert sind. Solche Cluster verwenden ein verteiltes Verarbeitungssoftware-Framework – wie Hadoop und MapReduce – um komplexe Computerprobleme zu lösen, indem sie Aufgaben auf mehrere vernetzte Computer aufteilen. Jeder Computer innerhalb des Clusters arbeitet an seinem eigenen Teil des Problems oder Datensatzes, den das Software-Framework dann wieder integriert, um eine vollständige Lösung bereitzustellen.
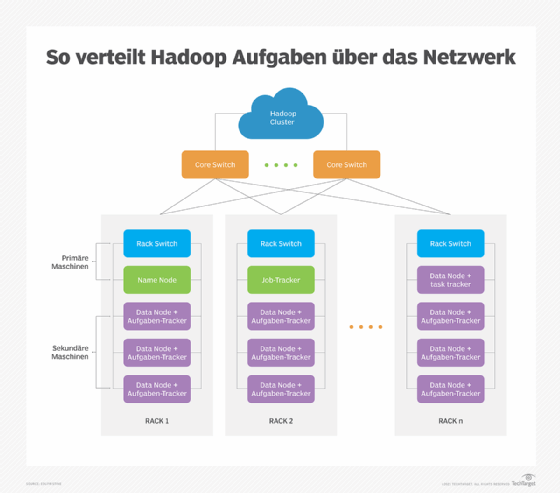
Die verteilte HPC-Architektur bringt einige Kompromisse für Unternehmen mit sich. Zu den unmittelbarsten Vorteilen zählen Skalierbarkeit und Kostenmanagement. Frameworks wie Hadoop können auf einem einzigen Server genauso laufen, wie auf einem Cluster von Tausenden. Auf diese Weise bauen Unternehmen eine HPC-Infrastruktur auf, die ihre Aufgaben auf leicht verfügbaren und kostengünstigeren Standardcomputern erfüllt. Hadoop ist außerdem fehlertolerant, erkennt ausfallende Systeme und trennt sie vom Cluster, während es deren Jobs an verfügbare Geräte umleitet.
Der Aufbau eines HPC-Clusters ist technisch einfach, die HPC-Bereitstellung bringt jedoch geschäftliche Herausforderungen mit sich. Selbst mit der Möglichkeit, die Infrastruktur im Laufe der Zeit zu erweitern, können die Kosten für die Beschaffung, den Aufbau, den Betrieb und die Wartung von Dutzenden, Hunderten oder sogar Tausenden von Servern – zusammen mit der Netzwerkinfrastruktur zu deren Unterstützung – zu einer erheblichen finanziellen Investition werden. Viele Unternehmen haben nur einen begrenzten Bedarf an High Performance Computing; für sie ist er Preis einer solchen Infrastruktur On-Premises nicht gerechtfertigt.
Nur ein gründliches Verständnis von Anwendungsfällen, Nutzungs- und Return-on-Investment-Kennzahlen führt zu erfolgreichen HPC-Projekten.Was benötigen Unternehmen zum Implementieren von HPC?
Unternehmen, die eine HPC-Architektur aufbauen möchten, benötigen dafür drei Komponenten: geeignete Hardware, die Softwareschicht und die Gegebenheiten, um diese zu betreiben.
Anforderungen berechnen. Der Aufbau eines HPC-Clusters erfordert Server, Speicher und ein dediziertes Netzwerk, das sich nicht das LAN mit dem täglichen Geschäftsverkehr teilen sollte. Sie können Programme wie Hadoop auf einem einzigen Server implementieren, damit Mitarbeiter den Umgang mit ihnen üben und Erfahrungen mit HPC-Software und Jobplanung sammeln können. Ein typisches Hadoop-Cluster verwendet jedoch mindestens drei Server: einen Primärknoten, einen Worker-Knoten und einen Client-Knoten.
Sie können dieses einfache Modell mit mehreren primären Knoten skalieren, die jeweils viele Worker-Knoten unterstützen. Das bedeutet, dass die typische HPC-Bereitstellung aus mehreren Servern besteht – normalerweise virtualisierten, um die Anzahl der Server zu vervielfachen, die dem Cluster zur Verfügung stehen. Für dedizierte Cluster-Netzwerk benötigen IT-Teams TCP/IP-Netzwerkgeräte mit hoher Bandbreite wie Gigabit Ethernet, NICs und Switches. Die Anzahl der Server und Switches hängt von der Größe des Clusters sowie von der Leistungsfähigkeit jedes Servers ab.
Anfänger beginnen oft mit einer begrenzten Hardwarebereitstellung, die nur wenige Racks umfasst und später zum Cluster heranwächst. Sie können die Anzahl der Server und Switches begrenzen, indem Sie in High-End-Server mit ausreichend Prozessoren und Speicher investieren, was zu mehr Rechenkapazität auf jedem Server führt.
Softwareanforderungen. Ausgereifte Stacks müssen eine Suite von HPC-Cluster-Managementfunktionen problemlos unterstützen können. Software-Stacks wie Bright Cluster Manager und OpenHPC enthalten in der Regel eine Reihe von Tools für das Cluster-Management, darunter:
- Bereitstellungs-Tools
- Überwachungs-Tools
- Systemverwaltungs-Tools
- Ressourcenmanagement-Tools
- MPI-Bibliotheken (Message Passing Interface)
- Mathematische Bibliotheken
- Compiler
- Debugger
- Dateisysteme
HPC-Frameworks wie das Hadoop-Framework sind eine beliebte Wahl für die Verwaltung von Umgebungen.
Hadoop enthält Komponenten wie das HDFS-Dateisystem, Hadoop Common, MapReduce und YARN, die viele der oben aufgeführten Funktionen bieten.
HPC-Projekte erfordern eine Ausgabe, zum Beispiel über Visualisierungs-, Modellierungs- oder anderer Berichtssoftware, um den Nutzern Rechenergebnisse anzuzeigen. Tools wie Hunk, Platfora und Datameer visualisieren Hadoop-Daten. Open Source Tools wie Jaspersoft und Pentaho; Business-Intelligence-Tools (BIRT) wie Cognos, MicroStrategy und QlikView; nicht zuletzt Diagrammbibliotheken, wie einschließlich Rshiny, D3.js und Highcharts können die Ausgabe aus Nicht-Hadoop-Frameworks visualisieren.
Anforderungen an die Einrichtungen. Die räumlichen Gegebenheiten werden bei HPC oft zum einschränkenden Faktor. Um HPC zu implementieren, benötigen Sie eine Stellfläche, die tragfähig genug ist, um Racks mit zusätzlichen Servern aufzunehmen, eine geeignete Stromversorgung für deren Betrieb und eine angemessene Kühlungsanlage. Einige Unternehmen verfügen nicht über den Platz und die Kühlinfrastruktur, um diese Bedingungen zu erfüllen.
Hyperkonvergente Infrastruktur (Hyper Converged Infrastructure, HCI) kann den physischen Computing Footprint minimieren, ihre hohe Leistungsdichte führt jedoch oft zu Hot Spots und anderen technischen Herausforderungen. Ein vollständiges Rechen-Rack, das für die HPC-Bereitstellung vorgesehen ist, kann bis zu 72 Blade-Server und fünf Top-of-Rack-Switches umfassen, die insgesamt fast eine Tonne wiegen und bis zu 43 kW Leistung benötigen.
HPC-Bereitstellungen erfordern eine sorgfältige Bewertung der Rechenzentrumseinrichtungen und eine detaillierte Bewertung des Energie- und Kühlbedarfs im Verhältnis zur Kapazität. Wenn die Einrichtungen für eine HPC-Bereitstellung nicht ausreichen, müssen Sie nach Alternativen zum hauseigenen HPC suchen.
Umgang mit HPC-Herausforderungen
Computing-Herausforderungen. HPC lässt sich zwar mit der üblichen Serverhardware umsetzen – Beschränkungen bei der Rechenleistung können Sie jedoch mit modularen Servern mit hoher Dichte besser umgehen. Ein modulares Design macht es einfacher für Sie, Server zu erweitern und auszutauschen. Die beste Leistung erzielen Sie mit dedizierten Hochleistungsservern mit einem dedizierten Hochgeschwindigkeits-LAN. Durch diese Konstellation können Sie Ihre Bereitstellung im Laufe der Zeit durch regelmäßige Technologieaktualisierungszyklen und zusätzliche Investitionen aktualisieren.
Softwareherausforderungen. Die wichtigste Herausforderung mit HPC-Software liegen in der Verwaltung von Softwarekomponentenversionen und der Interoperabilität, das heißt darin, sicherzustellen, dass das Patchen oder Aktualisieren einer Komponente die Stabilität oder Leistung anderer Softwarekomponenten nicht beeinträchtigt. Machen Sie das Testen und die Validierung von neuen Softwareversionen zu einem zentralen Bestandteil Ihres HPC-Software-Update-Prozesses.
Herausforderungen bei der Ausstattung. Die Stellfläche, die Stromversorgung und die Kühlung, die für den Betrieb zusätzlicher Racks mit Servern und Netzwerkgeräten erforderlich sind, schränken viele Unternehmen ein, die HPC implementieren möchten. Hier kann es helfen, vorhandene Server zu upgraden. Durch die Bereitstellung größerer und leistungsfähigerer Geräte zur Unterstützung zusätzlicher virtueller Maschinen (VMs) können Sie effektiv mehr HPC-Knoten hinzufügen, ohne weitere physische Server aufzubauen. Darüber hinaus kann das Gruppieren von VMs innerhalb desselben physischen Servers Netzwerkprobleme verringern, da VMs innerhalb des Servers kommunizieren, ohne Datenverkehr über das LAN zu leiten.
Sie können außerdem Flächen bei Colocation-Anbietern anmieten, um mehr Platz zu schaffen. Das erfordert jedoch oft eine kostspielige langfristige Vertragsbindung, die sich über Jahre erstrecken kann.
Der Strompreis ist auch ein wichtiger Faktor für die Gesamtkosten Ihrer HPC-Infrastruktur. Dies müssen Sie berücksichtigen. Ziehen Sie eine ausgewogene dreiphasige Stromverteilungsinfrastruktur und fortschrittliche Stromverteilungsgeräte (Power Distribution Unit, PDU) in Betracht – wie intelligente PDUs und geschaltete PDUs –, um die Energieeffizienz zu erhöhen. Unterbrechungsfreie Stromversorgungen unterstützen geordnete Server-Shutdowns von HPC-Clustern, um Datenverluste zu minimieren.
Durch das Hinzufügen von Racks mit High-Density-Servern kann das Lüftungssystem eines Rechenzentrums stärker gefordert sein. Wenn keine zusätzliche Kühlung verfügbar ist, prüfen Sie Colocation- oder Cloud-Optionen oder ziehen Sie fortschrittliche Kühltechnologien wie Immersionskühlung für HPC-Racks in Betracht.
Nutzen Sie die Cloud für HPC?
Mehrere Public-Cloud-Anbieter, darunter AWS, Google Cloud Platform und Microsoft Azure, bieten HPC-Dienste für Unternehmen an, welche die Anforderungen von High Performance Computing nicht selbst umsetzen können. Public Clouds vermeiden viele der erwähnten Probleme mit On-Premises-HPC. Clouds können Folgendes bieten:
- nahezu unbegrenzte Skalierbarkeit durch weltweit verfügbare Rechenzentren;
- eine Vielzahl von dedizierten CPUs, GPUs, Field-Programmable Gate-Arrays (FPGA) und schnellen Verbindungshardwarefunktionen zur Optimierung der Auftragsleistung für Aufgaben wie maschinelles Lernen, Visualisierung und Rendering;
- ausgereifte und leicht verfügbare HPC-Dienste wie Azure CycleCloud und Apache Hadoop auf Amazon EMR, welche den Einstieg erleichtern und die Belastung des lokalen IT-Personals reduzieren; und
- Pay-as-you-go-Kostenmodelle, die es einem Unternehmen ermöglichen, nur für HPC zu bezahlen, wenn es diese Cloud-Dienste und -Ressourcen tatsächlich nutzt.
Unternehmen mit häufigen und kleineren HPC-Aufgaben sollten in Erwägung ziehen, ein kleineres HPC-Cluster vor Ort zu betreiben, um von der Sicherheit und Bequemlichkeit der Ressourcen On-Premises zu profitieren und für gelegentliche anspruchsvollere HPC-Projekte, die sie nicht intern durchführen können, auf die Public Cloud auszuweichen.






