
alunablue - stock.adobe.com
Nur richtige Datenintegration macht generative KI erfolgreich
Das Potenzial generativer KI lässt sich nur dann komplett ausschöpfen, wenn Unternehmen die zentrale Rolle ihrer eigenen Daten erkennen und die Daten richtig integrieren.
ChatGPT hat am 30. November 2023 seinen ersten Geburtstag gefeiert. Natürlich ist der KI-Chatbot der Firma OpenAI nur eine generative KI-Anwendung unter vielen. Aber mit ChatGPT hat sich die künstliche Intelligenz unwiderruflich durchgesetzt.
Generative KI hat längst ihren Wert und ihr Potenzial, Unternehmen aller Größenordnungen zu schnellerer Innovation zu verhelfen, unter Beweis gestellt. Die Generierung neuer Inhalte über einfache Prompts – so wie wir es durch Suchmaschinen gewohnt sind – macht KI zu einer leistungsstarken Produktivitätshilfe. Laut Gartner planen 55 Prozent der Unternehmen den Einsatz von generativer KI und 78 Prozent der Führungskräfte sind der Meinung, dass die Vorteile der KI-Einführung die Risiken überwiegen. Eine Prognose von Forrester sagt voraus, dass es 2024 in einem von acht Führungsteams einen CAIO (Chief AI Officer) geben wird und 60 Prozent der Mitarbeitenden in Prompt Engineering geschult werden.
Wettbewerbsvorteil: KI mit eigenen Daten trainieren
Generative KI ist aber nicht nur eine universelle Produktivitätshilfe, die Informationen wie eine Suchmaschine aufzeigt. Unternehmen können auch ihre eigenen, proprietären Daten mit Basismodellen kombinieren, die zuvor auf einer breiten Basis öffentlicher Daten trainiert worden sind. So kann generative KI zur kenntnisreichsten Einheit innerhalb eines Unternehmens werden und unzählige Möglichkeiten für Innovationen eröffnen.
Wie bei allen Analysen ist jedoch auch generative KI nur so gut wie die jeweilige Datengrundlage. Um KI in vollem Umfang nutzen zu können, muss ein Unternehmen seine eigenen Daten beherrschen. Dies bedeutet eine solide Grundlage von Datenverarbeitungstechnologien und organisatorischen Normen, die eine verantwortungsvolle und effektive Nutzung von Daten ermöglichen.
Diese sogenannte Data Readiness für generative KI hängt von zwei Schlüsselelementen ab: Zum einen geht es um die Fähigkeit, Daten aus Datenbanken, Anwendungen und anderen Quellen auf automatisierte, zuverlässige, kosteneffiziente und sichere Weise bewegen und integrieren zu können. Und zum anderen muss in einer Organisation der Schutz und der Zugriff auf Daten durch klare Data-Governance-Bestimmungen geregelt sein. Diese Data Readiness wird in vielen Unternehmen noch immer nicht wirklich ernst genommen. Daher sind viele Versuche, die Möglichkeiten von Big Data und Data Science zu nutzen, oft von Beginn an zum Scheitern verurteilt.
Ein Großteil der Data-Science-Projekte schafft es nie in die Produktion. Und meist liegt es daran, dass Daten unorganisiert in Silos gespeichert sind und zudem in einer unausgereiften Dateninfrastruktur liegen.
Ausgereifte Datengrundlage ist Basis für Erfolg mit generativer KI
Ohne entsprechende Data Readiness wird das Prototyping, der Einsatz und das Testen von generativer KI – oder überhaupt jeder Art von Analytik – extrem schwierig. Dazu gehören sowohl technologische als auch organisatorische Elemente. Auf der technologischen Seite sind folgende Fähigkeiten unerlässlich:
- Ein zentrales, cloud-basiertes Daten-Repository, das als Single Source of Truth dienen kann.
- Ein Tool, das zuverlässig und automatisch Daten aus verschiedenen Quellen in großem Umfang aufnimmt und weitere Funktionen bietet: schnelle, zeitnahe Updates sowie die Zuverlässigkeit und die Fähigkeit zur schnellen Wiederherstellung nach Ausfällen.
- Ein Tool, das die kollaborative, versionskontrollierte Modellierung und Umwandlung von Daten unterstützt.
- Data-Governance-Funktionen wie die Möglichkeit, sensible Daten zu sperren und zu verschlüsseln, bevor sie in einem zentralen Repository landen. Aber auch Zugriffskontrolle und die Fähigkeit zur Katalogisierung von Daten sowie automatisierte Benutzerbereitstellung sind wesentliche Elemente.
Vor allem die Automatisierung ist ganz entscheidend für die effiziente, zuverlässige und skalierbare Datenbewegungen und -integration.
Auf der organisatorischen Seite müssen die Verantwortlichen im Unternehmen folgende Vorgehensweisen und Strukturen einführen:
- Eine skalierte Analytics-Organisation, in der Unternehmen neben einem Kernteam von Analysten auch Fachexpertinnen und -experten haben, die bestimmten Einheiten innerhalb ihrer Organisation zugeordnet sind.
- Regelmäßige Berichte sowie Stakeholder, die diese regelmäßig nutzen, um Entscheidungen zu treffen.
- Produktorientiertes Denken im Analytics-Bereich, bei dem die unter anderem Berichte, Dashboards und Modelle, die ein Team erstellt, auf die Bedürfnisse der Beteiligten zugeschnitten sind.
- Gute Sichtbarkeit der Daten, zum Beispiel durch Katalogisierung von Datenbeständen.
Die richtige Datenplattform-Architektur für generative KI
Generative KI selbstständig von Grund auf zu programmieren, ist ein kolossales Unterfangen, das Hunderte von Millionen Dollar kosten und enorm Zeit in Anspruch nehmen kann. Daher verwenden Unternehmen bereits verfügbare Basis- oder Grundmodelle. Das heißt, sie stützen sich auf eine kostenpflichtige Lösung, die bereits mit großen Mengen öffentlicher Daten trainiert wurde.
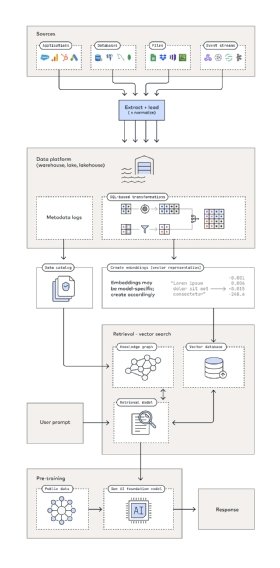
In der Anfangsphase spiegelt diese Architektur (siehe Abbildung 1) die grundlegenden analytischen Anwendungsfälle wider. Bereits hier braucht man eine Datenpipeline zum Extrahieren, Laden und Transformieren von Rohdaten in Modelle zur Unterstützung von Berichten, Dashboards und anderen Datenbeständen. Was aber danach kommt, ist einzigartig für generative KI. Denn Unternehmen können ein generatives KI-Modell von der Stange auf zwei Arten mit ihren Daten ergänzen:
Einerseits können sie Text in Aufzählungen konvertieren, diese in einer Vektordatenbank speichern, damit die generative KI diese in die Longterm Memory integrieren kann. So verbessern Unternehmen die Ergebnisse aus dem anfänglichen Training mit den eigenen exklusiven Unternehmensdaten. Andererseits können Unternehmen große Sprachmodelle (Large Language Model, LLM) mit Wissensgraphen kombinieren. So kodieren Unternehmen explizit semantisches Verständnis in das Modell und nicht nur statistische Wortassoziationen.
Auch wenn es immer mehr Standard-Tools für die Verwaltung von Dateninfrastrukturen mit generativer KI gibt, ist es wahrscheinlich, dass sich Unternehmen in hohem Maße auf technisches, datenwissenschaftliches und KI-Fachwissen verlassen müssen. Nur so können alle Teile korrekt zusammenwirken und brauchbare Anwendungen auf der Grundlage der Architektur entwickeln.

„Das Potenzial von generativer KI kann nur dann voll ausgeschöpft werden, wenn Unternehmen die zentrale Rolle ihrer eigenen Daten erkennen.“
Alexander Zschaler, Fivetran
Das Potenzial von generativer KI kann nur dann voll ausgeschöpft werden, wenn Unternehmen die zentrale Rolle ihrer eigenen Daten erkennen. Indem sie die Beherrschung von Daten durch die Implementierung fortschrittlicher Datenverarbeitungstechnologien in den Vordergrund stellen und eine Kultur des verantwortungsvollen Umgangs mit Daten pflegen, können Unternehmen die wahre Kraft von generativer KI freisetzen und ihre optimale Leistung und ihren ethischen Einsatz in einer sich schnell entwickelnden technologischen Landschaft sicherstellen.
Über den Autor:
Alexander Zschaler ist Regional Vice President DACH und CEE bei Fivetran.
Erfahren Sie mehr über Künstliche Intelligenz (KI) und Machine Learning (ML)
-
![]()
Moderne Informationsarchitekturen: KI-fähig statt nur digital
-
![]()
Unternehmen sind besser auf Angriffe vorbereitet
Von: Malte Jeschke
-
![]()
Kostenloses E-Handbook: Datenanalysen mit generativer KI
Von: Tobias Servaty-Wendehost
-
![]()
Generative KI: Datenrisiken bei LLMs erkennen und minimieren
Von: Oliver Schonschek



