
hanakaz1991 - stock.adobe.com
Einen KI-Server mit Ollama und Open WebUI einrichten
Unternehmen können mit Open-Source-Software und passender Hardware einen KI-Server einrichten, der ChatGPT und anderen Lösungen ähnlich ist. Der Beitrag zeigt die Vorgehensweise.

Mit einem eigenen KI-Server kann man die Vorteile von KI auskosten, ohne Daten zu versenden und für das Training fremder Sprachmodelle (Large Language Model, LLMs) zur Verfügung zu stellen. Dadurch lassen sich personenbezogene Informationen, sensible Daten und Dateien mit KI verarbeiten, die einen erhöhten Datenschutz voraussetzen.
Steht entsprechende Hardware zur Verfügung, lassen sich mit Open-Source-LLMs nahezu alle Möglichkeiten ausnutzen, die auch mit öffentlichen KI-Anwendungen zur Verfügung stehen. Die komplette Verarbeitung erfolgt dabei On-Premises. Die Software steht darüber hinaus kostenlos zur Verfügung. Da es sich um Open Source handelt, kann zudem geprüft werden, ob es Schwachstellen oder Backdoors im Code gibt.
Hard- und Software für eigenen KI-Server
Für die Open-Source-Software entstehen keine Lizenzkosten für den KI-Server. Allerdings sollte die Hardware leistungsstark sein, da die Nutzer ansonsten das System nicht optimal nutzen können und auf öffentliche KI-Dienste ausweichen. Das ist aus Datenschutzgründen nicht ideal, da in vielen Fällen die Daten zum Training der zugrunde liegenden LLM verwendet werden.
Auf Hardwareseite sollte man auf leistungsstarke Server mit genügend Arbeitsspeicher, schnellen Datenträgern und entsprechender Leistung im Netzwerk setzen. CPU und GPU sollten performant und aktuell sein, wobei die KI-Berechnungen durch den Grafikprozessor erfolgt. Dieser stellt daher den größten Kostenfaktor dar.
Zu den bekanntesten und leistungsstärksten GPUs von Nvidia gehören die Modelle der Nvidia A100 und H100 Serien, die in der Ampere-/Hopper-Architektur gebaut sind. Diese GPUs bieten gute Leistung für KI-Training und Inferenz, insbesondere bei großen Sprachmodellen und anderen datenintensiven Aufgaben. Die Nvidia A100, welche mit 80 GB HBM2e-Speicher ausgestattet ist, bietet eine Spitzenleistung von bis zu 312 TeraFLOPS bei gemischter Präzision (FP16/FP32). Diese GPU ist in verschiedenen Konfigurationen erhältlich, unter anderem als PCIe-Karte und als Teil von Nvidia DGX-Systemen. Die Preise für eine Nvidia A100 beginnen im Einzelverkauf bei etwa 10.000 bis 12.000 Euro, können aber in spezialisierteren Systemen deutlich höher ausfallen.
Die neuere Nvidia H100, die auf der Hopper-Architektur basiert, bietet im Vergleich zur A100 signifikante Verbesserungen in der Leistung, insbesondere bei der Arbeit mit Transformer-Modellen und im Bereich des beschleunigten Deep Learnings. Mit über 700 TeraFLOPS Leistung bei gemischter Präzision und einem verbesserten Speicherinterface ist sie das aktuelle Flaggschiff im Nvidia-Portfolio. Die H100 ist in der Regel nur in spezifischen, hochintegrierten Systemen wie dem Nvidia DGX H100 verfügbar, und die Preise können je nach Konfiguration und Systemumgebung bis zu 30.000 Euro oder mehr betragen.
Neben den Highend-GPUs bietet Nvidia auch kostengünstigere Optionen, die sich besonders für kleinere Projekte oder den Einstieg in KI-Anwendungen eignen. Hierzu zählen vor allem die GPUs der Nvidia RTX Serie, wie die RTX 4090 und RTX 4080, welche ursprünglich für Gaming und professionelle Visualisierungen entwickelt wurden, sich aber aufgrund ihrer hohen Rechenleistung und CUDA-Kompatibilität auch für KI-Entwicklungen eignen.
Nvidia RTX 4090 bietet mit 24 GB GDDR6X-Speicher und bis zu 82,6 TeraFLOPS FP32-Leistung eine passende Plattform für KI-Workloads, insbesondere für inferenzbasierte Anwendungen oder das Training kleinerer Modelle. Der Preis für die RTX 4090 liegt aktuell bei etwa 1.800 bis 2.000 Euro, je nach Anbieter und Verfügbarkeit. Eine etwas günstigere Option stellt die Nvidia RTX 4080 dar, die mit 16 GB GDDR6X-Speicher und einer FP32-Leistung von bis zu 49 TeraFLOPS ebenfalls für viele KI-Anwendungen ausreichend ist. Diese GPU kostet derzeit rund 1.300 bis 1.500 Euro.
Für noch preisbewusstere Anwender gibt es die Nvidia RTX 3060 und RTX 3070/3090, die ebenfalls für KI-Entwicklungen genutzt werden können, jedoch mit deutlichen Einschränkungen hinsichtlich der Rechenleistung und des Speichers. Diese GPUs bewegen sich preislich zwischen 400 und 700 Euro.
Apple-Hardware auch geeignet für KI-Server
Für Test- und Entwicklungsumgebungen kann ebenfalls Apple-Hardware mit einem M2, M3 oder M4-Prozessor zum Einsatz kommen. Diese verfügen über KI-Funktionen und können mit kleineren Nvidia-GPUs mithalten. Der M2-Chip führte bereits deutliche Verbesserungen bei der Machine-Learning-Verarbeitung ein, insbesondere durch die Weiterentwicklung der Neural Engine, die in der Lage ist, komplexe KI-Aufgaben schneller und effizienter zu bewältigen.
Der M3-Chip baute auf diesen Fortschritten auf und optimierte die Architektur weiter, wobei der Fokus auf einer erhöhten Integration von KI-Workloads in alltägliche Anwendungen lag. Mit dem M4-Chip sind weitere Leistungssteigerungen zu erwarten.
Software für eigenen KI-Server: Ollama und Open WebUI
Steht die Hardware zur Verfügung, erfolgt die Auswahl und Einrichtung der Software. Kommt Apple-Hardware zur Verfügung, setzt man auf die macOS-Varianten der Software, ansonsten kommt Linux zum Einsatz.
In diesem Beispiel wird Ollama verwendet. Dabei handelt es sich um eine Open-Source-Plattform, die darauf abzielt, die Bereitstellung, Verwaltung und Ausführung von großen Sprachmodellen zu vereinfachen. Ollama bietet Entwicklern und Unternehmen die Möglichkeit, KI-Modelle effizient zu paketieren und bereitzustellen, ähnlich wie es Docker für Containeranwendungen macht. Zu den prominentesten LLMs, die Teil der Ollama-Lösung sind, gehören Llama 3.1, Phi 3, Mistral, und Gemma 2. Diese Modelle, aber auch weitere, lassen sich auf dem eigenen KI-Server einsetzen.
Llama 3.1 ist ein fortschrittliches Modell von Meta, das für komplexe Aufgaben optimiert wurde, einschließlich Tool-Calling-Funktionen, die es dem Modell erlauben, externe Tools zu integrieren und Aufgaben wie API-Abfragen oder das Durchführen von Webanfragen zu erledigen. Phi 3 und Mistral sind Modelle, die für verschiedene Anwendungen optimiert wurden, von Codegenerierung bis hin zu mathematischen Berechnungen und logischem Denken.
Gemma 2 ist ein weiteres Modell, das in unterschiedlichen Größen verfügbar ist und sich durch seine Vielseitigkeit in verschiedenen Anwendungen auszeichnet. Diese Sprachmodelle machen Ollama zu einer vielseitigen Plattform für die Entwicklung und den Einsatz von KI-Anwendungen in verschiedenen Bereichen. Es ist problemlos möglich, mehrere LLMs parallel zu nutzen.
Ollama installieren
Als Basis-Betriebssystem für Ollama kann zum Beispiel auf Ubuntu 24.04 LTS gesetzt werden, es sind aber auch andere Distributionen möglich.
Beim Einsatz von Apple-Hardware erfolgt die Installation von Ollama auf macOS. Die Installation erfordert Root-Rechte. Das heißt, die Befehle müssen mit sudo ergänzt oder gleich in einer Root-Shell ausgeführt werden.
Für die Installation von Ollama stellen die Entwickler ein Skript zur Verfügung, das sich direkt von der Seite aus starten lässt. Für die Einrichtung braucht der Server in diesem Fall Internetverbindung:
curl -fsSL https://ollama.com/install.sh | shHier ist es wichtig, dass der Server auch die verbaute GPU erkennt und deren Treiber installiert. Ansonsten verwendet Ollama die CPU, was außer in Testumgebungen nicht praktikabel ist. Sobald Ollama zur Verfügung steht, können LLMs integriert werden. Ein Beispiel ist:
ollama pull llama3Hier lädt Ollama die aktuelle Version der Llama 3.x- LLM auf den Server. Wenn der Download erfolgreich war, lässt sich die LLM im Terminal starten:
ollama run llama3Damit kann man die LLM bereits im Terminal testen. Mit /bye wird die Shell von Ollama wieder verlassen. Über ollama pull <LLM> lassen sich jederzeit weitere LLMs herunterladen und in Ollama integrieren. In der Weboberfläche können Nutzer danach die LLM auswählen, die sie verwenden wollen. Admins können in der Weboberfläche außerdem eine Standard-LLM auswählen.
Open WebUI installieren
Um Ollama Anwendern zur Verfügung zu stellen, kann entweder eine API zum Einsatz kommen, die Entwickler in eigene Anwendungen integrieren, oder es kommt die Open WebUI-Weboberfläche zum Einsatz:
sudo apt-get install ca-certificates curl
sudo install -m 0755 -d /etc/apt/keyrings
sudo curl -fsSL https://download.docker.com/linux/ubuntu/gpg -o /etc/apt/keyrings/docker.asc
sudo chmod a+r /etc/apt/keyrings/docker.asc
echo \
"deb [arch=$(dpkg --print-architecture) signed-by=/etc/apt/keyrings/docker.asc] https://download.docker.com/linux/ubuntu \
$(. /etc/os-release && echo "$VERSION_CODENAME") stable" | \
sudo tee /etc/apt/sources.list.d/docker.list > /dev/null
sudo apt-get update
sudo apt-get install docker-ce docker-ce-cli containerd.io docker-buildx-plugin docker-compose-plugin
docker run -d --network=host -v open-webui:/app/backend/data -e OLLAMA_BASE_URL=http://127.0.0.1:11434 --name open-webui --restart always ghcr.io/open-webui/open-webui:mainDer Zugriff auf die Weboberfläche erfolgt über http://<IP-Adresse>:8080.
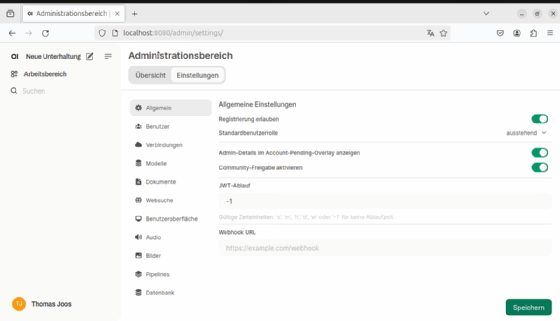
Benutzer können ihr Profil selbst bearbeiten und Administratoren können im Administrationsbereich (siehe Abbildung 2) Einstellungen vornehmen, Benutzer freischalten, Standardmodelle festlegen und Benutzer anlegen. Es ist auch möglich, mehrere Benutzer auf einmal über eine CSV-Datei anzulegen und die freie Registrierung zu blockieren.





