
deagreez - stock.adobe.com
Fünf Machine Learning Skills, die in der Cloud nötig sind
Machine Learning (ML) und künstliche Intelligenz (KI) werden immer wichtiger für IT-Services und Anwendungen. IT-Teams müssen ihre Fähigkeiten ausbauen, besonders in der Cloud.

Machine Learning (ML) und künstliche Intelligenz (KI) nehmen eine immer wichtigere Rolle für IT-Services und Anwendungen ein. IT-Teams müssen ihre Fähigkeiten zum maschinellen Lernen ausbauen, wenn sie mithalten möchten.
Cloud-Computing-Dienste unterstützen eine Reihe von Funktionen, die zum Erstellen und Bereitstellen von künstlicher Intelligenz und maschinellem Lernen erforderlich sind. Die Verwaltung von Services mit künstlicher Intelligenz ist dabei gar nicht so verschieden von der anderer Anwendungen in der Cloud, mit denen IT-Experten vertraut sind.
Leider bedeutet das nicht unbedingt, dass jeder, der eine Anwendung bereitstellen kann, auch ein Modell für maschinelles Lernen erfolgreich einrichten kann. Gemeinsamkeiten dienen als Anknüpfungspunkte beim Erlernen neuer Techniken, doch es gibt signifikante Unterschiede, mit denen IT-Teams rechnen müssen. Neben dem technologischen Know-how müssen sie auch die derzeit verfügbaren Cloud Tools verstehen, um Projekte für künstliche Intelligenz (KI) und maschinelles Lernen umzusetzen.
In diesem Artikel stellen wir fünf ML-Kenntnisse vor, die IT-Profis benötigen, um KI erfolgreich in der Cloud zu verwenden. Außerdem nennen wir Produkte von Amazon, Microsoft und Google, die sie dabei unterstützen. In einem Team wird natürlich nicht eine Person sämtliche Kenntnisse einbringen können – Sie sollten ein Expertenteam zusammenstellen, das zusammen folgendes leisten kann:
1. Data Engineering
IT-Experten müssen Data Engineering verstehen, wenn sie eine KI-Strategie in der Cloud verfolgen möchten. Es umfasst eine breite Palette von Fähigkeiten, wie Data Wrangling und Workflow-Entwicklung sowie Kenntnisse der Softwarearchitektur.
Diese unterschiedlichen Bereiche des IT-Fachwissens können in verschiedene Aufgaben unterteilt werden. So gehört zum Data Wrangling üblicherweise die Identifizierung von Datenquellen, die Datenextraktion, die Bewertung der Datenqualität, die Datenintegration und die Pipeline-Entwicklung, um KI-Ausgaben in einer Produktionsumgebung auszuführen.
Dateningenieure sollten mit relationalen Datenbanken, NoSQL-Datenbanken und Objektspeichersystemen vertraut sein. Python ist eine beliebte Programmiersprache, die mit Stapel- und Stream-Verarbeitungsplattformen wie Apache Beam und verteilten Computerplattformen wie Apache Spark verwendet werden kann.
Selbst wenn Sie kein erfahrener Python-Programmierer sind, können Sie mit moderaten Kenntnissen der Programmiersprache auf eine breite Palette von Open-Source-Tools für Data Engineering und maschinelles Lernen zurückgreifen. Data Engineering wird in allen wichtigen Clouds gut unterstützt.
AWS bietet eine umfassende Palette von Diensten für Data Engineering, zum Beispiel AWS Glue, Amazon Managed Streaming for Apache Kafka (MSK) und verschiedene Amazon-Kinesis-Dienste. AWS Glue ist ein Katalogisierungs- sowie ETL-Service (Extract, Transform, Load) mit dem sich Jobs planen lassen. MSK ist ein nützlicher Baustein für Data Engineering Pipelines, während die Kinesis-Services besonders hilfreich bei der Bereitstellung skalierbarer Stream-Verarbeitungs-Pipelines sind.
Google Cloud Platform bietet Google Cloud Dataflow, einen verwalteten Apache-Beam-Dienst, der die Stapel- und Stream-Verarbeitung unterstützt. Für ETL-Prozesse stellt Google Cloud Data Fusion einen Hadoop-basierten Datenintegrationsdienst bereit.
In Microsoft Azure gibt es mehrere verwaltete Daten-Tools, darunter Azure Cosmos DB, Data Catalog und Data Lake Analytics.
2. Erstellen von Modellen
Maschinelles Lernen ist eine etablierte Disziplin, und IT-Experten können Karriere machen, indem sie Algorithmen für maschinelles Lernen studieren und entwickeln. IT-Teams verwenden die von Ingenieuren gelieferten Daten, um Modelle zu erstellen und Software zu programmieren, die Empfehlungen abgibt, Werte vorhersagt und Elemente klassifiziert.
Es ist wichtig, die Grundlagen der Technologien für maschinelles Lernen zu verstehen, auch, wenn ein Großteil der Modellerstellung in der Cloud automatisiert ist. Mitarbeiter, die Modelle entwickeln, müssen sich außerdem mit den übergeordneten Daten- und Geschäftszielen auseinandersetzen.
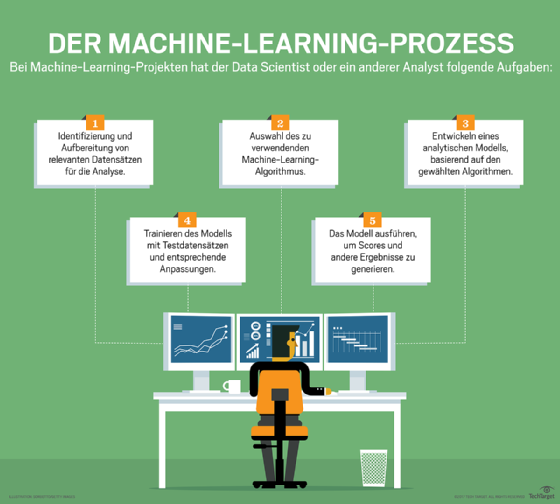
Zu den passenden Produkten auf dem Markt gehören Google Cloud AutoML, eine Suite von Diensten, mit deren Hilfe IT-Teams benutzerdefinierte Modelle mit strukturierten Daten sowie Bildern, Videos und natürlicher Sprache erstellen können, ohne dass ein umfassendes Verständnis des maschinellen Lernens erforderlich ist. Azure bietet ML.NET Model Builder in Visual Studio an, das auch eine Schnittstelle zum Erstellen, Trainieren und Bereitstellen von Modellen enthält. Amazon SageMaker ist ein weiterer verwalteter Dienst zum Erstellen und Bereitstellen von Modellen für maschinelles Lernen in der Cloud.
Diese Tools können Algorithmen auswählen, ermitteln, welche Funktionen oder Attribute in den Daten den größten Erkenntniswert bringen, und Modelle durch einen Prozess namens Hyperparameter-Tuning optimieren.
Solche Dienste ermöglichen eine weitere Verbreitung von Machine Learning und KI-Strategien. So wie Sie kein Maschinenbauingenieur sein müssen, um ein Auto zu fahren, benötigen Sie keinen Abschluss in maschinellem Lernen, um effektive Modelle zu bauen.
3. Fairness- und Bias-Erkennung
Algorithmen treffen Entscheidungen, die sich direkt und signifikant auf Menschen auswirken. Finanzdienstleister verwenden zum Beispiel KI, um Entscheidungen für die Kreditvergabe zu treffen. Da die KI aber mit historischen Daten trainiert wird, die auf den Entscheidungen voreingenommener Menschen basieren, kann es passieren, dass die KI die Vorurteile der Menschen lernt und dann unbeabsichtigt bestimmte Kunden benachteiligt. Das schadet sowohl den Betroffenen als auch dem Finanzinstitut. KI muss den ethischen Ansprüchen eines Unternehmens genügen und sollte dahingegen kontrolliert werden.
Das Erkennen von Verzerrungen in einem Modell kann ein komplexer Vorgang sein, aber wie beim Erstellen von Modellen kann Automatisierung viele der schwierigeren Aufgaben übernehmen. FairML ist ein Open Source Tool, mit dem Entwickler Verzerrungen in ihren Modellen erkennen können. Erkenntnisse aus diesen Prüfungen können auch in das Data Engineering und das Entwickeln der Modelle einfließen, um Probleme von Vornherein zu vermeiden.
Google Cloud ist marktführend im Bereich Fairness-Tools mit Produkten wie dem What-If-Tool, Fairness Indicators und Explainable AI Services.
4. Evaluierung der Modell-Performance
Modelle müssen nicht nur erstellt werden, Teams sollten sie auch laufend prüfen und anpassen. Kriterien für die Bewertung sind beispielsweise Genauigkeit, Fehlerrate und Rücklauf. Regressionsmodelle, beispielsweise solche, die Preise auf dem Immobilienmarkt vorhersagen, lassen sich durch das Messen der durchschnittlichen Fehlerrate bewerten. Interagieren die Modelle mit Daten aus dem echten Leben, kann es sein, dass Teams sie regelmäßig an eine veränderte Situation anpassen müssen.
Auch ohne größere Krisen kann es zu einem Data Drift kommen. Es ist wichtig, Modelle zu bewerten und weiter zu überwachen, solange sie in der Produktion laufen.
Dienste wie Amazon SageMaker, Azure Machine Learning Studio und Google Cloud AutoML enthalten eine Reihe von Tools zur Bewertung der Modellleistung.
5. Branchenwissen
Branchenerfahrung ist keine Fähigkeit, die spezifisch für das maschinelle Lernen ist, doch sie ist ein wichtiger Faktor für das Gelingen der Strategie.
Jede Branche hat ihre Eigenheiten, die besonders dann wichtig sind, wenn Algorithmen die Entscheidungsfindung unterstützen sollen. Modelle für maschinelles Lernen müssen die Daten widerspiegeln, mit denen sie trainiert wurden.
Die Mitarbeiter benötigen also eine gewisse Erfahrung mit den Abläufen in einer Branche, um abschätzen zu können, wo und wie KI sinnvoll eingesetzt werden kann.







