
Data-to-Value-Konzepte und wie man sie erfolgreich umsetzt
Daten gelten für viele Unternehmen als wertvolles Gut. Allerdings müssen die Daten sauber verarbeitet werden und eine passende Datenarchitektur aufweisen.
In der digital vernetzten Welt gelten Daten als wertvoller Rohstoff und Wirtschaftsgut. Sie fallen in großer Menge als Nebenprodukt digitaler Prozesse, Kommunikation und Wertschöpfungsketten in Unternehmen an. Doch im Gegensatz zu üblichen Marktwerten wie Immobilien oder physische Güter besitzen Daten keinen inhärenten Wert.
Erfolgreiche Unternehmen entfalten mit Data-to-Value-Konzepten und -Strategien bereits heute das monetäre Potenzial ihrer Daten und verschaffen sich zahlreiche Vorteile gegenüber Mitbewerbern. Gleichzeitig wächst der Abstand zu den sogenannten Late Followern (Nachzüglern), die vor einer ganzen Reihe an Fragestellungen stehen: Welche Handlungsbereiche müssen betrachtet werden? Was ist Datengesundheit und warum ist sie essenziell für erfolgreiche Konzepte? Wie baue ich das nötige Wissen und Können bei meinen Mitarbeiterinnen und Mitarbeitern auf?
Wann sind Daten wertvoll?
Für das Jahr 2025 prognostiziert der Statistikdienst Statista ein weltweit generiertes Datenvolumen von insgesamt 175 Zettabyte. Das sind 175 Milliarden Terrabyte, was in etwa der Datenmenge von 5,4 Millionen Jahren Film in Blue-Ray-Qualität entspricht. Der Großteil dieser Daten liegt dabei heterogen beziehungsweise unstrukturiert vor und durchläuft einen gewissen Lebenszyklus: von der Erzeugung über die Verarbeitung und Veröffentlichung bis zur Archivierung. Die Chance, dass diese Daten unangetastet auf unterschiedlichsten Speichermedien verwaisen und damit wertlos bleiben, ist äußerst groß.
Denn das monetäre Potenzial wird erst freigeschaltet, indem die jeweiligen Rohdaten aufbereitet und angereichert werden, um sie anschließend zu visualisieren und in den jeweiligen Kontext zu setzen. Sparen die Unternehmenstätigkeiten, die aus einer daraus resultierenden Analyse abgeleitet werden, Geld oder sorgen für zusätzlichen Umsatz beziehungsweise Gewinn, generieren die Daten zusätzlichen Wert. Doch die gewonnenen Vorteile erstrecken sich gleich über mehrere Ebenen: das Datenökosystem selbst, digitale Unternehmensprozesse, das Mitarbeiterverhalten und die interne sowie externe Monetarisierung (siehe Abbildung 1).
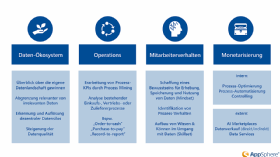
Unternehmen, die diese Vorteile identifiziert und entsprechende Maßnahmen strategisch implementiert haben, profitieren in der Regel zunächst durch eine höhere Transparenz, den Rückgewinn der Übersicht über die vorhandene Datenlandschaft und eine Steigerung der Mitarbeitereffizienz. Für den langfristigen Erfolg sind zudem strategische Maßnahmen vonnöten, die auf ein gemeinsam vereinbartes Zielbild einzahlen. Dieses führt konkrete Maßnahmen in den einzelnen Handlungsbereichen zu einer realisierbaren Roadmap zusammen.
Nur gesunde Daten sind gute Daten
Durch unstrukturierte Transformationsprojekte und eine historisch gewachsene Basis an Systemen und Technologien laufen zahlreiche Unternehmen Gefahr, ihre eigene Transparenz negativ zu beeinträchtigen. Denn obwohl laut einer Talend-Studie 64 Prozent der befragten Führungskräfte täglich mit Daten arbeiten, verlassen sich lediglich 40 Prozent darauf, dass die Daten vertrauenswürdig und damit verwertbar sind.
Ein entscheidender Faktor für die Ausschöpfung des Potenzials ist also die Beachtung und Pflege der sogenannten Datengesundheit. Dabei reicht es nicht aus, den rechtlichen und regulatorischen Anforderungen, zum Beispiel der EU-DSGVO, zu entsprechen. Per Definition ist der optimale Zustand von Daten über drei Attribute zu erreichen:
- Gültigkeit der Daten: Die vorliegenden Daten sind frei von Messfehlern oder Datenverunreinigungen und transportieren die gewünschte Information.
- Vollständigkeit der Daten: Die erhobenen Daten enthalten alle Informationen, zu deren Transport sie erhoben wurden.
- Eignung für die Datenanalyse: Unter Bezugnahme auf die Punkte 1 und 2 müssen Daten geeignet sein (gültig, vollständig, rechtlich/regulatorisch sauber), um mehrwerthaltig analysiert zu werden.
Vereinfacht lässt sich sagen, dass gesunde Daten diejenigen sind, die mit den richtigen Informationen zur richtigen Zeit beim richtigen Menschen im richtigen Kontext vorliegen. Denn ohne diese Voraussetzungen sind sie wertlos. Dabei genügen die Daten gleichermaßen allen regulatorischen und rechtlichen Voraussetzungen, so dass deren Nutzung ohne eine Zustandsprüfung möglich ist. Die Vorteile einer solchen Behandlung sind vielfältig und schaffen die Basis für Automatisierung, die Einführung künstlicher Intelligenz oder maschinellen Lernens.
Um von Beginn an gesunde Daten zu erhalten, ist ein strukturiertes Vorgehen notwendig, das von Beginn an die Faktoren bedenkt, die eine langfristig erfolgreiche Einführung von Data-to-Value-Maßnahmen ermöglichen.
Der Weg zu Advanced Data Analytics
Erfahrungsgemäß verläuft ein nachhaltiges Projekt zum Thema Data-to-Value oder Advanced Data Analytics in drei Phasen ab: dem initialen Scoping beziehungsweise dem Aufbau eines Datenzielbilds, dem kontinuierlichen Lernen zur Verfestigung gewonnenen Wissens und Könnens, und der Umsetzung erarbeiteter Use Cases und Initiativen.
Aus den Grundsätzen Individualität und Ganzheitlichkeit dient das Datenzielbild zur Beantwortung initialer Fragen, zum Beispiel: „Wo stehen wir heute und welche Handlungsfelder müssen wir betrachten? Welche Voraussetzungen sind dafür nötig? Wie identifiziere ich Daten in meinem Unternehmen, die monetäres Potenzial aufweisen?“
Auf Basis von Stakeholder- und Kunden-Interviews werden in einem ersten Schritt die Bedarfe und Anliegen der Nutzerinnen und Nutzer identifiziert und als Fundament für den Umgang des Datenzielbilds erhoben. Dies geschieht meist anhand humanzentrischer Methoden wie Design Thinking.
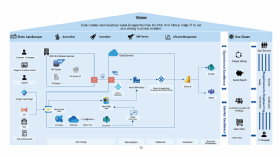
Im zweiten Schritt werden Datenquellen erfasst und Anwendungsfälle im Unternehmen herausgearbeitet, um sie nach Dringlichkeit und Wichtigkeit aufzuschlüsseln. Aus diesen beiden Komponenten wird eine Visualisierung der Datenlandschaft herausgearbeitet und an eine Ausarbeitung des Zielzustandes gekoppelt. Sie dient als Grundlage für die Roadmap zur Umsetzung des Zielbilds (siehe Abbildung 2), der Berücksichtigung von Abhängigkeiten und Schätzung der Aufwände.
Für den notwendigen Aufbau von Wissen und zugehörigen Fähigkeiten im Umgang mit Daten und deren Analyse ist es essenziell, den Vorgang des Vergessens durch regelmäßiges Wiederholen des Lernstoffs abzumindern. Mit Reinforced Learning und 1:1-Coachings lernen Mitarbeiterinnen und Mitarbeiter anhand realer Uses Cases ihres Unternehmens, die erlangten Erkenntnissen im Alltag anzuwenden.
Die Methodik Reinforced Learning bezieht sich dabei auf die mehrfache Wiederholung zur Festigung des Gelernten. Sie geht davon aus, dass die Rate, in der Informationen vergessen werden, mit jeder Auffrischung sinkt. Als Formate bieten sich hierfür regelmäßige Hackathons an, die zum Beispiel mit Unterstützung von Hausaufgaben eine messbare Kontinuität beim Wissensaufbau und der Verfestigung erzeugen. Nur so ist sichergestellt, dass die gesunden Daten auch fehlerfrei interpretiert und fachlich korrekt weiterverarbeitet oder analysiert werden.
Um in gesammelte Daten eine Ordnung zu bringen, diese anschließend zu analysieren und hieraus unternehmerische, monetär relevante Entscheidungen abzuleiten, bedarf es also eines hohen Schulungsgrades. Doch wie bereitet man Daten so auf, dass man die gewünschten Informationen erhält?
Die Grundlage bietet ein sogenannter Data Lake als System zur Speicherung unterschiedlichster Daten im Rohformat. Die Technologie ermöglicht es, strukturierte (aus Datenbanken, CSV-, XML- oder JSON-Dateien) genauso wie unstrukturierte Daten (E-Mails, Dokumente, Bilder, Audiodateien) in einem einzigen Speicher zu verwalten. Data Lakes sind in der Lage, sämtliche anfallende Unternehmensdaten in gigantischer Größe zu verarbeiten.
Um trotz der verschiedenen Datenquellen und -formate die Bildung von Silos zu vermeiden und relevante Daten miteinander zu verknüpfen, setzt sich seit einigen Jahren das Architekturkonzept Data Fabric durch. Dabei werden mit verschiedenen Cloud-Diensten die Verbindungen von internen oder externen Datenquellen miteinander verwoben und harmonisiert. Dies ist vor allem im Hinblick auf den Parallelbetrieb von (Hybrid-) Cloud- und On-Premises-Umgebungen von Vorteil.

„Sind die richtigen Fragestellungen und Perspektiven mit Unterstützung eines Datenzielbildes erarbeitet, das nötige Wissen zum Umgang mit Daten im Unternehmen verankert und eine Data Fabric als flexible Grundlage geschaffen, erweisen sich die Anwendungsfälle und -bereiche als vielschichtig.“
Florian Junge, AppSphere
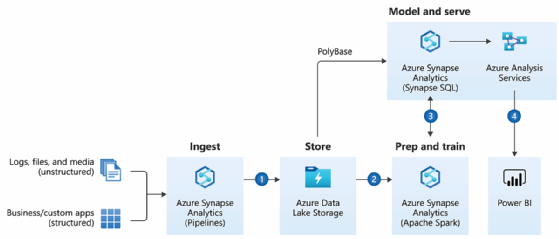
Anbieter wie zum Beispiel Microsoft ermöglich mit dem Enterprise Data Warehouse skalierbare Datenspeicherlösungen, die zahlreise Zusatzdienste zur Strukturierung, Analyse und Weiterverarbeitung direkt mitliefern (siehe Abbildung 3).
Sie erlauben es, die Datenanalyse als One-Stop-Shop zu implementieren und vorhandene sowie anfallende Datensätze interpretierbar und damit nutzbar zu machen. Business-Intelligence-Tools, zum Beispiel Microsoft Power BI oder integrierte KI-Plattformen, ermöglichen es anschließend, die Daten zu visualisieren, zu den richtigen Rezipientinnen und Rezipienten zu transportieren oder auf Basis künstlicher Intelligenz weiterführende Entscheidungen zu treffen.
Mit den richtigen Daten zu richtigen Entscheidungen
Als logische Weiterführung der Data-Lake-Konzepte bietet die Data Fabric eine umfassende Datenbasis zur Ableitung von Schritten zur Optimierung unternehmerischer Prozesse, einer Umsatzsteigerung oder der Anpassung vorhandener Zulieferketten. Sind die richtigen Fragestellungen und Perspektiven mit Unterstützung eines Datenzielbildes erarbeitet, das nötige Wissen zum Umgang mit Daten im Unternehmen verankert und eine Data Fabric als flexible Grundlage geschaffen, erweisen sich die Anwendungsfälle und -bereiche als vielschichtig.

„Um trotz der verschiedenen Datenquellen und -formate die Bildung von Silos zu vermeiden und relevante Daten miteinander zu verknüpfen, setzt sich seit einigen Jahren das Architekturkonzept Data Fabric durch.“
Nils Reger, AppSphere AG
Unternehmensinterne Optimierungen wie die Auswertung von Recruiting-Prozessen durch Process Mining, Auswertungen von Marketingkampagnen oder die Einführung von Controlling-Maßnahmen über automatisierte Reportings bieten zahllose Ansatzpunkte für positive Verhaltensänderungen von Mitarbeiterinnen und Mitarbeitern zur Steigerung der operativen Exzellenz.
Auch extern lassen sich die erhobenen Daten monetarisieren: Vom direkten Verkauf der erhobenen Analysedaten über das Angebot datenbasierter Optimierungen auf Basis der eigenen Erkenntnisse bis hin zu datengetriebenen Geschäftsmodellen, speziell im eCommerce sind die Beispielfälle schier endlos.
Über die Autoren:
Nils Reger betreut als Division Manager & Consultant bei der AppSphere AG das Thema Business Innovation. Als zertifizierter Design-Thinking-Experte entwickelt er neue digitale und disruptive Geschäftsmodelle/-prozesse nach humanzentrischem Vorgehen, um den Fortschritt und Erfolg seiner Kunden zu sichern.
Florian Junge ist Division Manager und betreut bei der AppSphere AG das Marketing- und Partner-Management-Team. Auf Grundlage bisheriger Stationen, unter anderem im Consulting, der Systemadministration und im Vertrieb, sowie mit einem breiten Wissensspektrum bis zu Psychologie, Rhetorik und Philosophie ist er in der Lage, komplexe Inhalte einfach zu transportieren.
Die Autoren sind für den Inhalt und die Richtigkeit ihrer Beiträge selbst verantwortlich. Die dargelegten Meinungen geben die Ansichten der Autoren wieder.






