Operativ arbeiten im Netzwerk: Fehlersuche und Monitoring
Die Fehleridentifizierung im Netzwerk kann der Suche nach der Nadel im Heuhaufen ähneln. Glücklicherweise gibt es viele kleine Helferlein. Proaktives Monitoring ist jedoch Pflicht.
von
Thomas Bär,Redaktionsgemeinschaft Thomas Bär & Frank-Michael Schlede
Für kleinere Fehleranalysen muss der Administrator meist nicht einmal ein Programm installieren, denn die klassischen Werkzeuge zur Fehlereingrenzung bringen die wichtigsten Systeme gleich mit.
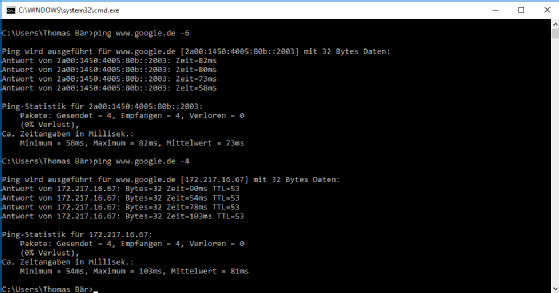
Die einfache Erreichbarkeit über einen Ping/Echo-Request prüfen selbst Switches aus dem untersten Preissegment direkt aus einer Weboberfläche heraus. Das gilt zumindest für die Prüfung unter IPv4, in diesem Preisfeld ist das Umschalten auf IPv6 in der Regel nicht möglich. Jeder halbwegs aktuelle Windows-Computer nutzt durch das Anhängen des Schalters -6 beim Ping-Kommando das jüngere Protokoll, Linux/Unix-Systeme nutzen stattdessen ping6 für den Aufruf.
Mit einem Loop können selbst moderne Netzwerke unter Druck geraten, wenn größere Netzwerkpaketmengen offensichtlich sinnlos zwischen Switches transportiert werden. Während beim Routing das Herunterzählen der Hops dafür sorgt, dass das Paket irgendwann einmal verworfen wird, sobald der TTL-Zähler (Time-to-Live, Lebensdauer in Sekunden/Router-Kontakten) verbraucht ist. Unglücklicherweise gehen einige IT-Profis davon aus, dass dies auch beim Switching der Fall sein müsste. Jedoch existiert auf dem OSI-Layer 2 (dem Data Link Layer) überhaupt kein TTL. Glücklicherweise verfügen die meisten verwalteten Switches, das gilt auch für Smart-Managed-Systeme, die nur über eine Weboberfläche, nicht aber einen CLI-Zugang verfügen, über eine Loop-Protection. Sollte es bei Verbindungen zwischen Switches zu Störungen kommen, könnte ein unbeabsichtigte Netzwerkschleife die Ursache sein.
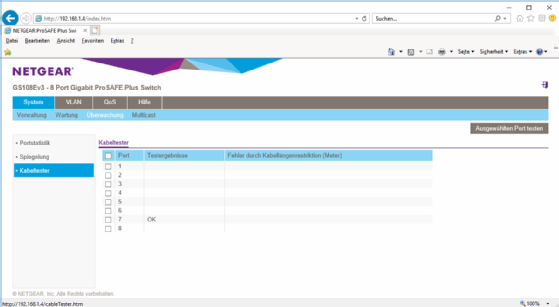
Auf einem wahrlich nicht teuren Smart Managed Switch von Netgear entdeckten wir sogar einen eingebauten Netzwerkkabelprüfer. Was früher einmal auf die Featureliste für hochpreisige Enterprise-Systeme beschränkt war, erledigt heute jede Wald-und-Wiesen-Hardware für den SOHO-Einsatz.
Abbildung 1: Integrierte Kabelprüfungen bieten schon kostengünstige Swiches.
Kabel und Steckverbindungen prüfen
Es kommt bei fertig konfektionierten Kabeln zwar sehr selten vor, doch einen Kabelfehler kann der Administrator niemals ausschließen. Will sich eine Verbindung zwischen zwei Netzwerkteilnehmern einfach nicht herbeiführen lassen, gilt es, die beteiligten Kabel Schritt für Schritt zu prüfen. Nicht immer ist eine ausgefallene Komponente oder ein Konfigurationsfehler der Schuldige. Selbst Kabel- oder Steckverbindungen, die seit vielen Jahren ohne Probleme arbeiten, können von jetzt auf gleich versagen.
Abbildung 2: Ping-Prüfungen können Administrator zügig für IPv4 oder IPv6 durchführen.
Ist kein Prüfwerkzeug zur Hand, hilft ein Laptop in der Nähe des Switches. Um einen Kabelfehler zu lokalisieren, muss der Netzwerkprofi mit demselben Patchkabel an demselben Patchfeld eine Verbindung herstellen. Bekommt auch der mobile Computer keine Verbindung, ist es höchstwahrscheinlich das Kabel. Ein guter Rat in der Literatur besagt: „Schneide die Stecker ab und ab zur Entsorgung!“.
Funktioniert die Verbindung trotz Kabelaustausch nicht, ist der Einsatz eines Netzwerktesters unerlässlich. Geräte dieser Art gibt es bereits recht günstig im Fachhandel. Ein Tester verfügt über zwei Netzwerkanschlüsse und einen so genannten Satelliten für den Fall, dass eine Einzelstrecke zu testen ist. Das Gerät prüft neben der Durchgängigkeit einer jeden Kupferader auch die Schirmung des Kabels. Je nach Modell wird fortlaufend zwischen den Adern gewechselt oder der Anwender wählt die gewünschte Position manuell.
Abbildung 3: Netzwerkkabelprüfer mit externem Terminator sind recht günstig.
Simple Kabelfehler, wie nicht aufgelegte oder unterbrochene Adern, lassen sich schon mit den einfachen Geräten identifizieren. Insbesondere in älteren Gebäuden muss der IT-Profi damit rechnen, dass nicht alle Adern 1:1 durchgeschaltet wurden. Möglicherweise wurden die Anschlüsse nur für den 10Base-T- oder 100Base-T-Einsatz geplant. In diesem Fall sind lediglich vier der acht Adern tatsächlich im Einsatz. Um genauere Messwerte zu ermitteln, zum Beispiel die Kabellänge, Dämpfung, Kapazität, Widerstand, Signalverzögerung oder Impedanz sind deutlich teurere Messgeräte erforderlich.
Netzwerk-Monitoring
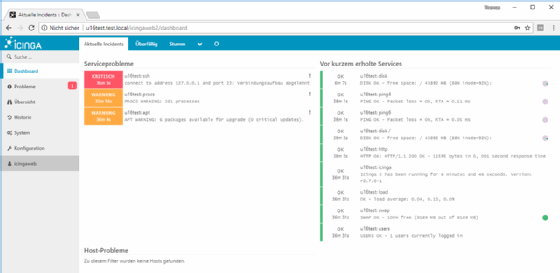
Die wichtigste Informationsquelle über das Netzwerk ist das Netzwerk selbst – und zwar im regulären Zustand. Wer als Netzwerkexperte erst dann hinzugezogen wird, wenn eine Unzuverlässigkeit oder Verlangsamung den Betrieb stört, wird sich bei der Analyse schwertun. Die durchschnittliche Auslastung, Latenzwerte, das Anmeldeverhalten zu morgendlicher Stunde, die übliche zeitliche Dauer für ein Backup, die gewöhnliche Verteilung von Netzwerkprotokollen und das Verhältnis von QoS-pflichtiger Dienste wie VoIP zum regulären Datenverkehr – diese Werte stellen die spezifische Signatur der Netzwerkumgebung dar.
Von dieser kleinen Auswahl muss der IT-Verantwortliche nur einen Bruchteil aus dem Stehgreif wissen – beispielsweise die typische Anmeldedauer auf einer Remote-Desktop-Farm oder die Anzahl gleichzeitig aktiver Sessions. Glücklicherweise muss sich der Netzwerkverantwortliche nicht als lebendiges Nachschlagewerk versuchen – er muss nur wissen, wo er die üblichen Werte findet. Hierzu bedient sich der Profi an den Netzwerk-Monitoring-Programmen, die mithilfe von Syslog-, SNMP-, NetFlow- oder WMI-Daten (Windows Management Instrumentation) regelmäßig abfragen und in einer Datenbank speichern.
Grundsätzlich gibt es Netzwerk-Monitoring-Lösungen zweier unterschiedliche Überwachungsarten: passives und aktives Monitoring. Bei der aktiven Überwachung wird die Reaktion eines Netzwerkgeräts, typischerweise das Rücksenden der Ping/Echo-Anfrage oder der Ausfall eines Dienstes, geprüft. Als aktive Monitore bieten die Lösungen DNS, Echo, FTP, HTTP, HTTPS, IMAP4, Interface, NNTP, Ping, Printer, POP3, RADIUS, SMTP, SNMP, Telnet oder Time als Protokoll beziehungsweise Funktion.
Während der IT-Profi sich bei Icinga um jedes Detail komplett selbst zu kümmern hat, ist der Anwender bei den kostenpflichtigen Programmen meist mit wenigen Mausklicks fertig.
Bei den kommerziellen Netzwerk-Überwachungssoftware gibt es drei Namen, an denen der Administrator nicht vorbeikommt: Whats Up von Ipswitch, NPM/Orion von Solarwinds und PRTG von Paessler. Im Vergleich zu den Open-Source-Lösungen überzeugen die Platzhirsche durch eine ausgezeichnete Erkennungsfunktion und durch eine Vielzahl von Assistenten, die die Einrichtung der Überwachung an sich viel einfacher werden lässt. Während der IT-Profi sich bei Icinga um jedes Detail komplett selbst zu kümmern hat, ist der Anwender bei den kostenpflichtigen Programmen meist mit wenigen Mausklicks fertig.
Um Leistungsdaten und Funktionen im Windows-Umfeld zu verarbeiten, nutzen Administratoren üblicherweise WMI. Die WMI-Auswertung bietet die Ipswitch-Lösung jedoch erst in den höheren Varianten. Das passive Netzwerk-Monitoring prüft über die so genannten Listener-Meldungen, die die Server oder Netzwerkgeräte aussenden – beispielsweise SNMP-Nachrichten von Switches bei Statusänderungen eines Netzwerk-Interfaces oder Eventlog-Einträge der Anti-Threat-Software auf Windows-Computern.
Bei der Lizenzierung macht es das aus Nürnberg stammende PRTG dem Anwender etwas einfacher – sehr viele Monitoring-Funktionen benötigen lediglich einen so genannten Sensor. Ein Sensor wäre beispielsweise ein Ping/Echo-Request, ein weiterer Sensor eine Jitter-Überwachung. Überwacht der Server beide Werte auf einem Gerät, so sind auch zwei Sensoren erforderlich.
Die Jitter-Überwachung ist insgesamt sehr zielführend: Datenpakete werden in einem bestimmten Tempo übertragen. Ein Sender schickt in einem Millisekunden-Takt Pakete an einen Empfänger. Wenn dies aus dem Takt gerät, es also zu Schwankungen oder Laufzeit-Unregelmäßigkeiten kommt, bezeichnet man dies als Jitter. Der Begriff steht für Fluktuation, Schwankung oder auch Taktzittern. Es gibt Dienste, E-Mail oder Web, die der entstehende Jitter kaum beeinflusst, VoIP-Telefonie oder Videokonferenzen bekommen jedoch Aussetzer.
Ein hoher Jitter-Wert entsteht zum Beispiel bei hoher Auslastung der Datenleitung und Engpässen in den zwischengeschalteten Geräten. Ist die verbleibende Bandbreite zu gering, kann der Jitter steigen. Datenstau in Switches oder Router-Verbindungen stellen eine weitere Quelle eines höheren Jitters dar. Gute Monitoring-Lösungen prüfen und berechnen den Jitter anhand der von der IETF definierten Kalkulation gemäß RFC 3550.
Virtualisierte Netzwerke und Server unterstützen beide Programme schon eine ganze Weile. Automatisches Erkennen und fortgeschrittene Überwachung waren zunächst auf reine VMware-Umgebungen beschränkt. In den jüngeren Versionen können Administratoren nun auch für Microsoft Hyper V Erkennungsfunktionen nutzen und die Umgebungen überwachen. Die Überwachung von virtuellen Netzwerken kann zunächst einmal identisch zum Monitoring von physischen Netzen geschehen, auf Dauer sollte jedoch die dahinterstehende Host-Struktur der Virtualisierungsplattform mitbedacht werden. Die Einbindung von Cloud-Diensten wie Amazon EC2, Rackspace oder Microsoft Azure in die Überwachung ist bei allen großen Monitoring-Systemen in der jüngeren Vergangenheit forciert worden.
Freeware Monitoring
Es sind in erster Linie zwei kostenfreie Monitoring-Programme, die sich über eine ausreichend hohe Verbreitung erfreuen. Einerseits ist das die Community-Software Spiceworks und andererseits die bekanntere Open-Source-Variante Nagios Core. Unter dem Namen Icinga beschloss ein Teil der Nagios-Community, sich vom ursprünglichen Zweig loszulösen, um eine eigene Variante auf den Weg zu bringen. Seit 2014 gibt es mit Icinga 2 eine komplette Neuentwicklung mit erneuerter Konfigurationssprache, integriertem Cluster-Stack und verbesserter Ausnutzung des Multithreadings. Icinga 2 ist, wie Nagios eben auch, eine System- und Netzwerk-Überwachungsapplikation. Zu den Kernfunktionen gehören seit der frühen Version das Überwachen von Netzwerkdiensten wie SMTP, POP3, HTTP, NNTP oder Ping/Echo-Request und die Überwachung von Ressourcen, beispielsweise CPU- oder Plattenauslastung.
Abbildung 4: Netzwerk-Monitoring ist die wichtigste Grundlage bei der Fehlersuche.
Anders als bei den kommerziellen Lösungen oder der Community-Software Spiceworks, ist der Administrator bei Icinga und Nagios gezwungen, sich mit den einzelnen Modulen der Überwachung sehr intensiv auseinanderzusetzen. Die Flexibilität beruht jedoch darauf, dass Icinga 2 selbst gar keine Funktionalität zur direkten Überwachung mitbringt. Stattdessen interpretiert die Software die Rückmeldungen der eingesetzten Plug-ins. Kurz gesagt: Wenn eine ausführbare Datei eine Überwachungsmöglichkeit darstellt, kann der IT-Profi dies in Icinga 2 integrieren.
Ein leicht verständliches Plug-in-Design soll es dem Administrator ermöglichen, eigene Serviceprüfungen zu etablieren, ohne sich mit den vielen technischen Herausforderungen, wie bei Nagios selbst, auseinandersetzen zu müssen. Insbesondere im Zusammenspiel mit SNMP kann Icinga 2 auch dabei helfen, wichtige Messdaten aus dem Netzwerk zu protokollieren. Wenn es um die reine Fehleranalyse geht, ist Icinga 2 jedoch nicht unbedingt die erste Wahl – hier kommen traditionell Sniffer wie Wireshark zum Einsatz – hierzu mehr im nächsten Teil.