
Getty Images/iStockphoto
Was zeichnet eine Analysepipeline aus?
Analysepipelines befinden sich traditionell im Verborgenen. Das ändert sich gerade, da Unternehmen ihre Daten agil verarbeiten müssen. Was zeichnet eine Analysepipeline aus?

In der heutigen datengesteuerten Wirtschaft können es sich Unternehmen nicht leisten, Probleme mit Daten zu haben. Aber viele haben Probleme. Trotz der explodierenden Datenmengen, die Unternehmen anhäufen, tun sie sich immer noch schwer, auf Daten ohne Hindernisse zuzugreifen und sie gewinnbringend zu nutzen.
Um die Geschwindigkeit von Datenanalysen zu beschleunigen und die gewonnenen Erkenntnisse zu verwerten, konstruieren Dateningenieure Datenanalysepipelines.
Was ist eine Datenanalysepipelines?
Eine Datenanalysepipeline optimiert den Datenfluss. Sie führt manuelle Schritte zu einem Prozess zusammen und stellt den Datenfluss sicher. Das explizite Ziel einer solchen Pipeline ist, die Geschwindigkeit der Datenanalyse und die Qualität der Ergebnisse zu verbessern. Ähnlich wie bei einer CI/CD-Pipeline (Continuous Integration/Continuous Delivery), die von einem DevOps-Team verwendet wird, liegt der Vorteil einer Datenanalysepipeline vor allem in der Automatisierung von Aufgaben und der effizienteren, schnelleren Abwicklung.
„Wenn mich der Leiter einer Finanzabteilung um einen Cashflow-Bericht bittet, muss ich die Daten möglicherweise manuell extrahieren und den Datensatz selbst aktualisieren“, sagt Dan Maycock, Principal of Engineering and Analysis beim Datenspezialisten Loftus Labs. „Habe ich eine Pipeline, geschieht das automatisch.“
Laut Pieter Vanlperen, Managing Partner von PWV Consultants, einem Beratungsunternehmen für Prozessmodernisierung, gibt es weitere Bereiche, die zumindest eine gewisse Automatisierung in der Analytics-Pipeline erfordern. Dazu gehören Data Governance, Datenqualität, Datennutzbarkeit und Kategorisierung – je nachdem, wie fortgeschritten die Pipeline ist.
Da jede Pipeline einen anderen Zweck erfüllen kann ist es üblich, mehr als eine Analysepipeline zu haben. Colleen Tartow, Director of Engineering bei Starburst Data, einem Anbieter von Plattformen für verteilte SQL-Query-Engines, sagt, dass Data Engineering für die Funktionen von Pipelines von entscheidender Bedeutung ist, da diese oft komplex sind und einen unterschiedlichen Reifegrad aufweisen.
„Sie können eine einfache Cloud-native Pipeline mit einem modernen Data Stack oder eine On-Premises-Infrastruktur haben, die neben der eigentlichen Datenpipeline selbst ständiges Management erfordert“, sagt sie.
Maycock verwendet eine Pipeline, um Daten von ihrer ursprünglichen Quelle zu einem zentralen Repository zu transportieren. Eine andere Pipeline nutzt sie, um Daten vom zentralen Repository zu einer Map, einem BI-Tool oder einem Datenmodell zu transportieren.
„In den frühen 2000er Jahren, als ich anfing, war man beim Aufbau und der Pflege von Pipelines auf sich allein gestellt“, sagt er. „Aber das ist heute nicht mehr der Fall.“
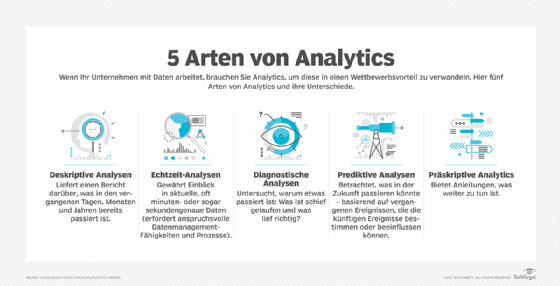
Vorteile einer Analysepipeline
Analysepipelines können Unternehmen dabei unterstützen, ein höheres Maß an Agilität und Resilienz zu erreichen – insbesondere, wenn sie „iterativ aufgebaut“ werden.
„Der Gedanke dahinter ist, dass Sie Ihre Entwürfe durch den Canvas, auf dem die Pipeline aufgebaut ist, iterativ weiterentwickeln. Der Vorteil ist eine höhere Produktivität“, sagt Arvind Prabhakar, CTO von StreamSets, einem Anbieter einer DataOps-Plattform.
Analysepipelines bieten ebenso wie CI/CD-Pipelines einen Überblick über die technischen und betrieblichen Funktionen. Das ermöglicht kontinuierliche Feedback-Schleifen, schnellere Iterationen und eine fixe Problemlösung. Laut Prabhakar behandelte die vorherige Generation von Plattformen und Tools Datenoperationen als versteckte Workloads.
„In dieser neuen Welt von DataOps, in der jeder Endpunkt und jede Pipeline potenziell das schwächste Glied ist, brauchen Sie die Möglichkeit zur ständigen Überwachung und Verwaltung. Denn die Pipelines sind selbst ein Spiegelbild der Entwicklung ihrer Datenarchitektur“, sagt Prabhakar.
Ein funktionsübergreifender Einblick in die Analysepipeline kann zu Prozessverbesserungen beitragen. Weil die Daten beobachtbar sind, wird sichergestellt, dass die Geschäftsanforderungen und -prozesse auch in der Pipeline modelliert werden.
„Diese Pipelines sind nicht nur Artefakte der Designentscheidungen von Dateningenieuren“, sagt Prabhakar. „Sie spiegeln vielmehr die Geschäftsprozesse wider, die in der Datenarchitektur des Unternehmens verankert sind.“
Skalierbarkeit von Datenanalysepipelines
Damit sich die Analysepipeline an wachsende Datenmengen anpasst, muss sie skalierbar sein. Skalierbarkeit ist deshalb eine zentrale Anforderung. Es sollte jedoch nicht nur die Skalierbarkeit berücksichtigt werden, sondern auch die Integration in die vorhandenen Analysefunktionen der Datenarchitektur.
Beim Aufbau einer skalierbaren Datenanalysepipeline sollten sowohl die Eingabedaten als auch die Ausgabedaten berücksichtigt werden. Die Kenntnis des Kontexts und der Menge der Eingabedaten kann bei der Bestimmung des Formats für die Datenspeicherung und der entsprechenden Technologie unterstützen. Berücksichtigen Sie bei den Ausgabedaten auch die Endanwender. Datenanalysten sind in hohem Maße auf diese Informationen angewiesen, daher müssen die Ausgabedaten für sie zugänglich und transparent sein.
Überlegen Sie auch, wie viele Daten die Analysepipeline aufnehmen kann. Die Infrastruktur muss in der Lage sein, eine plötzliche Änderung des Datenvolumens zu bewältigen, zum Beispiel aufgrund von Unternehmenswachstum. Eine Option besteht darin, die Pipeline in der Cloud einzurichten. Dies gewährleistet mehr Flexibilität und letztlich Skalierbarkeit.
Herausforderungen bei der Erstellung einer Analysepipeline
Der Zweck einer Analysepipeline besteht darin, die Bereitstellung von Daten zu beschleunigen – doch ein häufiges Hindernis sind die Daten selbst.
„Ich habe vielleicht eine Pipeline aufgebaut, aber ich habe eigentlich keine weiteren Informationen, weil das Data Warehouse oder der Data Lake, die ich aufgebaut habe, so schlecht gemanagt werden, dass das Ganze ein Sumpf ist“, sagt Vanlperen.
Er sagt, dass eine schlechte Governance die Daten schnell unbrauchbar macht. Deshalb ist es von zentraler Bedeutung, zu verstehen, welche Datenquellen wichtig sind. Diese müssen dann so optimiert werden, dass sie nützlich sind. Auch die Vielfalt der Datenquellen kann problematisch sein.
„Jede Plattform kann ihre eigene API und ihr eigenes Datenmodell haben. Schließlich spielt es bei der Softwareentwicklung nicht unbedingt eine Rolle, wie die Daten einer Datenpipeline oder einer ETL-Plattform präsentiert werden“, sagt Maycock. „Je nachdem, wie fremd die Plattform ist, kann es schwierig sein, eine Verbindung zu ihr herzustellen und Daten zu extrahieren sowie auf die Informationen auf konsistente Weise zuzugreifen.“
Doch es gibt ein weiteres Problem, mit dem Unternehmen häufig konfrontiert sind. So ist in vielen Unternehmen niemand dafür verantwortlich, den vollständigen Bestand der internen und von Drittanbietern zur Verfügung gestellten Daten zu kennen. Manche meinen, dies sei ein verräterisches Zeichen dafür, dass ein Chief Data Officer oder zumindest ein Verantwortlicher für das Verständnis und die Operationalisierung von Daten benötigt wird.
„Vor zehn Jahren wurde vom Dateningenieur erwartet, dass er alles weiß, und er erhielt einen großen Zettel, der alle Spezifikationen der Dateninfrastrukturen enthielt“, erklärt Prabhakar. „Heute hat der Dateningenieur keine Ahnung, woher die Daten kommen, wem sie gehören oder woher sie stammen – geschweige denn, dass er Schema, Struktur und Semantik der Daten kennt.“
Vor zehn Jahren arbeiteten Dateningenieure und Betriebspersonal auch oft in Datensilos – was heute nicht mehr der Fall sein sollte. Schließlich kann die Trennung zwischen den Teams zu Reibungen führen, die die Wertschöpfung verlangsamen. Eine funktionsübergreifende Unterbrechung kann sich auch negativ auf den Geschäftsbetrieb auswirken. Wenn beispielsweise in der Analysepipeline zehn Prozent der Daten verloren gehen, sind die nachgelagerten Analyseergebnisse zweifelhaft.
„Wenn Sie über den kontinuierlichen Betrieb sprechen, besteht das Ziel der Pipeline darin, eine enge Feedback-Schleife zwischen den Dateningenieuren und den Operatoren zu schaffen“, erläutert Prabhakar. „Sie wollen, dass die Pipelines automatisch anzeigen, dass sich etwas geändert hat.“
Analysepipelines sind für jedes erkenntnisorientierte Unternehmen unerlässlich. Wenn sie gut konzipiert und implementiert sind, können sie jede Organisation unterstützen, ihre strategischen Ziele schneller zu erreichen.






