bluebay2014 - stock.adobe.com
Anleitung für Einsteiger: so funktioniert Azure Data Factory
Azure Data Factory ist ein Service zum Verteilen und Analysieren von Datenströmen. In dieser Anleitung erläutern wir die Funktionen des Tools und erklären, wie Sie damit arbeiten.

Azure Data Factory ist ein Service für Daten-Engineering, die Aufnahme von Daten in Data Warehouses, die Integration von Betriebsdaten, Analysen und vieles mehr. In diesem Tutorial erkunden wir die Funktionen von Azure Data Factory und erklären wie Sie damit arbeiten.
Um Data-Factory-Instanzen zu erstellen, muss Ihr Microsoft-Azure-Benutzerkonto über eine Administrator- oder Contributor-Rolle verfügen.
Gehen Sie wie folgt vor, um zu beginnen:
- Wenn Sie noch kein Azure-Konto haben, erstellen Sie ein kostenloses Konto.
- Erstellen Sie ein Azure-Speicherkonto; Sie werden es später in dieser Anleitung verwenden.
- Erstellen Sie einen neuen Azure-Blob-Container, und laden Sie eine Textdatei hoch.
Was ist Azure Data Factory?
Azure Data Factory ist eine vollständig verwaltete und serverlose Datenintegrationsplattform in der Cloud. Sie können es nutzen, um datengesteuerte Workflows für die Umwandlung, Orchestrierung und Automatisierung der Bewegung von Daten zwischen unterstützten Datenspeichern zu erstellen.
Die Plattform eignet sich für den Aufbau von skalierbaren und nützlichen Datenpipelines. Diese Pipelines nehmen Daten aus verschiedenen Quellen auf, verarbeiten sie, transformieren sie und laden sie in Ihre Datenspeicher und -lager für nachträgliche Analysen und Berichte. Sie können den Fortschritt der Datenmigration verfolgen, ihre Leistung in Echtzeit überwachen und Benachrichtigungen erhalten, wenn etwas schief läuft.
Die Vorteile von Azure Data Factory
Azure Data Factory bietet mehrere Vorteile, darunter die folgenden:
- Geringere Kosten. Sparen Sie Infrastrukturkosten, indem Sie die Cloud anstelle von Ressourcen On-Premises nutzen.
- Erhöhte Produktivität. Mit der Drag-and-Drop-Schnittstelle können Sie Datenpipelines erstellen und planen, ohne komplexen Code schreiben zu müssen. Dies verkürzt die Entwicklungszeit und erhöht die Produktivität.
- Flexibel. Azure Data Factory bietet eine flexible Plattform, die Sie mit verschiedenen Datenquellen sowohl innerhalb als auch außerhalb von Azure verbinden.
- Verbesserte Skalierbarkeit. Azure Data Factory lässt sich nach Bedarf skalieren, so dass Sie nur für die verbrauchten Ressourcen zahlen.
- Bessere Sicherheit. Azure Active Directory übernimmt die Authentifizierung und Autorisierung, wodurch Ihre Daten gesichert sind.
Wie funktioniert Azure Data Factory?
Azure Data Factory funktioniert in der Regel nach den folgenden Schritten
- Verbinden und Sammeln. Azure Data Factory verbindet sich mit allen gewünschten Daten- und Verarbeitungsquellen, einschließlich SaaS, File-Sharing und anderen Internetdiensten. Da die Daten in Zeitabschnitte unterteilt sind, können Sie entweder einen einmaligen oder einen geplanten Pipelinemodus auswählen. Der nächste Schritt ist, die in lokalen und Cloud-basierten Datenspeichern hinterlegten Daten an einem einzigen Ort in der Cloud zu konsolidieren, wo Sie diese weiter analysieren.
- Umwandeln und Anreichern. Sobald die Daten an einem zentralen Speicherort gespeichert sind, transformieren Sie diese mit Azure Data Lake Analytics, HDInsight Hadoop und maschinellem Lernen. Sie nutzen Datenflüsse, um Datentransformationsgraphen zu erstellen und zu verwalten – ohne dass Sie etwas über Spark-Cluster oder Spark-Programmierung wissen müssen. Data Factory stellt eine Verbindung zu zahlreichen Datenquellen her und ruft diese ab, überträgt die Daten an einen zentralen Ort und führt eine Datenverarbeitung durch, um diese Daten zu bereinigen und anzureichern.
- Veröffentlichen. Abschließend werden die Cloud-Daten in lokale Quellen wie SQL Server konvertiert oder in einem Cloud-Speicher für Business-Intelligence- und Analyseanwendungen gespeichert.
- Überwachen. Sobald Ihre Datenintegrationspipeline erfolgreich bereitgestellt wurde, können Sie sie über die Azure-Monitor-API, Azure Monitor Logs und PowerShell überwachen. Azure Monitor lässt sich für den Empfang von Diagnoseprotokollen konfigurieren, die von Azure Data Factory generiert werden. Sie können dann die generierten Protokolle an Azure Event Hubs streamen und die Protokolle mit Log Analytics analysieren.
Anwendungsfälle aus der Praxis
Azure Data Factory ist in der Lage, Daten zwischen lokalen und Cloud-basierten Datenspeichern zu verschieben. Das ist nützlich, wenn Sie in die Cloud migrieren oder wenn Sie Ihre lokalen und Cloud-Datenspeicher synchron halten müssen.
Ein weiterer häufiger Anwendungsfall ist die Synchronisierung von Daten zwischen mehreren Cloud-basierten Datenspeichern. Das ist sinnvoll, wenn Sie mehrere Anwendungen oder Dienste haben, die auf dieselben Daten zugreifen müssen.
Data Factory übernimmt außerdem Extraktions-, Transformations- und Ladevorgänge, zum Beispiel, wenn Sie komplexe Transformationen an Ihren Daten vornehmen möchten.
Azure Data Factory über das Azure Portal erstellen
Um eine Azure Data Factory über das Azure Portal zu erstellen, gehen Sie folgendermaßen vor:
- Melden Sie sich im Azure Portal an.
- Wählen Sie im Menü Ressource erstellen.
- Wählen Sie Integration in der Liste links.
- Klicken Sie auf Data Factory in der Liste der Azure-Dienste, die im rechten Bereich angezeigt wird.
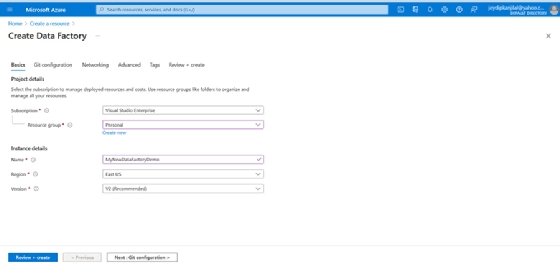
- Nun öffnet sich der Agent zum Erstellen einer Data Factory. Im Schirm Basics suchen Sie das Abonnement, für das Sie die Ressource erstellen wollen.
- Geben Sie die Ressourcengruppe und die Region an.
- Klicken Sie auf Überprüfen + erstellen.
- Klicken Sie abschließend auf Erstellen, wenn die Überprüfung erfolgreich war.
Kopieren von Daten mit Azure Data Factory
Um Daten mit Azure Data Factory zu kopieren, gehen Sie wie folgt vor:
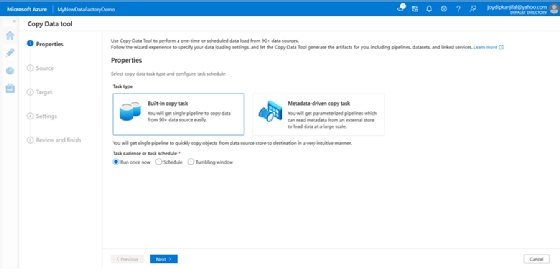
- Wählen Sie auf der Startseite der Azure Data Factory-Instanz, die Sie im vorherigen Abschnitt erstellt haben, die Kachel Erfassen aus.
- Wählen Sie auf der Seite Eigenschaften des Tools Daten kopieren die Option Integrierte Kopieraufgabe.
- Klicken Sie auf Weiter.
- Klicken Sie auf + Neue Verbindung erstellen auf dem Bildschirm Quelldatenspeicher.
- Wählen Sie Azure Blob Storage.
- Klicken Sie auf Weiter.
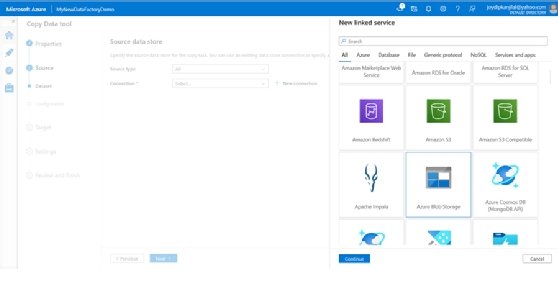
- Geben Sie auf dem Bildschirm Neue Verbindung einen Namen für Ihre Verbindung an.
- Wählen Sie das passende Azure-Abonnement.
- Wählen Sie das Speicherkonto, das Sie verwenden möchten, aus der Liste Speicherkontoname aus.
- Testen Sie die Verbindung.
- Wenn die Verbindung erfolgreich ist, klicken Sie auf Erstellen.
- Wählen Sie auf dem Bildschirm Quelldatenspeicher die gerade erstellte Verbindung aus.
- Wählen Sie im Abschnitt Datei oder Ordner die Option Durchsuchen, um zum Ordner zu navigieren, und wählen Sie die Datei aus, die Sie kopieren möchten.
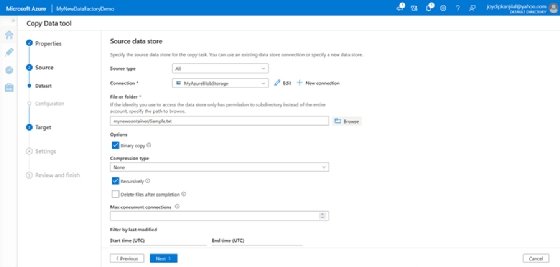
- Wählen Sie Binärkopie und klicken Sie dann auf Weiter, um fortzufahren.
- Wählen Sie auf dem Bildschirm Zieldatenspeicher die AzureBlobStorage-Verbindung aus, die Sie zuvor erstellt haben.
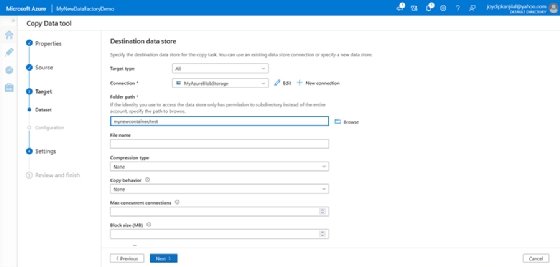
- Behalten Sie die anderen Einstellungen bei und klicken Sie auf Weiter, um fortzufahren.
- Geben Sie auf dem nächsten Bildschirm den Namen der Aufgabe an.
- Lassen Sie die anderen Standardeinstellungen unverändert und klicken Sie auf Weiter.
- Überprüfen Sie im Bildschirm Zusammenfassung alle Einstellungen und klicken Sie noch einmal auf Weiter.

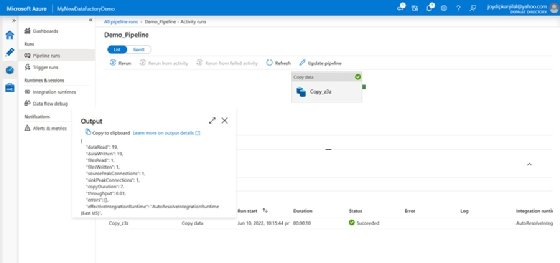
- Klicken Sie auf die Pipeline, um die Ansicht Pipelineausführungen aufzurufen.
- Klicken Sie unter Aktivitätsname auf den Link Output, um die Details der Aktivität anzuzeigen.