
2121fisher - Fotolia
Hardware für KI und Co: Infrastrukturanforderungen kennen
Dass KI-Anwendungen andere Hardwareanforderungen stellen, ist bekannt. Admins sollten wissen, wie diese aussehen und ob HCI- oder High-Density-Lösungen dafür passend sind.
Die IT verdankt ihre Existenz als professionelle Disziplin den Unternehmen, die versuchen, Daten zu nutzen, um sich einen Wettbewerbsvorteil zu verschaffen. Heutzutage werden Unternehmen von Daten überflutet, aber die Technologie zur Verarbeitung und Analyse dieser Daten kann mit der Flut von Echtzeitdaten oft nicht Schritt halten. Nicht nur die schiere Menge an Daten stellt eine Herausforderung dar, sondern auch die unterschiedlichen Datentypen.
Die explosionsartige Zunahme unstrukturierter Daten hat sich beispielsweise für Informationssysteme, die traditionell auf strukturierten Datenbanken basieren, als besonders schwierig erwiesen. Dies hat die Entwicklung neuer Algorithmen auf der Grundlage von maschinellem Lernen (ML) und Deep Learning ausgelöst. Dies wiederum hat dazu geführt, dass Unternehmen Systeme und Infrastrukturen für ML, Deep Learning und KI-Arbeitslasten entweder kaufen oder aufbauen müssen.
Während das Interesse an ML und Deep Learning bereits seit einigen Jahren besteht, steigern neue Technologien wie ChatGPT und Microsoft Copilot das Interesse an KI-Anwendungen für Unternehmen. IDC prognostiziert, dass bis 2025 etwa 40 Prozent der IT-Budgets der Global-2000-Organisationen für KI-bezogene Initiativen ausgegeben werden, da KI als Motivator für Innovationen führend sein wird.
Unternehmen bauen zweifellos viele ihrer KI- und ML-basierten Anwendungen in der Cloud auf, indem sie hochentwickelte ML- und Deep-Learning-Services wie Amazon Comprehend oder Azure OpenAI Service nutzen. Aber die riesigen Datenmengen, die zum Trainieren und Füttern von KI-Algorithmen erforderlich sind, die unerschwinglichen Kosten für die Verlagerung von Daten in die Cloud und deren Speicherung sowie der Bedarf an Echtzeit-Ergebnissen (oder nahezu Echtzeitergebnissen) führen dazu, dass viele KI-Systeme in Firmen auf privaten, dedizierten Systemen eingesetzt werden.
Viele dieser Systeme befinden sich in den Rechenzentren des Unternehmens. Es gibt jedoch auch KI-Systeme am Rande des Unternehmens, da diese Systeme in der Nähe der Systeme angesiedelt sein müssen, die die Daten erzeugen, die Unternehmen analysieren müssen.
Bei der Vorbereitung auf eine KI-gestützte Zukunft muss sich die IT-Abteilung mit vielen Architektur- und Bereitstellungsentscheidungen auseinandersetzen. Die wichtigste davon ist die Konzeption und Spezifikation von KI-beschleunigten Hardware-Clustern. Eine vielversprechende Option sind hyperkonvergente Infrastruktursysteme (HCI), die sich durch ihre Dichte, Skalierbarkeit und Flexibilität auszeichnen. Obwohl viele Elemente der KI-optimierten Hardware hochspezialisiert sind, ähnelt das Gesamtdesign stark der gewöhnlichen hyperkonvergenten Hardware. Es gibt sogar HCI-Referenzarchitekturen, die für die Verwendung mit ML und KI entwickelt wurden.
Zentrale Hardwareelemente und KI-Anforderungen
Algorithmen für maschinelles und tiefes Lernen ernähren sich von Daten. Datenauswahl, -erfassung und -vorverarbeitung, wie zum Beispiel Filterung, Kategorisierung und Merkmalsextraktion, sind die wichtigsten Faktoren, die zur Genauigkeit und Vorhersagekraft eines Modells beitragen. Daher sind die Datenaggregation – die Konsolidierung von Daten aus verschiedenen Quellen – und die Speicherung wichtige Elemente von KI-Anwendungen, die das Hardwaredesign beeinflussen.
Die für die Datenspeicherung und die KI-Berechnungen erforderlichen Ressourcen skalieren in der Regel nicht im Einklang. Die meisten Systemdesigns entkoppeln daher beide, wobei der lokale Speicher in einem KI-Rechenknoten so groß und schnell ist, dass er den Algorithmus speisen kann.
Bewährte Infrastrukturen für ML- und KI-Anwendungen
Die meisten KI-Systeme laufen auf Linux-VMs oder als Docker-Container. Die meisten gängigen KI-Entwicklungsframeworks und viele Beispielanwendungen sind als vorgefertigte Container-Images von Nvidia und anderen erhältlich. Zu den populären Anwendungen gehören die folgenden:
- Computer Vision wie beispielsweise Bildklassifizierung, Objekterkennung (in Bildern oder Videos), Bildsegmentierung und Bildwiederherstellung.
- Verarbeitung von Sprache und natürlicher Sprache, Spracherkennung und Sprachübersetzung.
- Text-zu-Sprache-Synthese.
- Empfehlungssysteme, die auf der Grundlage früherer Nutzeraktivitäten und Referenzen Bewertungen und personalisierte Inhalts- oder Produktvorschläge liefern.
- Inhaltsanalyse, Filterung und Moderation.
- Mustererkennung und Erkennung von Anomalien.
Diese Systeme finden in einer Vielzahl von Branchen Anwendung, darunter die folgenden Beispiele:
- Betrugsanalyse und automatisierte Handelssysteme für Finanzdienstleister.
- Personalisierung im Online-Handel und Produktempfehlungen.
- Überwachungssysteme für physische Sicherheitsfirmen.
- Geologische Analysen für die Öl- und Ressourcengewinnung durch Gas- und Bergbauunternehmen.
Algorithmen für maschinelles und tiefes Lernen erfordern eine große Anzahl von Matrixmultiplikationen und akkumulierten Gleitkommaoperationen. Die Algorithmen können die Matrixberechnungen parallel durchführen, wodurch ML und Deep Learning den Grafikberechnungen wie Pixel Shading und Ray Tracing ähneln, die durch GPUs stark beschleunigt werden.
Im Gegensatz zu CGI-Grafiken und Bildern erfordern ML- und Deep-Learning-Berechnungen jedoch häufig keine doppelte (64-Bit) oder sogar einfache (32-Bit) Genauigkeit. Dies ermöglicht eine weitere Leistungssteigerung, indem die Anzahl der für die Berechnungen verwendeten Gleitkommabits reduziert wird. In der frühen Deep-Learning-Forschung wurden in den letzten zehn Jahren handelsübliche GPU-Beschleunigerkarten verwendet. Jetzt haben Unternehmen wie Nvidia eine eigene Produktlinie von Rechenzentrums-GPUs, die auf wissenschaftliche und KI-Arbeitslasten zugeschnitten sind.
Kürzlich kündigte Nvidia eine neue Reihe von Grafikprozessoren (GPU) an, die speziell für die Steigerung der generativen KI-Leistung auf Desktops und Laptops konzipiert sind. Das Unternehmen hat auch eine Reihe von speziell entwickelten KI-Supercomputern eingeführt.
Einzelne Komponenten und Systemanforderungen
Die folgenden Systemkomponenten sind für die KI-Leistung am wichtigsten:
- CPU. Verantwortlich für den Betrieb des VM- oder Container-Subsystems, die Verteilung von Code an die GPUs und die Verarbeitung von I/O. Aktuelle Produkte verwenden den beliebten Xeon Scalable Platinum- oder Gold-Prozessor der fünften Generation, obwohl Systeme mit AMD Epyc-CPUs der vierten Generation (Rome) immer beliebter werden. Die CPUs der aktuellen Generation verfügen über zusätzliche Funktionen, die ML- und Deep-Learning-Inferenzoperationen erheblich beschleunigen, so dass sie sich für produktive KI-Arbeitslasten eignen, bei denen Modelle verwendet werden, die zuvor mit GPUs trainiert wurden.
- GPU. Ermöglicht ML- oder Deep Learning-Training und Inferenz – die Fähigkeit, Daten auf der Grundlage von Lernprozessen automatisch zu kategorisieren. Nvidia bietet mit seiner EGX-Reihe speziell entwickelte beschleunigte Server an. Die Grace-CPU des Unternehmens wurde ebenfalls mit Blick auf KI entwickelt und optimiert die Kommunikation zwischen CPU und GPU.
- Memory. KI-Operationen werden vom GPU-Memory ausgeführt, so dass das System-Memory in der Regel keinen Engpass darstellt, und Server verfügen in der Regel über 512 GB oder mehr DRAM. GPUs verwenden eingebettete Memory-Module mit hoher Bandbreite. Nvidia bezeichnet diese Module als Streaming-Multiprozessoren (SMs). Laut Nvidia enthält die Nvidia A100 GPU 108 SMs, einen 40 MB L2-Cache und bis zu 2039 GB/s Bandbreite von 80 GB an HBM2 Memory.
- Netzwerk. Da KI-Systeme häufig in Clustern zusammengefasst werden, um die Leistung zu skalieren, sind die Systeme in der Regel mit mehreren 10-GbE- oder 40-GbE-Ports ausgestattet.
- Storage IOPS. Die Übertragung von Daten zwischen dem Speicher- und dem Rechensubsystem ist ein weiterer Leistungsengpass für KI-Workloads. Daher verwenden die meisten Systeme lokale NVMe-Laufwerke anstelle von SATA-SSDs.
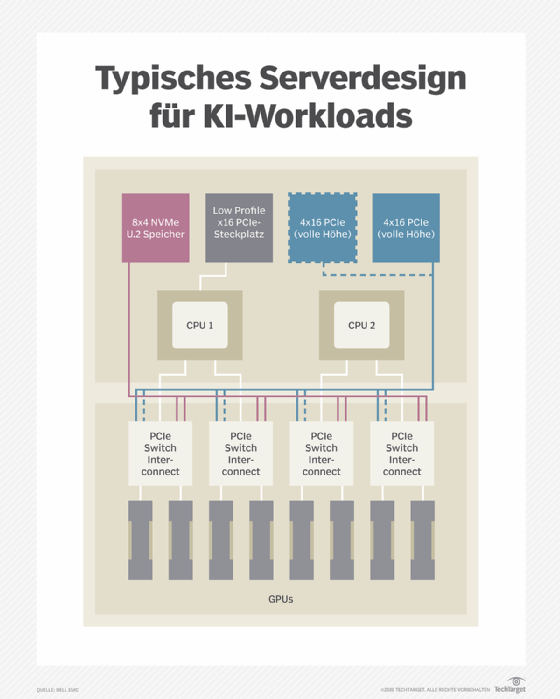
Grafikprozessoren sind das Arbeitspferd für die meisten KI-Workloads, und Nvidia hat seine Deep-Learning-Leistung durch Funktionen wie Tensor Core und Multi-Instance-GPUs (zur parallelen Ausführung mehrerer Prozesse und NVLink-GPU-Verbindungen) erheblich verbessert.
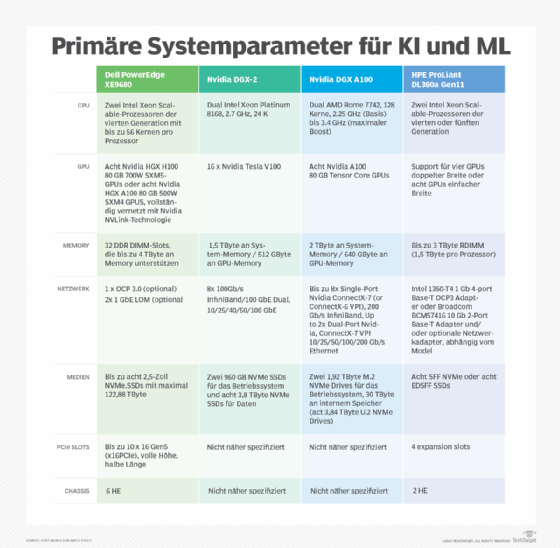
Unternehmen können jedes HCI- oder High-Density-System für KI nutzen, wenn sie die richtige Konfiguration und die richtigen Systemkomponenten wählen. Viele Anbieter bieten jedoch Produkte an, die auf ML- und Deep Learning-Workloads ausgerichtet sind. Im Folgenden finden Sie eine repräsentative Zusammenfassung der wichtigsten ML- und Deep Learning-Systemparameter führender Anbieter.
Anmerkung des Herausgebers:
Dieser Artikel über Infrastruktur für maschinelles Lernen und KI-Anforderungen wurde ursprünglich von Kurt Marko im Jahr 2020 verfasst und dann von Brien Posey im Jahr 2024 aktualisiert und erweitert. Dieser Artikel wurde aktualisiert, um aktuellere Informationen zu ML, KI und Systemanforderungen aufzunehmen. Der Autor hat neue Anbieterinformationen bereitgestellt, die auf den primären ML- und Deep-Learning-Systemparametern führender Unternehmen basieren.






