Leitfaden zum Thema Hochverfügbarkeit und Best Practices für VMware HA
VMware HA (High Availability) und FT (Fault Tolerance) sind nicht das Gleiche. Elias Khnaser erklärt in diesem Beitrag die Unterschiede.

VMware HA (High Availability) ist eine Komponente, die die Notwendigkeit von dedizierter Standby-Hardware und -Software in einer virtualisierten Umgebung obsolet macht. Man setzt VMware HA oftmals ein, um die Zuverlässigkeit zu erhöhen, die Ausfallzeit in virtuellen Umgebungen geringer zu halten und das Disaster-Recovery (DR), beziehungsweise die Business Continuity (BC)zu optimieren.
Dieser Auszug des Kapitels aus dem Buch VCP4 Exam Cram: VMware Certifie Professional, 2nd Edition von Elias Khnaser kümmert sich um Best Practices für VMware HA. Im Anschluss finden Sie einen Auszug. Bei Gefallen können Sie das komplette Kapitel über Backup und High Availability als PDF (Englisch) herunterladen.
VMware High Availability (HA) kümmert sich in erster Linie um Host-Ausfälle bei ESX/ESXi und was mit virtuellen Maschinen (VM) geschieht, die auf solchen Hosts laufen. HA kann außerdem eine virtuelle Maschine monitoren und neu starten, indem es überprüft, ob die VMware-Tools immer noch im Betrieb sind. Sollte ein ESX/ESXi-Host aus irgendwelchen Gründen ausfallen, betrifft das natürlich alle darauf laufenden virtuellen Maschinen. VMware HA stellt sicher, dass die virtuellen Maschinen des ausgefallenen Hosts auf anderen ESX/ESXi-Hosts neu gestartet werden können.
Viele Anwender verwechseln VMware HA mit Fehler-Toleranz (Fault Tolerance). VMware HA ist nicht fehlertolerant. Fällt ein Host aus, sind auch die virtuellen Maschinen zunächst nicht mehr erreichbar. HA kümmert sich lediglich darum, dass die entsprechenden virtuellen Maschinen auf anderen ESX/ESXi-Hosts mit genügend Ressourcen neu gestartet werden. Fault Tolerance auf der anderen Seite garantiert einen unterbrechungsfreien Zugriff auf Ressourcen, sollte ein Host ausfallen.
VMware HA kommuniziert mit allen anderen ESX/ESXi-Hosts, die Mitglieder des gleichen Clusters sind und benutzt dafür einen sogenannten Heartbeat. Bei vSphere 4.0 wird er per Standard alle Sekunde und bei vSphere 4.1 alle zehn Sekunden geschickt. Sollte ein ESX-Server auf einen Heartbeat nicht reagieren, warten die anderen Hosts 15 Sekunden auf eine Antwort.
Nach 15 Sekunden initiiert der Cluster den Neustart der virtuellen Maschinen, die sich auf dem nicht mehr erreichbaren ESX/ESXi-Host befanden. Die virtuellen Maschinen werden auf den verbleibenden ESX/ESXi-Hosts hochgefahren. VMware HA überwacht außerdem alle ESX/ESXi-Hosts desselben Clusters und stellt sicher, dass immer genügend Ressourcen verfügbar sind, um auf einen potenziellen Ausfall vorbereitet zu sein.
Virtual Machine Failure Monitoring
Virtual Machine Failure Monitoring ist eine Technologie, die per Standard deaktiviert ist. Die Aufgabe besteht darin, virtuelle Maschinen zu monitoren, indem diese alle 20 Sekunden mithilfe eines Heartbeats adressiert werden.
Die Software verwendet dafür die VMware Tools, die innerhalb einer virtuellen Maschine installiert sind. Sollte eine VM auf einen Heartbeat nicht reagieren, stuft VMware HA diese virtuelle Maschine als ausgefallen ein und versucht, sie zurückzusetzen. Somit könnte man Virtual Machine Failure Monitoring als eine Art High Availability für virtuelle Maschinen betrachten.
Virtual Machine Failure Monitoring kann erkennen, ob eine virtuelle Maschine manuell heruntergefahren, in den Schlafzustand versetzt oder migriert wurde. In diesem Fall leitet die Software keinen Neustart ein.
Konfigurations-Voraussetzungen für VMware HA
Damit VMware HA angemessen funktioniert, sind folgende Konfigurations-Voraussetzungen notwendig:
- vCenter: Weil VMware HA eine Funktion der Enterprise-Klasse ist, benötigen Sie für eine Aktivierung vSphere
- DSN-Auflösung: Alle ESX/ESXi-Hosts, die Mitglieder des HA-Clusters sind, müssen die anderen mithilfe von DNS auflösen können.
- Zugriff auf gemeinsam genutztes (shared) Storage: Alle Hosts im HA-Cluster müssen Zugriff auf das gleiche gemeinsam genutzte Storage haben. Ansonsten hätten sie keinen Zugriff auf die virtuellen Maschinen.
- Zugriff auf das gleiche Netzwerk: Alle ESX/ESXi-Hosts müssen Zugriff auf die gleichen Netzwerke haben, die auf allen Hosts konfiguriert sind. Sollte eine virtuelle Maschine auf einem anderen Host gestartet werden, hat sie wiederum Zugriff auf das richtige Netzwerk.
Redundanz für Service Console
Es wird dringend empfohlen, dass es für die Service Console (SC) Redundanz gibt. VMware HA reagiert und gibt eine Warnung aus, wenn die Komponente erkennt, dass die Service Console auf einem vSwitch mit nur einer vmnic konfiguriert ist. Wie Sie in Abbildung 1 weiter unten sehen, können Sie Redundanz für Service Console auf zwei Arten realisieren.
- Kreieren Sie zwei Service Console Port-Gruppen, jede davon auf einem unterschiedlichen vSwitch.
- Weisen Sie den Service Console vSwitch zwei physische NICs (Network Interface Cards / Netzwerkkarten) in Form eines NIC-Teams zu.

Abbildung 1: Redundanz für Service Console
In beiden Fällen müssen Sie den kompletten IP-Stack mit IP-Adresse, Subnetz und Gateway konfigurieren. Die Service Console vSwitches werden für Heartbeats und Status-Synchronisation benutzt und verwenden nachfolgende Ports:
- Incoming (eingehend) TCP-Port 8042
- Incoming UDP-Port 8045
- Outgoing (ausgehend) TCP-Port 2050
- Outgoing UDP-Port 2250
- Incoming TCP-Port 8042–8045
- Incoming UDP-Port 8042–8045
- Outgoing TCP-Port 2050–2250
- Outgoing UDP-Port 2050–2250
Konfigurieren Sie Redundanz für SC nicht richtig oder gar nicht, resultiert das bei Aktivierung von HA in einer Warnung. Wollen Sie diese Fehlermeldung also vermeiden und sich an die Best Practices halten, konfigurieren Sie angemessene Redundanz für SC.
Kapazitäts-Planung für Host Failover
Konfigurieren Sie HA, müssen Sie das Maximum an Host-Failure-Toleranz manuell konfigurieren. Das ist eine Aufgabe, die Sie während der Planungs-Phase und der Hardware-Bemessung sorgfältig in Betracht ziehen sollten. Es wird davon ausgegangen, dass Sie Ihre ESX/ESXi-Hosts mit genug Ressourcen versehen haben, um mehr virtuelle Maschinen als geplant darauf zu betreiben, um HA gerecht zu werden. In Abbildung 2 sehen Sie zum Beispiel, dass der HA-Cluster aus vier ESX-Hosts besteht.
Alle vier sind mit genug Kapazität ausgestattet, um mindestens vier weitere virtuelle Maschinen betreiben zu können. Weil bereits drei virtuelle Maschinen auf jedem Host laufen, könnte dieser Cluster sogar mit dem Ausfall von zwei ESX/ESXi-Hosts zurecht kommen. Die verbleibenden zwei ESX/ESXi-Hosts können ohne Probleme die sechs ausgefallenen virtuellen Maschinen kompensieren.
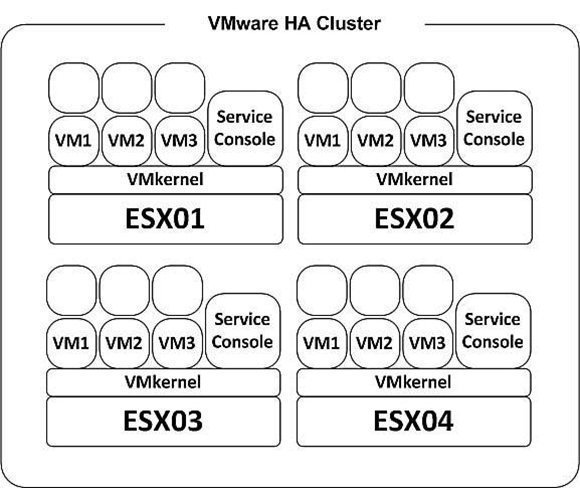
Abbildung 2: Kapazitäten-Planung für HA
Während der Konfigurations-Phase des HA-Clusters wird Ihnen ein ähnlicher Bildschirm präsentiert wie in Abbildung 3. Dort können Sie die Cluster-weite Konfiguration mit nachfolgenden Optionen definieren.
Host Monitoring Status
- Enable Host Monitoring: Mithilfe dieser Einstellung können Sie kontrollieren, ob der HA-Cluster die Hosts auf einen Heartbeat monitoren soll. Dies ist die Art und Weise, wie der Cluster erkennt, ob ein Host immer noch aktiv ist. In einigen Fällen ist es ratsam, diese Option zu deaktivieren, um die Isolation eines Hosts zu vermeiden. Zum Beispiel sind Wartungs-Arbeiten ein Grund.
Admission Control
- Enable: Do not power on VMs that violate availability constraints: Mit Aktivierung dieser Option bestimmen Sie, dass virtuelle Maschinen nicht aktiviert werden, sollten nicht genügend Ressourcen vorhanden sein.
- Disable: Power on VMs that violate availability constraints: Hier können Sie festlegen, dass virtuelle Maschinen auch dann hochgefahren werden, wenn es eigentlich nicht genügend Ressourcen gibt (Overcommitting).
Admission Control Policy
- Host failures cluster tolerated: Mit dieser Einstellungen bestimmen Sie, wie viele Ausfälle im Hinblick auf die Hosts zu tolerieren sind. Die erlaubten Einstellungen sind 1 bis 4.
- Percentage of cluster resourcen reserved as failover spare capacity: Wählen Sie diese Option, reservieren Sie damit einen gewissen Prozentsatz der kompletten Cluster-Ressourcen für den Notfall. Bei einem Cluster mit vier Hosts entsprächen 25 Prozent im Endeffekt die Reservierung eines gesamten Hosts für Failover. Sollte das nicht Ihren Anforderungen entsprechen, können Sie natürlich zum Beispiel auch zehn Prozent wählen.
- Specify a failover host: Mit dieser Einstellung können Sie einen speziellen Host als Failover Host im Cluster bestimmen. Das könnte der Fall sein, wenn Sie einen Reserve-Host besitzen oder wenn ein Host signifikant mehr Computing- oder Arbeitsspeicher-Ressourcen als die anderen besitzt.
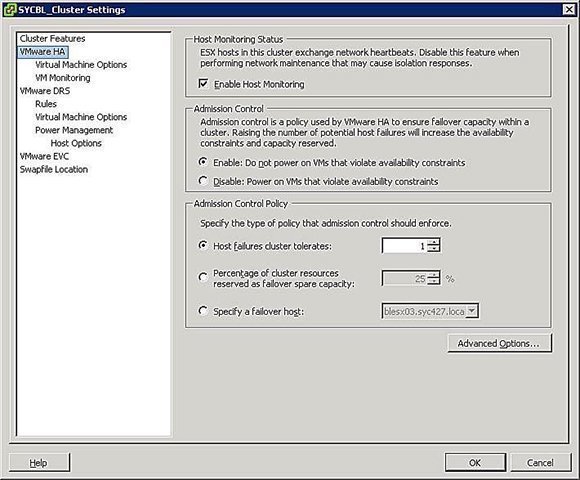
Abbildung 3: Die Richtlinien (Policies) für den gesamten Cluster
Isolation eines Hosts
Wenn ein ESX/ESXi-Hosts im Cluster nicht mehr auf einen Heartbeat reagiert, kommt es zu einem Netzwerk-Phänomen, das sich Split-Brain nennt. Bei vSphere 4.0 wird der Heartbeat alle Sekunde und bei vSphere 4.1 alle zehn Sekunden per Standard geschickt. Sollte es keine Antwort geben, geht der Cluster davon aus, dass ein ESX/ESXi-Host ausgefallen ist. Tritt dieser Fall ein, hat der ESX/ESXi-Host die Netzwerk-Verbindung an der Management-Schnittstelle verloren.
Möglicherweise läuft der Host aber noch und die virtuellen Maschinen sind vielleicht nicht einmal betroffen, weil sie eine andere Netzwerk-Schnittstelle verwenden. vSphere muss aber reagieren, wenn das passiert. Aus diesem Grund wurde Host-Isolation entwickelt. Das ist die Art, wie HA einen ESX/ESXi-Host behandelt, wenn er seine Netzwerk-Verbindung verloren hat.
Sie können bestimmen, was mit virtuellen Maschinen im Falle einer Host-Isolation passieren soll. Sie erreichen den Bildschirm für VM Isolation Response, indem Sie mit einem Rechtsklick auf den entsprechenden Cluster klicken und danach auf Edit Settings. Im Anschluss klicken Sie auf Virtual Machine Options auf der linken Seiten unter dem VMware-HA-Logo.
Hier können Sie nun die Host-Isolations-Optionen entsprechend konfigurieren. Die Einstellungen vererben sich auf alle virtuellen Maschinen des betroffenen Hosts. Sie haben aber auch die Möglichkeit, die Cluster-Einstellungen zu überschreiben, wenn Sie auf VM-Ebene eine andere Reaktions-Option einstellen.
Wie Sie in Abbildung 4 sehen, haben Sie folgende Optionen bei Isolation Response:
- Leave Powered On: Wählen Sie diesen Option, laufen die virtuellen Maschinen auch im Falle einer Host-Isolation weiter.
- Power Off: Sollte es zu einer Host-Isolation kommen, wird die jeweilige virtuelle Maschine ausgeschaltet. Es handelt sich hier um das Äquivalent zum Stecker ziehen.
- Shut Down: Im Falle einer Host-Isolation wird die virtuelle Maschine sauber mithilfe der VMware Tools heruntergefahren. Sollte diese Aufgabe binnen fünf Minuten nicht erledigt sein, wird entsprechend der virtuelle Stecker gezogen. Sollten die VMware Tools nicht installiert sein, wird die VM sofort abgeschaltet.
- Use Cluster Setting: Mit dieser Einstellung verwenden Sie die Konfiguration, die für den gesamten Cluster gilt.
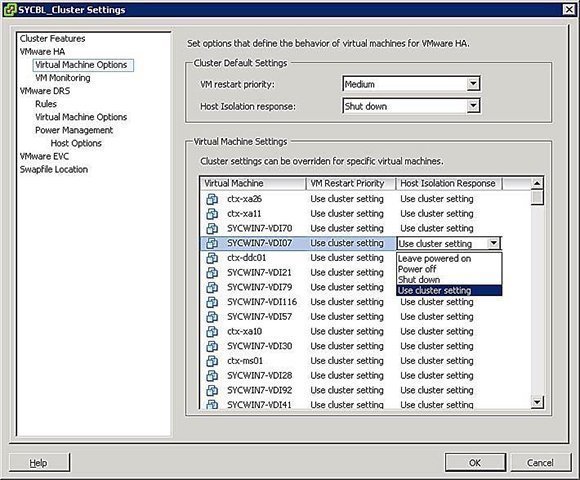
Abbildung 4: VM-spezifische Isolations-Richtlinie
Sollte es zu einer Isolation kommen, muss der Host nicht zwingend ausgefallen sein. Die virtuellen Maschinen könnten mit verschiedenen physischen NICs konfiguriert und somit mit verschiedenen Netzwerken verbunden sein. In diesem Fall funktionieren Sie womöglich wie gehabt. Dies sollten Sie bedenken, wenn Sie die Prioritäten für die Isolation setzen. Ist ein Host isoliert, bedeutet das lediglich, dass seine Service Console nicht mit dem Rest der ESX/ESXi-Hosts im Cluster kommunizieren kann.
Wiederherstellungs-Prioritäten hinsichtlich der virtuellen Maschinen
Sollte ein HA-Cluster nicht mit allen virtuellen Maschinen bei einem Ausfall zurechtkommen, können Sie gewisse Prioritäten setzen. Damit bestimmen Sie, welche virtuellen Maschinen zuerst neu gestartet werden und welche weniger wichtig sind.
Sie konfigurieren diesen Einstellungen im selben Bildschirm wie die Isolation Response, über die wir weiter oben gesprochen haben. Auch hier lassen sich die Einstellungen für den gesamten Cluster bestimmen oder Sie setzen diese entsprechend auf VM-Ebene.
Sie können die VM-Restart-Prioritäten wie folgt setzen:
- High: Virtuelle Maschinen mit hoher Priorität starten zuerst.
- Medium: Das ist die Standard-Einstellung.
- Low: Virtuelle Maschinen mit diesem Status starten als letztes.
- Use Cluster Setting: Virtuelle Maschinen werden anhand der Cluster-Einstellungen gestartet.
- Disabled: Die VM schaltet sich gar nicht an.
Sie sollten die Prioritäten nach Wichtigkeit der virtuellen Maschinen setzen. Anders gesagt wollen Sie Domain Controller sehr wahrscheinlich schon starten und Druck-Server eher nicht. Virtuelle Maschinen mit einer höheren Priorität starten zuerst. Können Sie bei einem Notfall auf bestimmte virtuelle Maschinen verzichten, sollten Sie diese gar nicht erst hochfahren. Das spart Ressourcen.
MSCS Clustering
Der Haupt-Zweck eines Cluster ist es, dass wichtige Systeme immerzu und dauerhaft verfügbar sind. Ähnlich wie bei physischen Clustern lassen sich auch virtuelle Maschinen mit ESX auf frei verschiedene Arten clustern:
- Cluster-in-a-box: Bei diesem Szenario sitzen alle virtuellen Maschinen, die Teil des Clusters sind, auf dem selben ESX/ESXi-Host. Wie Sie sicherlich schon richtig bemerkt haben, gibt es hier einen so genannten SPoF (Single Point of Failure) oder eine einzelne Schwachstelle. Das ist der ESX/ESXi-Host. Bei gemeinsam genutztem Storage lässt sich sagen, dass Sie virtuelle Festplatte als Shared Storage nutzen können. Möglich ist auch RDM (Raw Device Mapping) im virtuellen Kompatibilitäts-Modus.
- Cluster-across-boxes: Hier befinden sich Cluster-Nodes, also die VM-Mitglieder des Clusters, auf unterschiedlichen ESX/ESXi-Hosts. Jeder der Nodes im Cluster kann das gleiche Storage verwenden. Sollte eine VM ausfallen, haben andere Zugriff auf die gleichen Daten. Dieses Szenario ist eine ideale Cluster-Umgebung, um den SPoF zu eliminieren. Die Voraussetzung dafür ist Shared Storage, das via Fibre-Channel-SAN zur Verfügung gestellt wird. Sie müssen außerdem RDM in Physical oder Virtual Compatibility Mode einsetzen, da virtuelle Festplatten keine unterstützte Option für gemeinsam genutztes Storage sind.
- Pysical-to-virtual-cluster: In diesem Fall ist ein Mitglied des Clusters eine VM und das andere eine physische Maschine. Shared Storage ist Voraussetzung für dieses Szenario und die Konfiguration muss RDM in Physical Compatibility Mode sein.
Designen Sie eine Cluster-Lösung, müssen Sie das Problem mit Shared Storage adressieren. Somit können mehrere Hosts oder virtuelle Maschinen auf die gleichen Daten zugreifen. vSphere bietet mehrere Methoden an, wie Sie Provisioning von Shared Storage realisieren können:
- Virtuelle Festplatten: Sie können virtuelle Festplatten als Shared Storage nur dann verwenden, wenn Sie Clustering-in-a-box einsetzen. Oder anders gesagt, nur wenn sich beide virtuellen Maschinen auf dem gleichen ESX/ESXi-Host befinden.
- RDM in Physical Compatibility Mode: Mithilfe dieses Modus können Sie eine physische LUN direkt mit einer VM oder physischen Maschine verbinden. Allerdings büßen Sie in diesem Fall Funktionalitäten wie zum Beispiel Snapshots ein. Bei diesem Modus ist es ideal, wenn ein Mitglied des Clusters eine physische Maschine ist und die andere eine VM.
- RDM in Virtual Compatibility Mode: Dieser Modus ermöglicht es, eine physische LUN direkt mit einer physischen Maschine oder einer VM zu verbinden. Somit genießen Sie alle Vorteile der virtuellen Festplatten mit VMFS. Dazu gehören auch Snapshots und fortschrittliches Locking. Auf die Festplatte wird via Hypervisor zugegriffen. Am besten eignet sich dieser Modus bei einem Cluster-across-boxes-Szenario, wenn beide virtuellen Maschinen Zugriff auf das Shared Storage brauchen.
Zum Zeitpunkt des Schreibens dieses Beitrags ist der einzige VMware-unterstützte Clustering Service MSCS (Microsoft Clustering Services). Sie erhalten weitere Informationen im VMware Whitepaper „Setup for Failover Clustering and Microsoft Cluster Service“.
VMware Fault Tolerance
VMware Faul Tolerance (FT) ist eine andere Form von VM-Clustering, die von VMware entwickelt wurde. Man adressiert hier Systeme, die extreme Ausfallsicherheit erfordern. Eine der überzeugendsten Funktionen von FT ist, wie einfach sich die Komponente einrichten lässt. Sie müssen für FT eigentlich nur einen Haken setzen. Verglichen mit herkömmlichem Clustering, das spezielle Konfigurationen benötigt und manchmal sogar gesonderte Verkabelung, ist FT einfach aber leistungsstark.
Wie funktioniert Fault Tolerance
Wenn Sie virtuelle Maschinen mit FT absichern, wird eine zweite VM gleichzeitig zur ersten und zu schützenden VM kreiert. FT funktioniert, indem simultan zu beiden virtuellen Maschinen geschrieben wird. Jede Aufgabe wird also doppelt ausgeführt. Klicken Sie auf das Start-Menü der ersten virtuellen Maschine, würde also das Start-Menü der zweiten automatisch geklickt. Das Leistungsmerkmal von FT ist die Möglichkeit, beide virtuelle Maschinen synchron zu halten.
Sollte die zu schützende VM aus irgendwelchen Gründen ausfallen, springt die zweite sofort ein und übernimmt Identität sowie die IP-Adresse. Somit laufen die Services ohne Störung weiter. Die neue und nun zu schützende virtuelle Maschine erzeugt wiederum selbständig eine zweite VM auf einem anderen Host und die Synchronisierung geht weiter.
Sehen wir uns der Übersichtlichkeit wegen ein Beispiel an. Wollen Sie einen Exchange-Server schützen, könnten Sie FT aktivieren. Sollte der für die entsprechende VM zuständige ESX/ESXi-Server aus irgendwelchen Gründen ausfallen, springt die sekundäre VM sofort ein und bietet die relevanten Services ohne Unterbrechung weiterhin an.
In der nachfolgenden Tabelle finden Sie die verschiedenen High-Availability- und Clustering-Technologien, die Sie via vSphere nutzen können. Weiterhin gehen wir auf die entsprechenden Einschränkungen ein.
Support-Matrix hinsichtlich vSphere HA und Clustering
| HA | FT | MSCS | |
| Verfügbarkeits-Typ | High Availability | Fault Tolerance | Fault Tolerance |
| Downtime | Etwas | Keine | Etwas |
| Unterstützte Betriebssysteme | Alle unterstützten Betriebssysteme | Alle unterstützten Betriebssysteme | Nur von Microsoft unterstützte Betriebssysteme |
| Unterstützt | Alles unterstützt | Alles ESX-unterstützte | Hardware |
| Hardware | ESX-Hardware | Hardware mit CPUs, die FT unterstützen | Von Microsoft unterstützt |
| Anwendungsfälle | HA für alle virtuellen Maschinen | FT für wichtige virtuelle Maschinen | FT für wichtige Applikationen |
Voraussetzungen für Fault Tolerance
Fault Tolerance unterscheidet sich nicht von anderen Enterprise-Funktionen. Es müssen bestimmte Voraussetzungen herrschen, damit die Technologie angemessen und effizient funktioniert. Diese Voraussetzungen finden Sie in der nachfolgenden Liste, die in verschiedene Kategorien gegliedert sind, die wiederum gewisse Minimal-Ansprüche stellen:
Voraussetzungen hinsichtlich des Hosts:
- FT-kompatible CPU. Erfahren Sie mehr in diesem VMware-KB-Artikel.
- Hardware-Virtualisierung muss im BIOS aktiviert sein.
- Die CPU-Taktgeschwindigkeiten des Hosts müssen sich in einem Rahmen von 400 MHz befinden.
Voraussetzungen hinsichtlich der virtuellen Maschinen:
- Virtuelle Maschinen müssen sich auf unterstütztem Shared Storage befinden. Das kann FC, iSCSI oder NFS sein.
- Virtuelle Maschinen müssen auf einem unterstützten Betriebssystem laufen.
- Virtuelle Maschinen müssen entweder als VMDK oder virtual RDM gespeichert sein.
- Virtuelle Maschinen dürfen keine durch Thin Provisioning realisierten VMDKs enthalten und müssen eine Eagerzeroedthick-Virtuelle-Festplatte haben.
- Virtuelle Maschinen dürfen nicht mehr als eine vCPU konfiguriert haben.
Voraussetzungen für den Cluster:
- Alle ESX/ESXi-Hosts müssen die gleiche Version haben und das gleiche Patch-Niveau.
- Alle ESX/ESXi-Hosts müssen Zugriff auf die VM-Datastores und -Netzwerke haben.
- VMware HA muss auf dem Cluster aktiviert sein.
- Auf jedem Host muss vMotion und FT Logging NIC konfiguriert sein.
- Überprüfung des Host-Zertifikats muss ebenfalls aktiv sein.
Es ist sehr empfehlenswert, dass Sie nicht nur die Prozessor-Kompatibilität hinsichtlich FT prüfen. Sie sollten auch die Marke und das Modell des Servers hinsichtlich FT-Kompatibilität in Augenschein nehmen. Dafür verwenden Sie am besten die VMware Hardware Compatibility List (HCL).
FT ist sicherlich eine tolle Clustering-Lösung. Es sollte aber auch darauf hingewiesen sein, dass es einige Einschränkungen gibt. Zum Beispiel können Sie bei FT keine Snapshots benutzen und Storage vMotion funktioniert ebenfalls nicht. In der Tat sieht es so aus, dass diese virtuellen Maschinen automatisch als DRS-Disabled markiert sind und somit auch nicht an dynamischem Ressourcen-Load-Balancing teilnehmen.
Wie man FT aktiviert
Es ist nicht schwer, FT zu aktivieren. Allerdings müssen Sie diverse Einstellungen konfigurieren. Die nachfolgenden Einstellungen müssen angemessen konfiguriert sein, damit FT funktioniert:
- Enable Host Certificate Checking: Um diese Einstellung zu aktivieren, melden Sie sich am vCenter-Server an und klicken auf Administration aus dem File-Menü. Im Anschluss klicken Sie auf vCenter Server Settings. Auf der linken Seite klicken Sie auf SSL Settings und setzen den Haken bei vCenter Requires Verified Host SSL Certificate.
- Configure Host Networking: Die Netzwerk-Konfiguration für FT ist einfach und Sie gehen hier mit den gleichen Schritten und Prozeduren wie bei vMotion vor. Anstelle des vMotion-Hakens setzen Sie diesen bei Fault Tolerance Logging, wie Sie in Abbildung 5 sehen.
- Turning FT On and Off: Sobald Sie die oben beschriebenen Einstellungen erledigt haben, können Sie FT für virtuelle Maschinen nun aktivieren oder deaktivieren. Die Prozedur ist einfach. Finden Sie die virtuelle Maschine, die Sie schützen möchten und tätigen Sie einen Rechtsklick. Nun wählen Sie Fault Tolerance → Turn On Fault Tolerance.
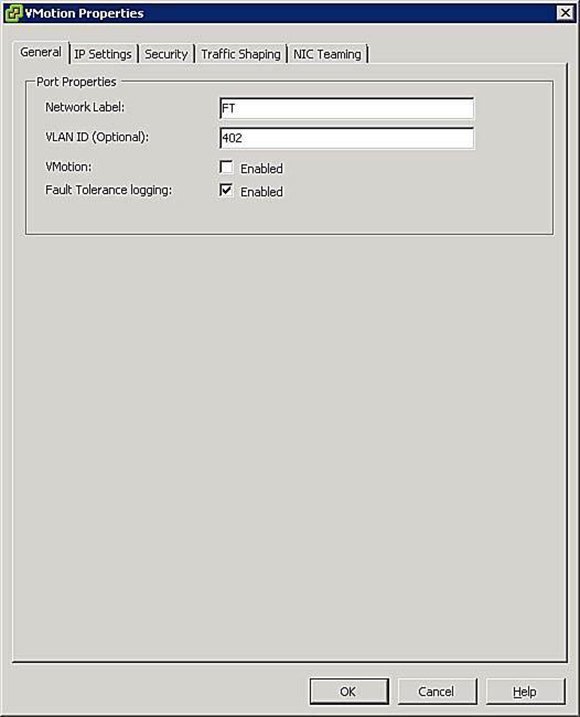
Abbildung 5: FT Port Group Settings
FT ist eine Clustering-Technologie der ersten Generation. Dafür funktioniert sie ausgesprochen gut und vereinfacht sehr komplizierte herkömmliche Methoden, um einen Cluster zu erschaffen, zu konfigurieren und zu verwalten. FT ist eine beeindruckende Technologie in Bezug auf die Uptime und für nahtloses Failover.
Über den Autor:
Elias Khnaseris ist ein Autor, Redner und IT-Consultant. Seite Spezialgebiete sind Technologien von Microsoft, Citrix und VMware. Er hat mehr als 12 Jahre Erfahrung in den Bereichen Administration, Engineering und Architekturen. Weiterhin hat er viele Bücher und Artikel zu diesen Themen geschrieben.
Folgen Sie SearchStorage.de auch auf Facebook, Twitter und Google+!






