
Getty Images/iStockphoto
Infrastrukturaspekte für Kubernetes-Cluster-Netzwerke
Kubernetes-Cluster-Networking benötigt eine optimale Netzwerkinfrastruktur. Sie ermöglicht eine nahtlose Kommunikation und Ressourcenorchestrierung für containerisierte Workloads.

Für Netzwerktechniker mag der Umstieg auf Kubernetes im Hinblick auf die Konfiguration von Netzwerkgeräten abschreckend wirken, aber die Networking-Konzepte ähneln sich.
Immer mehr Unternehmen setzen auf Kubernetes, um komplexe Anwendungsfälle in verschiedenen Bereichen wie Hybrid-Cloud- und Multi-Cloud-Umgebungen zu managen. Ein gut konzipiertes Netzwerk ist für eine nahtlose Kommunikation innerhalb des Clusters unerlässlich. In diesem Artikel behandeln wir die folgenden Aspekte von Kubernetes-Cluster-Networking:
- Compute-Anforderungen für ein Kubernetes-Cluster.
- Zentrale Networking-Komponenten, wie die CNI-Spezifikation (Container Networking Interface).
- Netzwerkrichtlinien.
- Service-Networking-Modelle.
- Rollen und Berechtigungen für Netzwerktechniker.
- Observability und Skalierbarkeit.
Der folgende Fehlercode unterstreicht die Bedeutung eines gut durchdachten Kubernetes-Clusternetzwerks. Er zeigt einen Codeausschnitt, der erzeugt wird, wenn man versucht, einen Container in einem Cluster ohne ordnungsgemäß konfiguriertes Netzwerk auszuführen.
Warning NetworkNotReady 2m17s (x18 over 2m51s) kubelet network is not ready: container runtime network not ready: NetworkReady=false reason:NetworkPluginNotReady message:Network plugin returns error: cni plugin not initialized
Als Nächstes werden wir die Komponenten und Prinzipien analysieren, die die Grundlage für diese Infrastruktur bilden.
Compute-Anforderungen für ein Kubernetes-Cluster
Das Computing umfasst die Knoten (auch Nodes genannt) in einem Kubernetes-Cluster. Der erste Schritt bei der Arbeit mit Kubernetes-Cluster-Networking besteht darin, die Infrastrukturanforderungen zu ermitteln, zum Beispiel folgendermaßen:
- Bestimmen Sie die Anzahl der Knoten, virtuell oder physisch, aus denen das Cluster besteht. Diese Knoten ordnen den Pods Ressourcen zu.
- Entscheiden Sie, ob die Nodes privat bereitgestellt werden sollen und ob sie Network Address Translation (NAT) nutzen werden.
- Legen Sie fest, ob das Cluster ein IPv4-IPv6-Adresscluster auf Dual-Stack-Basis sein wird.
- Schätzen Sie den aktuellen und zukünftigen Bedarf an IP-Adressen ab. Wenn Teams mit Einschränkungen bei der Nutzung vorhandener IP-Adressen rechnen müssen, haben sie die Möglichkeit, ihre eigenen IP-Adressen mitzubringen.
- Legen Sie Firewall-Regeln dafür fest, welche Art von Traffic auf die Knoten zugreifen darf.
- Bestätigen Sie die Netzwerkkarte für die Knoten. Wählen Sie außerdem die Netzwerkgeräte nach der Geschwindigkeit des Ports aus, etwa zehn MBit/s und 100 MBit/s. Bei AWS unterstützen einige Knoten beispielsweise eine höhere Bandbreite auf AWS-Schnittstellen als andere.
Netzwerk-Plug-ins und CNI
Ein Netzwerk-Plug-in konfiguriert das Networking auf jeder Containerschnittstelle, damit diese untereinander kommunizieren können. Die CNI-Spezifikation definiert, wie Netzwerk-Plug-ins mit dem Container kommunizieren. CNI arbeitet auf Layer 3 und 4 des OSI-Modells. Das Interface kümmert sich ebenfalls um die Zuweisung von IP-Adressen an Container und Pods sowie um Routing-Protokolle wie das Border Gateway Protocol (BGP) für die Kommunikation mit externer Infrastruktur und die Durchsetzung von Netzwerkrichtlinien. Häufig verwendete CNI-Plug-ins sind Calico und Cilium. Die IT-Teams sollten ein CNI wählen, das ihren Anforderungen entspricht und von einer aktiven Community unterstützt wird.
Netzwerkrichtlinien für Kubernetes-Cluster
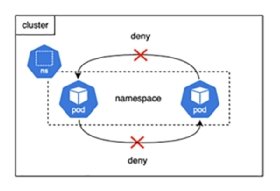
Netzwerkrichtlinien sind wie ACL-Konfigurationen (Access Control Lists) bei Netzwerkgeräten. Sie definieren Regeln für die Kommunikation zwischen Pods und Kubernetes-Namespaces. Ein Namespace ist wie ein virtuelles LAN (VLAN) auf einem Switch. So unterteilt ein VLAN ein Netzwerk in mehrere logische Segmente, während ein Namespace ein Cluster in mehrere virtuelle Cluster unterteilt. Die IT-Teams können verschiedene Netzwerkrichtlinien einrichten, um den Traffic zu steuern, etwa indem sie Pings zwischen Pods innerhalb eines Kubernetes-Namespaces einschränken, wie in Abbildung 1 dargestellt.
Hier ist das YAML-Skript, das die Deny-Netzwerkrichtlinie beschreibt:
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
name: deny
namespace: default
spec:
podSelector: {}
policyTypes:
- Egress
- Ingress
Service-Networking-Modelle
Kubernetes unterstützt die folgenden Service-Networking-Modelle:
- ClusterIP
- LoadBalancer
- ExternalName, auch als DNS-Alias bezeichnet
- NodePort beziehungsweise Port-Forwarding
Diese Services kommunizieren mit anderen Services, Pods und externen Ressourcen basierend auf bestimmten Verhaltensweisen.
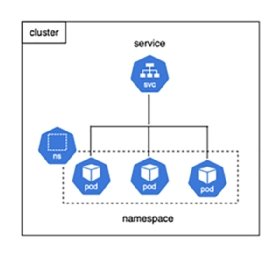
ClusterIP
Dies ist das Standardservicemodell für Kubernetes. Es stellt dem Dienst eine interne IP-Adresse zur Verfügung, so dass Pods innerhalb desselben Clusters über diese IP-Adresse kommunizieren können.
LoadBalancer
Dieses Modell ähnelt den Optionen für Netzwerk-Load-Balancer, die von Anbietern wie AWS und F5 bereitgestellt werden. Es verteilt den Netzwerk-Traffic auf die Ressourcen und ist für die externe Kommunikation nützlich. Wenn IT-Teams diese Ressource konfigurieren und erstellen, fordert Kubernetes einen Load Balancer vom bevorzugten Anbieter an.
ExternalName
Dieses Modell erstellt einen DNS-Aliasnamen für Cloud-Dienste, die außerhalb des Clusters bereitgestellt werden, wie Datenbanken, APIs und Messaging-Services. Pods und andere Dienste innerhalb des Clusters können dann diese Aliasnamen verwenden.
NodePort
Dieses Modell ist vergleichbar mit dem Port-Forwarding bei Netzwerkgeräten. Dort bezieht sich das Port-Forwarding auf einen Port und eine IP-Adresse. Auf ähnliche Weise kann in Kubernetes ein Node-Portservice eine Anwendung zur Verfügung stellen und sie mit der öffentlichen IP-Adresse des Knotens und einem benutzerdefinierten Port ansprechen.
Beachten Sie, dass Kubernetes eine andere Konfiguration für das Port-Forwarding vorsieht. Sie funktioniert zwar ähnlich wie ein Node-Port, aber der Effekt ist im Gegensatz zu einem Node-Port nicht dauerhaft.
Implementieren einer Continuous-Integration- und -Deployment-Pipeline
Eine Continuous-Integration- und -Deployment-Pipeline ist für die folgenden Aspekte von Kubernetes-Cluster-Networking erforderlich:
- Benutzerdefiniertes Image erstellen und testen, bevor es in die Registry übertragen wird.
- Geänderte Manifest-Datei, die Netzwerkressourcen enthält, auf das Cluster anwenden.
- Die Infrastructure-as-Code-Konfiguration für das Cluster zur automatischen Bereitstellung verwalten.
Für diesen Schritt stehen je nach Infrastruktur eines Unternehmens verschiedene Anbieter zur Verfügung:
Rollen und Berechtigungen
Der nächste Schritt besteht darin, Rollen für Netzwerktechniker einzurichten, die auf das Cluster zugreifen. Ein Techniker, der auf ein Cluster zugreifen muss, könnte beispielsweise eine Rolle für den Zugriff auf das gesamte Cluster oder einen bestimmten Namespace innerhalb des Clusters haben.
Zu den Rollen gehören Berechtigungen wie get, list und watch, die den Zugriff auf die folgenden Informationen erlauben oder verweigern:
- Cluster: Informationen über einen Knoten oder einen Namespace.
- Ressourcen: Informationen über Pods oder Services, wie einen Load Balancer oder einen externen Namen für DNS.
- Netzwerkrichtlinien: Informationen über Richtlinien, die mit einem Pod und Namespace verbunden sind.
- Namespace: Der Techniker hat nur innerhalb eines Namespaces Berechtigungen beziehungsweise keine Berechtigungen.
Die Kubernetes-Dokumentation enthält weitere Informationen über API-Berechtigungsoptionen.
Kostenüberlegungen
In einer Public-Cloud-Umgebung müssen die Egress-Kosten für den Netzwerk-Traffic, der das Netzwerk verlässt, berücksichtigt werden.
Beurteilen Sie die folgenden Faktoren auf Grundlage der Egress-Kosten für Pod-Schnittstellen:
- Kommunikation innerhalb des Clusters: Beschränken Sie die Kommunikation auf dieselbe Cloud-Verfügbarkeitszone oder Data-Center-Zone, es sei denn, es ist etwas anderes erforderlich.
- Kommunikation mit dem Internet: Dies umfasst drei Komponenten. Zunächst sind die Egress-Kosten für die Container-Registry zu berücksichtigen. Anstatt eine öffentliche Registry zu verwenden, ist es möglich, die erforderlichen Abhängigkeiten herunterzuladen, einmal ein Image zu erstellen und es dann in der Registry des Public-Cloud-Anbieters zu speichern. Wenn ein Techniker das nächste Mal ein neues Image abrufen muss, um einen Pod zu starten, bleibt der Egress Traffic innerhalb der Region. Berücksichtigen Sie zweitens die Egress-Kosten zu einem zweiten Public-Cloud-Anbieter. Zu guter Letzt ist die Kommunikation mit dem On-Premises-Rechenzentrum zu betrachten.
Skalierbarkeit und optimale Netzwerkinfrastruktur
Beim Design eines Netzwerk-Clusters ist es wichtig, Hochverfügbarkeit, Disaster Recovery und Skalierbarkeit zu berücksichtigen. Im Folgenden finden Sie einige wichtige Überlegungen.
Compute
Teams, die ein Cluster mit einem Worker Node betreiben und es selbst verwalten, sollten Backup-Knoten für die Control Plane und den Worker Node einrichten. Ein Autoscaler kann dabei helfen. Außerdem sollten Sie die Knoten aus Sicherheitsgründen regelmäßig patchen und nach Möglichkeit ein Managed Cluster verwenden.
Netzwerksicherheit
Legen Sie für Netzwerktechniker und Netzwerkrichtlinien den Least Privileged Access (Prinzip der minimalen Rechtevergabe) fest, und verschlüsseln Sie den gesamten Traffic in Transit im Netzwerk per Transport Layer Security (TLS). Beschränken Sie die Entschlüsselung auf Load Balancer oder Ingress anstelle von Pods. Setzen Sie in Multi-Cluster-Umgebungen eine zentralisierte Firewall ein.
IP-Routing
Auch das IP-Routing kann einige Herausforderungen mit sich bringen. Ein häufiges Problem ist sich überschneidendes Classless Inter-Domain Routing (CIDR). Dies stellt eine große Herausforderung dar, wenn man Multi-Cloud-Tools nutzt oder wenn ein Unternehmen ein anderes übernimmt. Eine Möglichkeit, dieses Problem zu lösen, besteht darin, ein Tool zu verwenden, das Open-Source- und dynamische NAT-Gateways unterstützt.
Verteilte Load Balancer sind eine weitere Herausforderung. In einer Multi-Cluster-Umgebung managen verschiedene Teams unterschiedliche Pods, so dass es möglicherweise einen spezifischen Load Balancer in ihrer virtuellen Private Cloud gibt. Dadurch steigen die Kosten. Stattdessen können die IT-Teams ein Networking Tool nutzen, das einen zentralisierten Load Balancer für eine Multiclusterumgebung unterstützt.
Namenskonventionen
Beim Aufbau des Clusters empfiehlt es sich, für die Bezeichnungen der Netzwerkressourcen einprägsame Namenskonventionen zu verwenden. Bei einer Namenskonvention für ein Schlüssel-Wert-Paar bilden die Bezeichnungen den Schlüssel, während der Wert durch eine Zeichenkette dargestellt wird. Sie sollten also beispielsweise statt availability-zone:us-west-2a besser az:us-west-2a verwenden.
Gemeinsame Ressourcennutzung
Die meisten Public-Cloud-Anbieter stellen Dienste zur gemeinsamen Nutzung von Ressourcen bereit. So können Netzwerkteams etwa ein Subnetz unter verschiedenen Konten teilen, damit sie nicht zu viele IP-Adressen verwenden. Außerdem lässt sich damit eine sichere Kommunikation zwischen den Konten realisieren.
Single Cloud mit mehreren Clustern
Anstatt herkömmliche Networking Tools zu verwenden, um die Kommunikation zwischen Diensten zu verwalten (wie die manuelle Konfiguration von VPNs, Firewalls und Load Balancern), sollten Sie ein Service-Mesh für den Ost-West-Traffic einsetzen. Bei einem Service-Mesh handelt es sich um ein intelligentes Overlay-Netzwerk, das eine sichere Konnektivität zwischen Microservices ermöglicht. Beispiele hierfür sind Cilium Mesh und HashiCorp Consul.
Hybrid und Multi-Cloud mit mehreren Clustern
Wenn ein Unternehmen über Cluster verfügt, die sich über einen Cloud-Anbieter erstrecken, empfiehlt es sich, die dedizierte Netzwerkverbindung eines Cloud Providers zu wählen. Die Verbindung des Cloud Providers bietet eine höhere Bandbreite von bis zu 100 GBit/s im Gegensatz zu einem Site-to-Site-VPN, das normalerweise weniger als zehn GBit/s liefert. Als Optionen bieten sich Aviatrix, Equinix und Google Cross-Cloud Interconnect an. Treffen Sie Ihre Wahl entsprechend den Anforderungen Ihres Unternehmens.
Observability und Troubleshooting
Die Observability ist in einem Kubernetes-Cluster ebenfalls entscheidend. Sie gibt Aufschluss über das Cluster und die Pods, zum Beispiel über Latenz, Paketverlust und Protokoll-Header.
Um diese Funktion zu nutzen, müssen Techniker ihr bevorzugtes Anbieter-Tool installieren. Häufig verwendete Tools sind Prometheus mit Grafana und Cilium Hubble.
Erprobung in einer privaten Testumgebung
Der nächste Schritt besteht darin, diese Konzepte in einer privaten Testumgebung auszuprobieren. Für ein schnelles, praxisnahes Projekt können Sie ein Netzwerk-Cluster bei Ihrem favorisierten Public-Cloud-Anbieter mit Kubeadm oder einem Managed-Cluster-Dienst wie Amazon Elastic Kubernetes Service beziehungsweise Azure Kubernetes Service einrichten. Probieren Sie dann einige Networking-Aufgaben aus der Kubernetes-Dokumentation aus.







