
Hyperkonvergenz vereinfacht die Verwaltung von Netzwerken
Hyperkonvergenz treibt die Entwicklung von Netzwerken voran. Entscheidend für optimale Ergebnisse sind die Flexibilität und Leistung der Management-Software.
Hyperkonvergenz stellt den neuesten Schritt in der Evolution der Architektur von Datensystemen dar. Sie kombiniert die Verwaltung von virtuellen Servern, Storage und Netzwerk und bietet den Betreibern so eine zentrale Sicht auf einen Pool von Computing-Ressourcen.
Frühere Computersysteme bestanden aus einzelnen Servern, Speicher und Netzwerken. Konvergente Systeme stellten den nächsten Schritt dar. Sie vereinten Rechen- sowie Speicher-Ressourcen und Networking, betrachteten aber jede Komponente immer noch als ein einzelnes Element.
Hyperkonvergente Systeme bauen auf diesen Konzepten auf. Sie vereinfachen die Verwaltung von Netzwerksystemen, da sie alle Komponenten unter einer einzigen, zentralen Konsole bündeln; separate Management-Konsolen für Computing, Storage und Netzwerk sind damit nicht mehr notwendig. Auch Kompatibilitäts-Probleme verschwinden, da das gesamte System typischerweise vom selben Hersteller oder Systemintegrator stammt.
Anbieter von hyperkonvergenten Systemen sind spezialisierte Hersteller wie Nutanix, Pivot3 und Stratoscale sowie die großen Systemanbieter wie Cisco, Dell EMC und Hewlett Packard Enterprise. Die Systeme basieren auf Standardservern und sind oft bereits vorkonfiguriert, damit der Kunde sie schnell installieren und in Betrieb nehmen kann. Bei zunehmenden Rechenanforderungen lassen sich zusätzliche Systeme hinzufügen, so dass ein Cluster von Systemen entsteht. Die Integration der einzelnen Systeme erfolgt über Software, die eine einheitliche Sicht auf die kompletten Ressourcen ermöglicht.
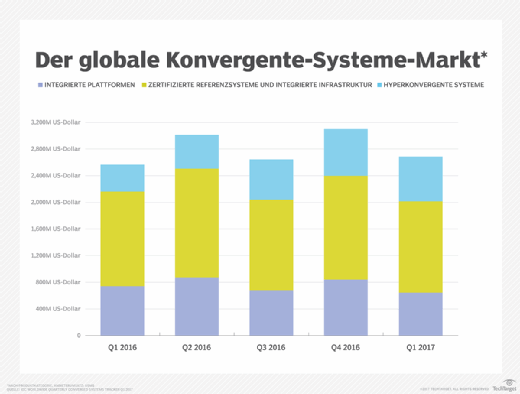
Der weltweite Markt für konvergente Systeme, zu dem auch hyperkonvergente Systeme gehören, wuchs im ersten Quartal 2017 laut IDC im Vergleich zum Vorjahr um 4,6 Prozent auf ein Volumen von mehr als 2,6 Milliarden US-Dollar.
Die Leistung des Netzwerks ist entscheidend
Hyperkonvergente Systeme stellen hohe Anforderungen an das Netzwerk, die über die Anforderungen herkömmlicher Systeme hinausgehen. Damit das Cluster die erforderliche Leistung bringt, muss es über ausreichend Bandbreite verfügen. Daher ist es wichtig, bei der Entwicklung eines Netzwerks das Ausmaß des Datenverkehrs und die QoS-Anforderungen (Quality of Service) zu verstehen, die ein hyperkonvergentes Cluster an das Netzwerk stellt.
Die Latenz ist neben einer ausreichenden Bandbreite ein weiterer zentraler Faktor. Es ist wichtig, Switches mit geringer Latenz auszuwählen und ein flaches Netzwerk aufzubauen, das mit einer minimalen Anzahl von Switches zwischen Anwendungen und Daten arbeitet – im Gegensatz zu anderen Topologien.
Die Leistung von Anwendungen hängt vom schnellen Zugriff auf Daten ab. Die von einer Anwendung benötigten Daten können allerdings im Cluster über mehrere Systeme hinweg verstreut sein. Denn im Gegensatz zu einem herkömmlichen Netzwerk haben hyperkonvergente Cluster kein separates Storage Area Network (SAN).
Festplatten werden innerhalb eines einzelnen Systems direkt angeschlossen. Der Zugriff auf die Daten anderer Systeme im Cluster erfolgt jedoch über dasselbe Ethernet-Netzwerk, das den Datenverkehr zwischen einzelnen Anwendungen und der Management-Software weiterleitet. Das Management-System kann die Leistungsanforderungen erfüllen, indem es virtuelle LANs mit QoS-Einstellungen konfiguriert, die Storage-Daten gegenüber anderen Daten priorisieren. In einigen Fällen erfordert eine ausreichende Leistung jedoch die Konfiguration von dedizierten Ethernet-Verbindungen, die nur für den Speicherverkehr bestimmt sind.
Vielzahl an Funktionen
Viele hyperkonvergente Systeme unterstützen Datenreplikation und Deduplizierung. Mehrere – oft drei Kopien jeder Datenbank – werden innerhalb des Clusters auf verschiedenen Netzwerk-Management-Systemen verwaltet. Verändert eine Anwendung Einträge in einer Datenbank, muss diese Änderung über das Netzwerk verbreitet werden. Dieser Datenverkehr erzeugt eine konstante Belastung des Netzwerks, während die Deduplizierung Datenverkehr hinzufügt, da redundante Daten aus mehreren Kopien der Datenbank entfernt werden.
Das Cluster gleicht Workloads über Systeme hinweg aus, indem es virtuelle Maschinen (VM) von einem stark belasteten System auf ein weniger belastetes System verschiebt. Im Gegensatz zur Datenreplikation stellt dieser Datenverkehr keine konstante Arbeitslast dar. Er tritt nur auf, wenn eine VM bewegt wird. Das Netzwerk muss aber so ausgelegt sein, dass es genügend Kapazität hat, um den laufenden Datenverkehr für andere Anwendungen während des Verschiebens einer VM zu bewältigen.
VM-Klone werden erstellt, damit mehrere Benutzer dieselbe Anwendung gleichzeitig ausführen können. In einigen Fällen kann ein Klon in einer anderen VM auf demselben System laufen; wenn hingegen viele Klone existieren, werden sie oft auf verschiedenen Systemen im gesamten Cluster platziert. Durch diese Aktion wird das Netzwerk stark, aber kurzfristig belastet. Snapshots erfassen den aktuellen Stand einer VM, so dass im Falle eines späteren Ausfalls kein Datenverlust entsteht und die VM in dieser Version wieder eingesetzt werden kann; das Kopieren von Snapshots über das Netzwerk führt zu zusätzlicher Belastung.
Hyperkonvergente Cluster müssen auch dann weiterlaufen, wenn ein Server oder eine Netzwerkverbindung ausfällt. Daher muss das Netzwerk redundante Verbindungen aufweisen. VMs lassen sich grundsätzlich mit Hilfe von Snapshots und replizierten Daten rekonstruieren und weiterhin ausführen – dies ist aber nicht möglich, wenn die einzige Netzwerkverbindung zu einem Teil des Netzwerks unterbrochen ist. Redundanz ist auch erforderlich, wenn ein Switch für ein Upgrade offline genommen wird, oder wenn das Cluster wächst und ein Switch aktualisiert werden muss, um weitere Systeme zu integrieren.
Software für Netzwerk-Management muss flexibel sein
Die Netzwerkkomponente der Management-Software muss mit den VM-Hypervisoren und dem Storage Management effizient verbunden sein und die Datenpfade zuweisen sowie konfigurieren, wenn VMs erstellt, beendet und verschoben werden. Manchmal ist es notwendig, das gesamte Netzwerk zu verändern, um eine neue Anwendung zu unterstützen und gleichzeitig die erforderlichen Ressourcen für andere Anwendungen bereitzustellen. Alle diese Aktionen müssen ohne Eingriff des Benutzers erfolgen, da es nicht möglich wäre, das Cluster über manuelle Befehle effizient zu betreiben.
Zusätzlich muss die Management-Software System- oder Verbindungsausfälle wegstecken, um den Betrieb des Clusters aufrechtzuerhalten. Zudem muss sie genaue und zeitnahe Berichte über Ausfälle von Hardware und Nachrichten über zeitweilige Ausfälle liefern, die zukünftige Probleme signalisieren können. Berichte über Prozessoren, Speicher und Netzwerkverbindungen zeigen, inwieweit Ressourcen ausgelastet sind. Trendberichte ermöglichen es, Upgrades zu planen, bevor die Leistung im Cluster nachlässt.
Die Vorteile von hyperkonvergenten Systemen sind mittlerweile weithin anerkannt: reduzierte Verwaltungskosten, effizienter Einsatz von Ressourcen und reibungslose Upgrades. Wenn der Markt für hyperkonvergente Systeme weiter wächst, werden voraussichtlich mehr Netzwerke auf die neue Architektur umgestellt, und kleine Cluster werden zu großen Clustern. Je komplexer Netzwerke werden und je mehr Anwendungen mit unterschiedlichen Anforderungen hinzukommen, desto deutlicher werden die Vorteile der Hyperkonvergenz offensichtlich.
Folgen Sie SearchNetworking.de auch auf Twitter, Google+, Xing und Facebook!






