Elnur - stock.adobe.com
So nutzen Web Application Firewalls maschinelles Lernen
Maschinelles Lernen birgt für Sicherheitslösungen ein großes Potenzial, bringt aber auch Risiken mit sich. Es gilt zu erkennen, in welchen Bereichen der Einsatz sinnvoll ist.
Warum sollten Unternehmen eine Webapplikation mit einem zusätzlichen Sicherheitsprodukt wie einer Web Application Firewall (WAF) schützen? Mit der Art und Weise, wie heute Webapplikationen entwickelt, konfiguriert und verteilt werden, ist es nur bedingt möglich, alle Sicherheitslücken auszuräumen. Selbst wenn der inhouse geschriebene Programmcode entsprechende Qualitätsanforderungen erfüllt, so hängt dieser möglicherweise von Open-Source-Code ab, der dies nicht tut.
Wie kann nun trotzdem die Sicherheit einer Webapplikation gewährleisten werden? Die Antwort: Defense in Depth. Man kombiniert mehrere unabhängige Sicherheitssysteme und reduziert somit das Risiko eines erfolgreichen Angriffs. In einem solchen System spielt eine WAF bezüglich des Schutzes der Webapplikation eine zentrale Rolle.
Welche Vorteile bietet Machine Learning?
Mit dem allgemeinen Boom von Machine Learning (ML, maschinelles Lernen) in den letzten Jahren hält der Einsatz entsprechender Techniken vermehrt auch Einzug in den Bereich der IT-Security. Dieser Artikel liefert einen Überblick über die Chancen und Risiken ML-basierter Methoden im Bereich WAF.
Die Kernaufgabe einer WAF besteht darin, die nachgelagerten Webapplikationen vor technischen Angriffen zu schützen. Dabei kann maschinelles Lernen keineswegs nur für die Erkennung von Webattacken eingesetzt werden. Denkbar ist auch ein Einsatz im Bereich Log-Analyse oder für die Unterstützung des Administrators bei der Erstellung oder Optimierung komplexer WAF-Konfigurationen.
Klassische Methoden und Machine Learning – eine Ergänzung
Die meisten Sicherheitsrisiken in Webapplikationen können durch eine spezifische WAF-Funktion verhindert oder zumindest stark reduziert werden. Dabei kommen meist regelbasierte Systeme zum Einsatz. Bei älteren Webapplikationen liegt der Großteil der Applikationslogik auf dem Server und der Client folgt dem vorgegebenen Ablauf, beispielsweise indem er ein präsentiertes Formular vom Benutzer ausfüllen lässt.
Solche Systeme können sehr effektiv durch dynamische Regeln wie dem Verschlüsseln von URLs, Signieren von HTML-Formularelementen oder dem Einsatz von CSRF-Tokens (Cross-Site Request Forgery) geschützt werden. Moderne Webapplikationen dagegen, bei denen ein Großteil der Applikationslogik im Client ausgeführt wird, können teilweise nur sehr schwierig mit dynamischen Funktionen abgesichert werden.
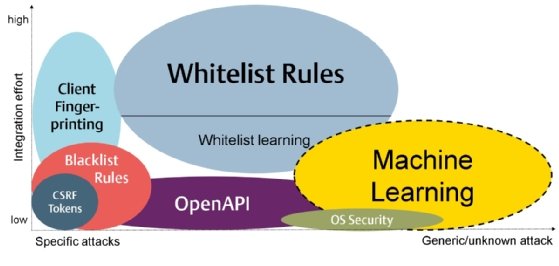
Ein Nachteil regelbasierter Systeme ist, dass diese meist nur gegen einen sehr spezifischen Angriffsvektor schützen oder aber mit hohem Integrationsaufwand verbunden sind. ML-basierte Methoden versprechen hier einen Mehrwert, da sie auch bei einer gewissen Unklarheit des Angriffsvektors eingesetzt werden können. Die nachfolgende Grafik beurteilt einige typische WAF Sicherheitsfunktionen bezüglich deren Integrationsaufwand sowie der Fähigkeit, unbekannte Angriffe zu erkennen. Wie man in der Grafik sieht, deckt kein einzelnes Sicherheitsfeature die ganze horizontale Achse, das heißt alle möglichen Angriffsvektoren, ab. Spezifische Angriffe wie zum Beispiel CSRF oder bekannte Code-Injection-Attacken werden weiterhin am effektivsten durch sehr spezifische, auf diesen Angriffsvektor zugeschnittene, Sicherheitsfunktionen verhindert.
Die richtige Aggregationsstufe
WAFs treffen typischerweise Entscheidungen basierend auf einzelnen Requests oder einer Gruppe von Requests, wie zum Beispiel alle Requests innerhalb einer HTTP-Session oder von derselben Source-IP-Adresse. Betrachtet man eine Gruppe von Requests innerhalb einer HTTP-Session, so können interessante Eigenschaften definiert und statistisch untersucht werden. Zum Beispiel kann die Wahrscheinlichkeit einer bestimmten Folge von HTTP-Requests innerhalb einer Session untersucht werden. Die typischen Folgen werden meist vom gewünschten Benutzerverhalten dominiert. Untypische Folgen deuten möglicherweise auf unerwünschte Aktivitäten wie zum Beispiel einen Web-Crawler hin, der die Links in einer unüblichen Reihenfolge aufruft. Eine Schwierigkeit beim Session-Scope besteht darin, bei einem Angriff genügend früh Gegenmaßnahmen wie das Blockieren der Session auszulösen. Ein weiteres Problem ist, dass Angreifer ihre Attacken auf mehrere Sessions verteilen können. Dies ist insbesondere bei öffentlich zugänglichen Webapplikationen einfach möglich.
Auch Machine Learning braucht Engineering
Um eine unerwünschte HTTP-Session mittels ML-basierten Methoden zu erkennen, müssen zuerst entsprechende Features definiert werden (Feature Engineering). Dabei werden aus den zugrunde liegenden Daten Attribute identifiziert, auf denen das Modell später Vorhersagen trifft. Dieser Schritt ist zentral für den Erfolg des Modells. Beispiele für solche Features in Webverkehr sind Verteilungen der Zeitabstände von Requests, HTTP-Objekt-Größen oder die Verteilung von HTTP-Status-Codes. Wie man an diesen Beispielen sieht, können aus einzelnen Basisattributen in den Rohdaten, wie zum Beispiel Timestamps, über mehrere Schritte komplexere Features konstruiert werden. Anschließend werden basierend auf diesen Features geeignete ML-Modelle ausgewählt, konfiguriert und trainiert.
Durch geeignete Kombination verschiedener Modelle entsteht nun ein System, das in der Lage ist, bestimmte Auffälligkeiten einer Web-Session zu identifizieren. Dieses System kann Fragen beantworten wie: Wurden einzelne Requests innerhalb der Session durch eine Person ausgeführt oder war ausschließlich eine Software beteiligt? Handelt es sich um einen gewöhnlichen Benutzer oder deutete sein Verhalten auf einen Hacker hin? Falls die Requests von einer Software ausgelöst wurden, handelt es sich um eine legitime Suchmaschine, ein Monitoring-Tool oder möglicherweise um einen unerwünschten Site-Crawler, Bot oder sogar ein Attack-Tool?

„Das Potenzial von ML-Modellen in Sicherheitsprodukten wie WAFs ist groß. Statistische Lösungsansätze bringen aber auch viele neue Risiken mit sich.“
Reto Ischi, Ergon Informatik
Jede Webapplikation kann dabei mit einem eigenen Modell trainiert und geschützt werden. Somit kann eine bestimmte Anomalie in einer Applikation ein gewöhnliches Verhalten in einer anderen Applikation sein. Dies ist ein weiterer Vorteil gegenüber statischen Sicherheitsfunktionen, die nur mit viel Aufwand für jede Webapplikation unterschiedlich konfiguriert und optimiert werden können. Beim Trainieren der Modelle muss zudem darauf geachtet werden, dass der Angreifer keinen Einfluss auf die Trainingsphase nehmen kann, oder dass die Modelle mit solchen unerwünschten Daten umgehen können.
Kein Schwarz-Weiß-Denken
Im Gegensatz zu klassischen, regelbasierten Systemen, liefern ML-Modelle keine Schwarz-Weiß-Antworten, sondern Wahrscheinlichkeitsverteilungen. Aktionen können nun in Abhängigkeit dieser Verteilung ausgelöst werden. Eine Session-Terminierung oder das zeitliche Blockieren einer Source-IP möchte man in der Regel nur auslösen, wenn ein Angriff eine hohe Wahrscheinlichkeit hat. Andere Aktionen wie das Einblenden eines Captchas sollen dagegen nur erfolgen, wenn Requests mit hoher Wahrscheinlichkeit automatisiert, zum Beispiel von einem Bot, ausgelöst wurden. Ist die Unsicherheit zu hoch, so können Session-Details auch nur geloggt oder an ein Umsystem, wie zum Beispiel einem Fraud Detection System, für zusätzliche Analysen und Entscheidungen weitergeleitet werden.
Sicherheit von ML-basierten Systemen
Da ML-Modelle heute in sehr kritischen Systemen wie selbstfahrenden Autos eingesetzt werden, in welchen falsche Entscheidungen fatale Folgen haben können, wird seit einigen Jahren vermehrt zum Thema der Robustheit dieser Modelle geforscht. Auch wenn zum Beispiel Straßenschilder ohne Probleme mit einer sehr hohen Genauigkeit erkannt werden können, so wurde gezeigt, dass bei nicht robusten Modellen ein Angreifer durch kaum sichtbare Veränderungen eines Stopp-Straßenschildes, das System dazu bringen kann, dass dieses das Schild als „Höchstgeschwindigkeit 80 km/h“ klassifiziert.
Diese Frage nach der Robustheit eines ML-Modells wird in vielen Projekten außer Acht gelassen. Es ist offensichtlich, dass im Sicherheitsumfeld diese Modelleigenschaft relevant ist. Eine relativ einfache Möglichkeit die Modelle robuster gegen solche Angriffe zu machen, ist, diese zusätzlich mit entsprechenden Angriffsbeispielen (Perturbed Train Data) zu trainieren.
Fazit
Das Potenzial von ML-Modellen in Sicherheitsprodukten wie WAFs ist groß. Statistische Lösungsansätze bringen aber auch viele neue Risiken mit sich. Die Kunst dabei ist zu erkennen, in welchen Bereichen die Systeme einen tatsächlichen Mehrwert liefern und wie diese dafür im Detail designed werden müssen, um Anforderungen an Sicherheit und insbesondere Betreibbarkeit zu erfüllen. Fundiertes Know-how im Bereich Applikationssicherheit sowie Machine Learning ist dabei zentral für den Erfolg eines solchen Projektes.
Über den Autor:
Reto Ischi ist Head of Research and Development Airlock WAF beim Zürcher Softwarehersteller Ergon und seit über 17 Jahren im Bereich der Informationssicherheit und Softwareentwicklung tätig. Zu seinen Aufgaben gehören unter anderem Design und Entwicklung neuer Sicherheitsfeatures. Reto Ischi hat an der ETH den Master in Informatik im Bereich Informationssicherheit absolviert und macht zurzeit eine Weiterbildung im Bereich Data Science an der ETH Zürich.
Die Autoren sind für den Inhalt und die Richtigkeit ihrer Beiträge selbst verantwortlich. Die dargelegten Meinungen geben die Ansichten der Autoren wieder und entsprechen nicht unbedingt denen von ComputerWeekly.de.