
REDPIXEL - stock.adobe.com
Tutorial: wie man eine CI/CD-Pipeline einrichtet
Mit Continuous Integration und Continuous Deployment können Sie Ihr Projekt optimieren und die Entwicklerarbeit erleichtern. Das Tutorial zeigt die erforderlichen Schritte.
Continuous Integration (CI) und Continuous Deployment (CD), also die kontinuierliche Integration und Bereitstellung von Software, bietet enorme Vorteile für jedes IT-Projekt.
CI führt während der Entwicklung eines Projekts permanent verschiedene Validierungen und Tests an der Codebasis durch. So kann die CI-Pipeline einer Anwendung beispielsweise die Formatierung prüfen. Dabei kann sie Fehler wie kleingeschriebene Variable, die großgeschrieben werden sollten, hervorheben. Sie kann auch jedes Mal, wenn ein Entwickler neuen Code überträgt, Unit-Tests oder Leistungstests ausführen.
Während Continuous Integration die Entwicklungsarbeit optimiert, bezieht sich Continuous Deployment (CD) auf die automatisierte Bereitstellung. Diese wird durchgeführt, nachdem ein Projekt alle Validierungen bestanden hat, die im CI-Teil einer CI/CD-Pipeline eingerichtet wurden.
Continuous Integration und Continuous Deployment ergänzen sich gegenseitig. Eine starke CI-Pipeline, die mehrere Testphasen durchläuft, stellt sicher, dass eine Anwendung gültig, korrekt und startklar für die Bereitstellung ist. Ein Erfolg in den frühen Testphasen löst die Continuous-Deployment-Phase aus und stellt die Anwendung bereit, sobald sie die automatisierten Testanforderungen erfüllt.
Dieser Prozess spart unzählige Entwicklerstunden. Weil die Anwendungen automatisch getestet und bereitgestellt werden, können sich die Entwickler auf die Erstellung neuer Funktionen konzentrieren.
Schauen wir uns ein einfaches Beispiel für eine CI/CD-Pipeline an.
Eine CI/CD-Pipeline
In diesem CI/CD-Pipeline-Tutorial verwenden wir eine einfache Python-Webanwendung. Die Applikation nutzt Flask, ein beliebtes Python-Web-Framework. Weitere Informationen zu Flask finden Sie auf der Seite der Hauptdokumentation. Unser Beispielprojekt befindet sich in einem speziellen GitHub-Repository.
Schauen wir uns zunächst die verschiedenen Komponenten an. Sie werden dann verstehen, wie eine CI/CD-Pipeline verschiedene Tests durchführt und die Anwendung bereitstellt.
Zu Beginn stellt die Anwendung eine HTML-Seite im Stammverzeichnis der Webdomäne bereit. Dies ist in Abbildung 1 dargestellt.
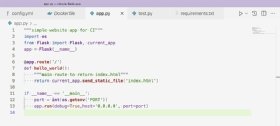
Dieses Basis-Setup für Flask definiert eine verfügbare Route für das Stammverzeichnis der Webdomäne. Das bedeutet, dass die Webanwendung nur auf Anfragen unter der URL example-domain.com/ antwortet.
In Zeile 11 wird die Anwendung mit app.run gestartet, einem einfachen Flask-Aufruf. Der Port wird in Zeile 12 mit einer Umgebungsvariablen festgelegt, die außerhalb unserer Anwendung gesetzt wird. Die Funktion os.getenv wendet sich an das System, auf dem die Python-Anwendung läuft. Sie findet den Wert der Umgebungsvariablen für das angegebene Argument. In diesem Fall ist es PORT.
Das System, auf dem die Python-Anwendung in diesem CI/CD-Tutorial läuft, ist ein Heroku-Server. Der Heroku-Server setzt die Umgebungsvariable PORT auf den richtigen Port, um den Docker-Container auf dem Webserver von Heroku auszuführen.
Überprüfen Sie die Pipeline
Nachdem wir nun die Flask-Anwendung verstanden haben, wollen wir uns unsere CI/CD-Pipeline ansehen. In diesem Tutorial verwende ich CircleCI als CI/CD-System. Es gibt aber viele andere Möglichkeiten. CircleCI ist ein kostenloses Tool, mit dem Projekte verschiedene Befehle und Prozesse bei jedem Commit an ein Git-Repository ausführen können. Um die Befehle und Prozesse zu definieren, verwenden wir eine YAML-Datei. Unsere YAML-Datei definiert vier verschiedene Prozesse, die ausgeführt werden sollen: Lint, Test, Build und Deploy.
Die Lint-Phase sucht nach möglichen Fehlern und Formatierungsproblemen. Dabei wird der Code nicht ausgeführt. Das in diesem Fall verwendete Linting-Programm ist ein beliebtes Tool namens Pylint. Pylint identifiziert stilistische Probleme im Code der Anwendung, die zu technischen Schulden und schlechter Lesbarkeit beitragen. Dies können zum Beispiel Großbuchstaben sein, die klein geschrieben werden sollten. Abbildung 2 zeigt die Schritte zur Ausführung von Pylint.
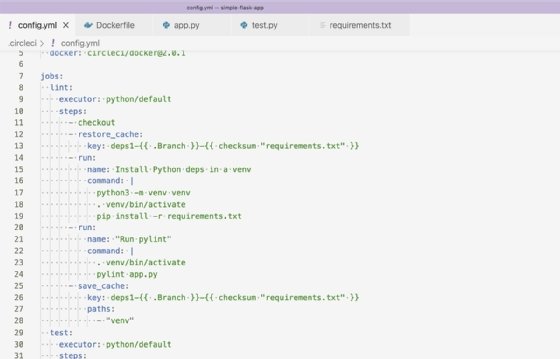
Im Lint-Job richten wir einen Cache für die zu installierenden Python-Abhängigkeiten ein. Dadurch werden die Build-Zeiten beschleunigt und das Pylint-Programm wird mit app.py ausgeführt. Das Cache-Setup ist eine CircleCI-Funktion, die es ermöglicht, Dateien über Build-Ausführungen hinweg beizubehalten. In diesem Tutorial werden die heruntergeladenen Abhängigkeiten über mehrere Build-Ausführungen hinweg beibehalten, um zu vermeiden, dass für jeden Build die gleichen Dateien heruntergeladen werden.
Abbildung 3 ist ein Beispiel für eine fehlgeschlagene Lint-Ausführungen von CircleCI.
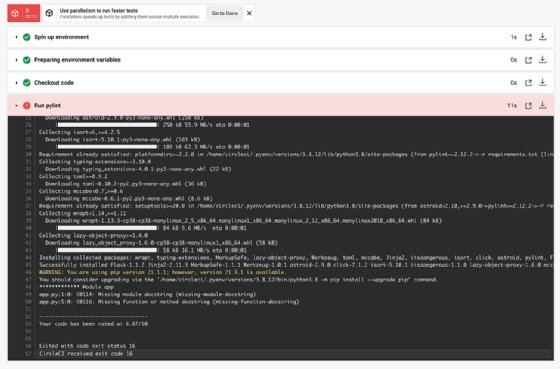
Pylint meldet die Zeilen, die geändert werden müssen, zusammen mit dem gefundenen Fehlertyp. Von dort aus kann ein Entwickler Probleme beheben und die Codequalität verbessern.
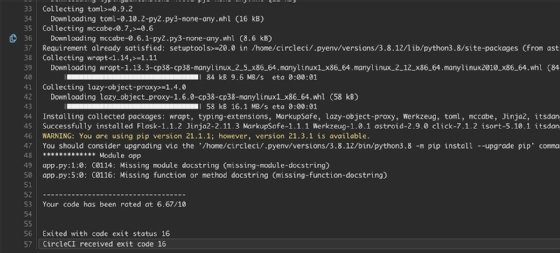
Der nächste Schritt in unserem CI/CD-Pipeline-Tutorial ist das Testen. Die Tests in unserem Projekt werden mit dem unittest-Framework ausgeführt – wie in Abbildung 5 dargestellt.
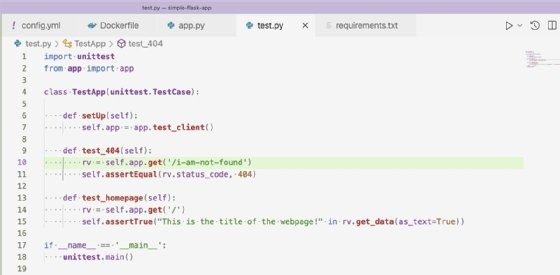
Die Tests überprüfen, ob unsere Anwendung einen 404-Antwortcode zurückgibt und ob die Root-Domäne unser HTML korrekt ausgibt. Die Schritte zur Ausführung der Tests in unserer CircleCI-Konfigurations-YAML-Datei sind in Abbildung 6 dargestellt.
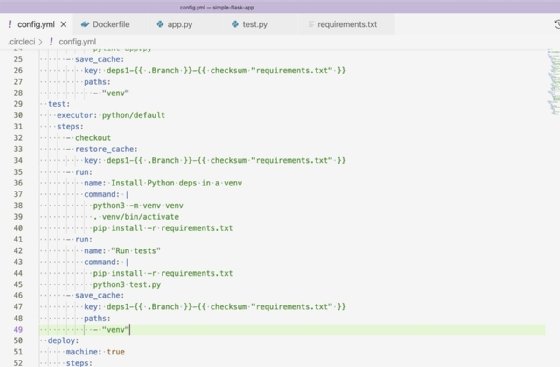
Verwenden Sie für die Abhängigkeiten im Testjob den gleichen Cache wie im Lint-Job und führen Sie die Tests mit Python3 test.py aus. Das Ablaufen der Tests bei jedem Commit ist entscheidend für den Erfolg eines Projekts. Diese Tests ermöglichen es den Entwicklern, Probleme mit ihrem Code schnell zu erkennen und schützen sie vor Rückschritten, wenn sie Funktionen hinzufügen oder aktualisieren.
Die letzte Validierung vor der Bereitstellung ist ein Docker-Build. Führen Sie die Docker-Datei aus, um sicherzustellen, dass sie korrekt ist. Prüfen Sie dann Ressourcen wie die Python-Datei für Paketanforderungen, die von der Docker-Datei verwendet wird. Unsere Docker-Datei sieht wie in Abbildung 7 dargestellt aus.
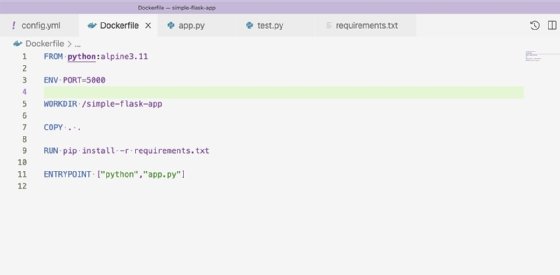
Das Docker-File erstellt unsere Python-Anwendung in einem Docker-Image und stellt den Befehl bereit, um die Anwendung beim Start des Containers auszuführen. Docker bietet einen CircleCI orb an. Dieser ist eine Abstraktion von CircleCI-Befehlen, die in einem importierbaren Job enthalten sind. Aus diesem Grund werden die Schritte zur Erstellung des Dockerfiles durchgeführt wie in Abbildung 8 dargestellt.

Die Zeilen 66-68 verweisen auf den Docker-Orb und definieren, wie der Docker-Job ausgeführt werden soll. Setzen Sie das Attribut deploy auf false. Damit weisen Sie den Docker/publish-Job an, das Image zu erstellen, ohne es in ein Repository zu pushen. Standardmäßig findet der Docker/publish-Job die Docker-Datei anhand des Namens und erstellt sie. Wenn der Docker-Build fehlschlägt, wird der Auftrag ebenfalls abgebrochen.
Nachdem die drei Phasen – Lint, Test und Build – erfolgreich verlaufen sind, können wir unsere Anwendung bereitstellen. Für dieses Projekt habe ich Heroku verwendet, einen Hosting-Dienst für Anwendungen, der einfach eingerichtet werden kann.
Heroku bietet ein Command Line Interface (CLI), das mit GitHub zusammenarbeiten kann und unterstützt verschiedene Bereitstellungsmethoden. Für unser CI/CD-Tutorial verwenden wir die Heroku CLI. Damit lässt sich ein Container erstellen und unser Docker-Image kann an Heroku übertragen werden. Heroku führt das Image dann als Container aus. Der Job zur Bereitstellung unseres Images für Heroku ist in Abbildung 9 zu sehen.
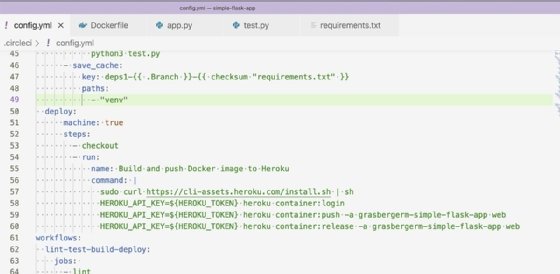
In Zeile 57 wird die Heroku CLI installiert. Dann werden die Befehle zum Erstellen und Freigeben des Containers ausgeführt. Die Umgebungsvariable HEROKU_TOKEN wird benötigt, um unsere Heroku-Anmeldedaten zu authentifizieren und unser Image hochzuladen. Der Wert für HEROKU_TOKEN findet sich in den Heroku-Kontoeinstellungen und kann CircleCI über die Umgebungsvariablen des Projekts zur Verfügung gestellt werden.
Die CI/CD-Pipeline dieses Projekts prüft die Anwendung ständig auf ordnungsgemäße Formatierung und Korrektheit. Wenn diese Anforderungen erfüllt sind, wird ein Docker-Image automatisch auf Heroku bereitgestellt. Dort wird die Anwendung dann ausgeführt. Um dieses Beispiel weiter zu erkunden, können Sie die Anwendung und die verwendete Pipeline genauer unter die Lupe nehmen.






