
phonlamaiphoto - stock.adobe.com
Retrieval Augmented Generation: Domänenwissen abfragen
Soll durch ein großen Sprachmodell spezialisiertes Domänenwissen abgefragt und die Gefahr von Halluzinationen reduziert werden, kommt Retrieval Augmented Generation ins Spiel.
Man stelle sich einmal vor, man hätte einen Koch, der einem alle kulinarischen Wünsche erfüllen könnte. Chefkoch RAGnar hat sich im Rahmen seiner Ausbildung ein großes Wissen über alle gängigen Kochschulen angeeignet, sei es in der französischen Küche beispielsweise die Zubereitung von Coq au Vin oder das Kochen einer traditionellen japanischen Nudelsuppe. Trotz seines breiten Wissens ist unser Chefkoch jedoch nicht in der Lage ohne Weiteres eine lokale Spezialität zu servieren, an die man sich vielleicht mit etwas Wehmut aus seiner Kindheit erinnert. Unser Koch bräuchte ein Rezept, um das Gericht nachkochen zu können und müsste zudem wissen, wo er dieses finden kann.
Diese Analogie soll die Problematik großer Sprachmodelle (Large Language Models, LLM) wie GPT-4 verdeutlichen. Seit der Einführung von ChatGPT durch OpenAI Ende 2022 hat solche generative KI große Verbreitung erfahren, im privaten wie auch wirtschaftlichen Bereich. Die Vorteile der Technologie liegen dabei zunächst auf der Hand. Während bisher für individuelle Probleme individuelle KI-Modelle trainiert, entwickelt und verprobt werden mussten, werden große Sprachmodelle wie GPT-4 auf einer breiten Datenbasis trainiert, um möglichst viele unterschiedliche Anwendungsfälle abbilden zu können. Neben einer deutlich kosteneffizienteren Anpassung solcher Modelle an individuelle Probleme, sind auch Hürden in der Umsetzung deutlich niedriger, da keine technische Expertise für aufwendige Trainings- und Testprozesse mehr benötigt werden.
Trotz dieser Vorteile haben solche Modelle aber wie unser Chefkoch das Problem, dass ihr Wissen endlich ist und sie nur über solche Inhalte Auskunft geben können, welche auch Teil ihrer Trainingsdaten waren. Was passiert, wenn Wissen abgefragt wird, welches eben nicht Teil dieser Trainingsdaten war, hört und liest man immer wieder in Verbindung mit dem Schlagwort Halluzination in den Medien. Der Begriff bezieht sich hierbei auf das Phänomen, dass LLM bei Nichtwissen Antworten scheinbar erfinden, ohne darauf in ihrer Antwort hinzuweisen.
Mitte 2023 machte ein Fall in den USA Schlagzeilen, der die Schwächen von ChatGPT und ähnlichen Technologien deutlich machte. Ein Passagier hatte die Fluggesellschaft Avianca verklagt, weil er durch einen Servierwagen an Bord am Knie verletzt worden war. Der Anwalt des Klägers verwies dabei auf mehrere frühere Urteile, von denen sich jedoch sechs als nicht existent herausstellten. Der Anwalt hatte ChatGPT nach solchen Urteilen befragt, ohne deren Echtheit zu überprüfen. Es stellte sich heraus, dass ChatGPT diese Urteile lediglich erfunden hatte.
Hier ist dem Modell jedoch keineswegs die Intention einer Lüge zu unterstellen. Große Sprachmodelle wie GPT-4 sind in erster Linie zunächst Wortprädiktoren. Das heißt, wird durch den Nutzenden eine Anfrage gestellt, prädiziert das Modell die wahrscheinlichste Fortführung des semantischen Inhalts. Der faktische Inhalt spielt dabei nur eine untergeordnete Rolle, da immer eine Ausgabe erfolgt, egal ob dieser Inhalt Teil der Trainingsdaten war oder nicht. Wie passt dieser Umstand nun zu der Verwendung von LLM in hochspezialisierten Bereichen?
LLM als Domain Knowledge Agent
Um die Vorteile von LLM zum Beispiel auch im wirtschaftlichen Sektor voll nutzen zu können, müssen entsprechende Modelle häufig auf hochspezielles Domänenwissen zugreifen können. Für die Verwendung von LLM beispielsweise als Kundenberater sollte das entsprechende Modell über spezifische Produktinformationen verfügen. Bei Verwendung im firmeninternen Support wären hier spezifische Informationen über Reiserichtlinien denkbar. Werden LLM für solche domänenspezifische Anwendungsfälle genutzt, werden entsprechende Implementierungen häufig auch als Domain Knowledge Agents bezeichnet.
 PD Dr. Immo Weber,
PD Dr. Immo Weber,
adesso
Die Frage, die sich nun stellt, ist wie dieses Wissen dem LLM vermittelt werden kann. Hierbei sind zunächst zwei Möglichkeiten naheliegend: 1. Ein neues Modell von Grund auf mit dem benötigten Wissen zu trainieren und 2. ein bestehendes Modell mit dem spezifischen Domänenwissen nachzutrainieren (Finetuning). Beide Ansätze haben den Nachteil, dass sie äußerst aufwendig, sehr kostenintensiv und in ihren Ausgaben nur wenig transparent sind. In den allermeisten Anwendungsfällen ist ein (Nach-)Training jedoch nicht notwendig. Stattdessen kann eine sogenannte Retrieval Augmented Generation (RAG) implementiert werden.
Der Begriff RAG stammt aus dem 2020 veröffentlichten Paper „Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks“ von Lewis et al. Die Ursprünge dieser Methode reichen jedoch bis in die 1970er Jahre zurück, als Wissenschaftler begannen, die ersten Frage-Antwort-Systeme zu entwickeln. Diese frühen Systeme nutzten bereits natürliche Sprachverarbeitung, waren jedoch auf sehr spezifische Themenbereiche beschränkt.
Ein Rezept für RAG
Genau wie bei unserem Chefkoch liegt die Lösung darin, dem LLM beizubringen Information aus externen Quellen zu beziehen. An Schulen wird ein ähnliches Vorgehen inzwischen als Informationskompetenz gelehrt. Genauso wie Schüler nicht mehr alles wissen müssen, müssen LLM im Prinzip auch nur wissen, wo sie suchen müssen.
Statt eines Trainings, bei welchem Informationen Teil des Modells selbst werden, wird bei RAG das Wissen extern zur Verfügung gestellt. Der große Vorteil liegt hierbei in der Flexibilität des Ansatzes. Dadurch können die Informationen des KI-Systems ohne großen Aufwand hochaktuell gehalten und theoretisch beliebig erweitert werden. Ein weiterer Vorteil gerade in anwendungskritischen Einsatzgebieten ist Transparenz im Sinne einer Trustworthy AI, da Antworten des RAG-Systems direkt mit Quellenangaben aus den Originaldokumenten verlinkt werden können.
Die Funktionsweise des Algorithmus lässt sich zunächst in zwei Phasen unterteilen:
1, einer Vorbereitungsphase und;
2. der Inferenzphase.
In Phase 1 (Abbildung 1, Mitte) werden die spezifischen Domäneninformationen für die Abfrage durch das LLM zunächst aufbereitet. Dazu wird aus den Quelldokumenten der reine Text extrahiert (I) und in kleine Abschnitte zerlegt (engl.: chunking, II). Die Länge dieser Textabschnitte stellt hierbei einen Parameter dar, den es bei der Feinimplementierung zu optimieren gilt. Anschließend werden die Textblöcke in ein numerisches Format übertragen (III). Das hat den großen Vorteil, dass der semantische Inhalt des Textes anschließend quantitativ verglichen werden kann. Mathematisch gesprochen, werden die Texte vektorisiert, also in einen hochdimensionalen Vektorraum übertragen. Hierfür kommt bereits ein spezielles Sprachmodell, ein sogenanntes Embedding Modell, zum Einsatz. Die Vektordaten werden schließlich in der Regel einer dedizierten Vektordatenbank vorgehalten (IV). Diese sind darauf optimiert Vektordaten möglichst effizient zu speichern und zu durchsuchen.
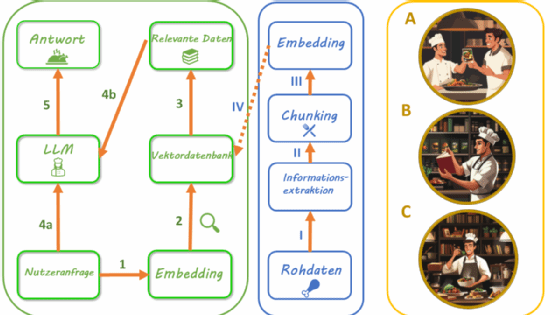
Nachdem in Phase 1 das Domänenwissen vorbereit wurde, findet Phase 2 (Abbildung 1, Links) im Live-Betrieb der Anwendung statt. Stellt ein Nutzender eine Anfrage an das RAG-System, wird diese zunächst wie in Phase 1 mittels des gleichen Embedding Modells vektorisiert, also in ein numerisches Format übertragen (1). Anschließend wird eine Ähnlichkeitssuche durchgeführt, bei welcher die vektorisierten Textblöcke in der Vektordatenbank quantitativ mit der Anfrage verglichen werden („Retrieval“ Phase, 2 und 3). Für die konkrete Implementierung der Ähnlichkeitssuche sind verschiedene Algorithmen denkbar, wobei die sogenannte Cosine Similarity häufig Anwendung findet. Die Top k ähnlichsten Einträge werden dann in Textform zusammen mit der Anfrage an ein LLM übergeben (4a und 4b), welches schließlich eine passende Antwort für den Nutzenden generiert (5) und meist über eine graphische Nutzeroberfläche anzeigt. Ähnlich wie die Textblockgröße stellt auch der Parameter Top K einen optimierbaren Parameter dar. Für die Generierung einer passenden Antwort durch das LLM werden Prompt-Engineering-Techniken eingesetzt, um die gefundenen Textblöcke möglichst effektiv in den Kontext der Anfrage zu setzen.
Grundsätzlich stellt der beschriebene Algorithmus jedoch lediglich die Basis für die Umsetzung eines RAG-Systems dar und kann je nach Anwendungsfall an verschiedenen Stellen des Vorgehens weiter optimiert werden.
 Sascha Windisch,
Sascha Windisch,
adesso
Zum Zeitpunkt der Erstellung dieses Beitrags stellen vor allem zwei Open-Source-Softwarebibliotheken den aktuellen Framework-Standard für eine Implementierung von RAG-Systemen dar: LangChain, sowie LlamaIndex. Im Gegensatz dazu ist die Auswahl an Softwarelösungen sowohl für Vektordatenbanken als auch Sprachmodellen ungleich größer. Bei ersteren kann sowohl zwischen kommerziellen (zum Beispiel Pinecone und Elasticsearch) und Open Source (beispielsweise Chroma und OpenSearch), als auch dedizierten (zum Beispiel Weaviate und Qdrant) und klassischen Datenbanken mit Unterstützung für Vektorsuche (zum Beispiel Cassandra und MongoDB) unterschieden werden. Für die Auswahl eines LLM kommen je nach Anwendungsfall unter anderem die großen kommerziellen Modelle wie GPT-4 (OpenAI), Claude 3.5 (Anthropic) oder Open-Source-Modelle wie die Mistral- (Mistral.ai) oder Llama-Modelle (Meta) in Betracht.
Ausblick
Wie Sprachmodelle selbst wird auch die RAG-Methodik stetig weiterentwickelt und durch immer neue Techniken und Softwarekomponenten ergänzt. Neben der Entwicklung neuer Schnittstellen wie Text2SQL werden auch fortwährend neue, spezielle Lösungsansätze entwickelt um zum Beispiel Probleme beim Chunking (zum Beispiel Context Expansion), Retrieval (beispielsweise Reranking), oder der Generierung von Antworten durch das LLM (zum Beispiel Query Transformation) zu verbessern.
Über die Autoren:
Immo Weber ist habilitierter Senior Consultant bei adesso mit den Schwerpunkten KI, GenAI und Data Science in der öffentlichen Verwaltung. Sascha Windisch ist Competence Center Leiter bei adesso und Berater mit den Schwerpunkten Fach- und Softwarearchitektur, KI, GenAI und Data Science, Anforderungsanalyse sowie Anforderungsmanagement für komplexe verteilte Systeme.
Die Autoren sind für den Inhalt und die Richtigkeit ihrer Beiträge selbst verantwortlich. Die dargelegten Meinungen geben die Ansichten der Autoren wieder.





