
Creativeapril - Fotolia
Warum Anbieter wie Infinidat auf Always On setzen
Infinidat bietet ein Always-On-Konzept, das aufwendige Restore-Prozesse obsolet machen soll. Eine Garantie verspricht optimierte Kosten, Zuverlässigkeit und Performance.

Speicherhersteller wie Infinidat erkennen, dass Daten nicht nur Basis von Geschäftsprozessen sind, sondern auch die Grundlage für den Wettbewerbsvorteil des Unternehmens. Deswegen propagiert das Unternehmen eine Always-On-Strategie, die bereits eine Geschäftsanforderung vieler Unternehmen ist. Andere Anwender sollen durch diese Initiative beziehungsweise dieses Lösungsangebot realisieren, dass Hochverfügbarkeit einige essentielle Problem lösen kann.
Sind Daten nicht verfügbar, ist es in den meisten Fällen unmöglich, Kunden zu bedienen oder Dienste zur Verfügung zu stellen. Immer mehr Interaktionen mit Kunden und Partnern erfolgen auf dem digitalen Weg. Steht dieser nicht zur Verfügung, birgt dies klare Geschäftsrisiken. Endanwender und andere Kunden erwarten Datenverfügbarkeit und reagieren loyal dem Anbieter gegenüber, der dies bieten kann, denn oftmals sind sie nicht gewillt, auf einen Service oder bestimmte Daten zu warten.
So zeigt eine Google-Studie beispielsweise, dass 53 Prozent der Internetnutzer eine Webseite verlassen, wenn diese nicht in drei Sekunden geladen wird. Das lässt sich in bestimmten Maße auf Geschäftsdaten übertragen. Gartner hingegen bemisst die Kosten für eine Minute Datenausfall mit rund 5.600 US-Dollar. Diese Zahl mag je nach Branche und Geschäftsumfeld variieren, aber welches Unternehmen möchte durch eine Stunde Datenausfall das Risiko eingehen, eine sechsstellige Summe zu verlieren?
In Rechenzentren gibt es immer mehrere potenzielle Fehlerquellen, womit IT-Organisationen seit Jahren zu kämpfen haben. Sie müssen die Dateninfrastruktur so gestalten, dass sie eine Hochverfügbarkeit gewährleisten, also ein Always On garantieren. Oft gehen diese Architekturen mit hohen Kosten und Komplexität einher. Damit eine Lösung wirklich immer verfügbar ist, muss sie sowohl Recovery-Point-Objective-Ziel (RPO) von Null als auch ein Recovery-Time-Objective-Ziel (RTO) von Null erreichen. Dies sind notwendige Anforderungen, die eine Always-On-Lösung erfüllen sollte, allerdings gibt es weitere Ansprüche, die eine solche Lösung erfüllen muss.
Herausforderungen einer Always-On-Umgebung
Eine Infrastruktur ist immer anfällig für physische Ausfälle. Speichersysteme sind immer durch ihren physischen Standort begrenzt – wenn eine kritische Rechenzentrumsinfrastruktur ausfällt (zum Beispiel Strom, Netzwerk, WAN), kann es sein, dass das Storage-Array die Daten noch gespeichert hat, aber für die Hosts sind diese nicht zugänglich. Jede Lösung, die dieses Problem angeht, muss geografisch verteilt sein, um die Möglichkeit eines Ausfalls auf Rechenzentrumsebene beziehungsweise generell auf Hardwareebene zu vermeiden.
Des Weiteren haben viele Hochverfügbarkeitsumgebungen einen gewissen Performance-Overhead. Jede Infrastruktur, die geografisch verteilt ist und einen RPO von Null garantieren muss, erzeugt einen gewissen Performance-Overhead, da die Daten über das WAN transportiert werden, was wiederum höhere Latenzen nach sich zieht.
Werden Datensätze an einem Standort als „lokal“ und nicht am anderen als lokal verwaltet, erhöht sich der Performance-Overhead, wenn diese Datensätzen am externen Standort verarbeitet werden, da die Daten das WAN zweimal passieren, was die Latenzzeit entsprechend verdoppelt. Jede Lösung, die einen RPO von Null garantieren muss, muss wirklich „Always On“ sein. Der Performance-Overhead darf dabei nur minimal sein, damit mehr Anwendungen von einem automatisierten Failover profitieren können.
Mit einem hohen Performance-Overhead (Latenzzeit), der viele Anwendungen aufgrund von Parallelitätsbeschränkungen (insbesondere Datenbanken) dramatisch beeinträchtigt, sind Always-On-Lösungen oft nur begrenzt für Tier-1-Anwendungen verwendbar, was für die Aufrechterhaltung des Geschäftsbetriebs entscheidend ist. Die gesamte Wiederherstellung von Tier-2-Anwendungen, die für die Kundenzufriedenheit oft wichtig sind, muss meist mit manuellen oder halbautomatisierten Wiederherstellungsprozessen erledigt werden.
Eine hoch verfügbare Lösung muss einen so geringen Overhead haben, dass auch Tier-2- und sogar Tier-3-Anwendungen davon profitieren. Das schützt das Unternehmen, da die Auswirkungen von Ausfällen geringer sind.
Natürlich müssen IT-Verantwortliche auch die Kosten immer im Blick behalten. Neben den Kosten für die Speicherung von zwei Kopien der Daten fallen direkte Kosten für den Schutz der Daten mit einer hochverfügbaren Lösung an: entweder setzt man ein dedizierten High Availability Gateway (HA-Gateway) oder eine Fibre-Channel-Fabric zwischen den Standorten ein, um eine geringe Latenzzeit zu gewährleisten. Die Anschaffung des HA-Gateways (oft nach Kapazität lizenziert) und die laufenden Kosten der FC-Infrastruktur stellen eine Hürde bei der Einführung von Always On-Lösungen dar.
Die Lösung sollte sich auf eine kosteneffiziente Internet Protocol-Infrastruktur stützen und vollständig in die Speicherschicht integriert werden (ohne kapazitätsbasierte Lizenzierung), wenn es darum geht, die Kosten zu minimieren und eine breitere Akzeptanz zu ermöglichen.
Aber auch die Verwaltungsaufwände sind anspruchsvoller und können zum Problem werden, wenn Unternehmen eine stets verfügbare Umgebung schaffen wollen. Wenn dies ein dediziertes Gateway erfordert, erhöht dies die Komplexität der administrativen Prozesse:
- Das Verschieben einer bestehenden LUN in stets verfügbaren Architekturen erfordert oft eine vollständige Datenmigration und Konfigurationsänderungen.
- Verwaltung einer zusätzlichen Schicht im App-Stack, einschließlich Lizenzierung, Überwachung und so weiter.
- Hohe Komplexität der HA-Gateway-Migration
- Datenverwaltungsaufgaben (zum Beispiel Backup & Recovery) werden im HA-Gateway durchgeführt, während Kapazitätsverwaltungsaufgaben im Speicher ausgeführt werden. Dies führt zu einer ineffizienten Verwaltung.
Jede Always-On-Lösung sollte vollständig in die Speicherschicht integriert werden, um den Verwaltungsaufwand zu minimieren.
Eine der größten Herausforderungen beim Aufbau einer Always-On-Dateninfrastruktur sind die so genannten Building Blocks beziehungsweise deren Limits. Die meisten Produkte basieren immer noch auf Dual-Controller-Architekturen, die in den 80er und 90er Jahren entwickelt wurden, als Storage-Arrays für einige Terabyte (TB) entwickelt wurden und sich seitdem nicht viel verändert haben. Sollen nun Hunderte an Petabytes (PB) auf diesen Architekturen laufen, so erhöht dies die Gefahr der Nichtverfügbarkeit von Daten, weil die Architekturen nicht dafür ausgelegt sind.
Generell muss man sagen, dass Disaster-Recovery-Strategien keine Hochverfügbarkeit realisieren können. Sie können die Zeitfenster der Wiederherstellung minimieren, eine ständige Datenverfügung kann mit diesen Technologien aber nicht erreicht werden. Ein RTO von Null lässt sich mit DR nicht gewährleisten.
Always On: Höchste Verfügbarkeit mit Infinidat umsetzen
Das Prinzip des Always On beziehungsweise der Hochverfügbarkeit ist nicht neu. Bereits in den 90er Jahren wurden aktive Failover mittels leistungsstarker, redundanter Hardware umgesetzt, die – je nachdem, wie weit der Failover-Standort vom Rechenzentrum entfernt war – in kürzester Zeit Systeme und Daten wieder verfügbar machten. Allerdings waren diese Installationen enorm aufwändig im Betrieb, in der Administration und natürlich bei den Kosten.
Firmen wie Infinidat versuchen mittels Hardware- und Software-Redundanzen sowie Systemstabilität, höchste Verfügbarkeit zu garantieren und somit Always-On-Strategien ihrer Kunden zu unterstützen.
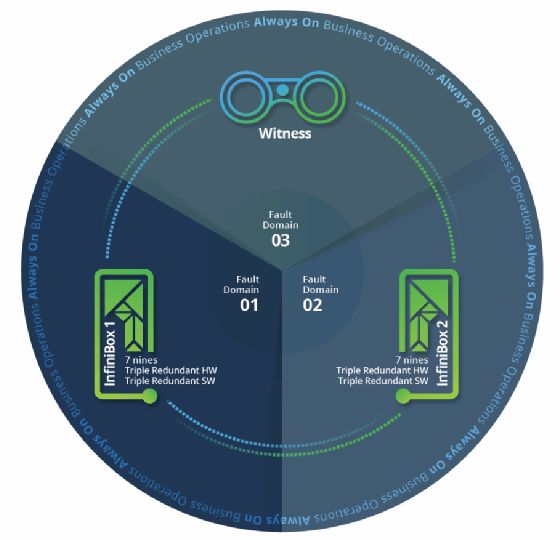
Dafür wurde die InfiniBox-Architektur von als dreifach redundante Lösung konzipiert, die auf die alte Dual-Controller-Architektur verzichtet und laut Hersteller eine Zuverlässigkeit von 99,99999 Prozent bieten soll. Sie besteht aus zwei InfiniBox-Systemen und einem so genannten Witness (Zeugen), der auf einer dritten separaten Domain verteilt ist. Alle Systeme/Domains sind wiederum durch ein redundantes IP-Netzwerk verbunden.
Damit können Unternehmen auf eine Triple-Controller-Architektur wechseln an jedem Standort wechseln, die über einen zusätzlichen Redundanz-Layer verfügt. Diese Architektur gewährleistet höchste Verfügbarkeit, da ein als Failover zwischen den beiden Systemen auf einem einfachen Pfad-Failover basiert, ähnlich dem eines HBA/Switch-Failovers.
Always On ist als integraler Teil der InfiniBox entwickelt worden und benötigt kein separates Gateway. Für bestehende Infinidat-Kunden mit einem aktiven Supportvertrag wird es als kostenloses Software-Upgrade zur Verfügung gestellt.
Das Unternehmen stattet seine Always-On-Lösung mit folgenden Komponenten aus, um die Architektur besonders stabil zu machen:
Fehlerisolation zwischen den InfiniBox-Systemen
Jede InfiniBox in der Architektur verhält sich wie ein eigenständiges Cluster, ohne abhängig von den anderen Systemen zu sein, was größere Auswirkungen und Schäden bei Störfällen verhindert. So kann zum Beispiel ein System einen Ausfall der Stromversorgung und des Netzwerkes erleiden, ohne dass die anderen Systeme auf ein Cluster-Failover warten müssen. Der IT-Betrieb kann innerhalb weniger Sekunden weiterlaufen.
Witness
Der Zeuge oder Witness wird als einfach zu implementierendes OVF (Open Virtualisation Format) mit minimaler Konfiguration bereitgestellt. Der Zeuge kann am Kundenstandort oder in der Cloud eingesetzt werden. Er verhindert Split-Brain-Szenarien und hilft dem InfiniBox-System, schnell zu reagieren, wenn das redundante Netzwerk zwischen beiden ausfällt.
Performance
Um eventuelle Performance-Einbußen zu minimieren, nutzt die InfiniBox sowohl eine direkte Verbindung zum bestgeeigneten Remote-InfiniBox-Controller (um unnötigen Datenverkehr zu vermeiden) als auch ein Pre-Processing der Daten. Das verringert die Reaktionszeit des externen Systems, die die Reaktionszeit des Remotesystems minimiert und die maximale Leistungsstrafe einer AlwaysOn-Lösung verhindert. So umgeht eine solche Architektur die Limitierungen, die eine HA-Lösung (wie oben erwähnt) üblicherweise mit sich bringt.
Infinidat garantiert seinen Kunden hohe Datenverfügbarkeit und definiert eine Datennichtverfügbarkeit als ungeplante Ausfallzeit von mehr als 30 Sekunden. Eine zusätzliche Lizensierung für Always On fällt bei Infinidat nicht an. Bei Problemen konzentriert sich das Unternehmen in seinen Abhilfemaßnahmen auf OPEX, CAPEX und Capacity on Demand, also Kapazitätsbereitstellung bei Bedarf.
Die Zukunftsvision
Der Speicherhersteller hat zudem einen Ausblick auf seine Zukunftsvision gegeben. Hierbei fokussiert sich das Unternehmen darauf, die datenbasierten Wettbewerbsvorteile der Kunden auf Multi-Petabyte-Ebene auszubauen. In diesem Rahmen gab es neben der Always-On-Initiative entsprechende Produktoptimierungen.
Dafür erweitert Infinidat seine Elastic Data Fabric; einige Komponenten sind bereits verfügbar, voraussichtlich erst Mitte 2020. Die Fabric basiert auf den Technologien, die auch dem gesamten Portfolio zugrunde liegen. Ziel ist es, damit eine Struktur bereitzustellen, die eine nahtlose Workload-Mobilität zwischen Systemen, Rechenzentren und Cloud-Speicher unterstützt. Für Infinidat bedeutet dies auch, dass Datenmigrationen eine Methode der Vergangenheit ist.
Zu den Plänen des Unternehmens gehören folgende Produkte:
InfiniVerse ist eine Cloud-basierte, KI-gesteuerte, erweiterte Überwachungs-, Vorhersageanalyse- und Support-Plattform. Sie umfasst anpassbare und zentrale Dashboards für alle InfiniBox-Systeme, egal wo diese sich befinden. Detaillierte Einblicke geben die Möglichkeit, ausgelastete Kapazitäten zu identifizieren, Wachstumsprognosen zu erstellen, die Performance zu modellieren und Konfigurationsprobleme zu identifizieren, die sich auf die Leistung oder Verfügbarkeit auswirken könnten. InfiniVerse ist ohne zusätzliche Kosten erhältlich.
InfiniBox FLX und InfiniGuard FLX sind bereits verfügbar und bieten mehr Flexibilität im Rechenzentrum, indem sie die traditionellen Abhängigkeiten der Hardwareplanung und -verwaltung mittels einem Cloud-ähnlichen Verbrauchsmodell beseitigen. Die All-Inclusive-Abonnements für die lokale Speicherung und Sicherung erlauben eine Abrechnung für die wirklich benötigten und genutzten Ressourcen. Eine Skalierung ist hierbei sowohl nach oben als auch nach unten möglich. Beide Programme sollen 100 Prozent Datenverfügbarkeit garantieren und offerieren alle drei Jahre eine vollständige Aktualisierung der Hardware (Controller und Medien), die in den Abonnementkosten enthalten ist.
InfiniBox Software Release 5, verfügbar ab Q3 2019, enthält eine Reihe von Softwareerweiterungen zur Leistungssteigerung, Network Lock Manager (NLMv4) für NFSv3-Dateisysteme, Active/Active-Replikation für hundertprozentige Datenverfügbarkeit und unterbrechungsfreie Data Mobility für einfache Workload-Verlagerung zwischen zwei beliebigen InfiniBox-Systemen. Zu den Performance-Optimierungen gehören die generelle Reduzierung der Latenzzeit, die Ermöglichung von zwei Millionen IOPS und die Steigerung des Durchsatzes auf bis zu 25 GByte pro Sekunde.
Darüber hinaus gibt es neue InfiniBox-Hardware-Konfigurationsoptionen. Darunter 16 Gb Fibre Channel, 10-Gb-Ethernet sowie 32 Gb FC und 25 GbE als Option. Des weiteren gehören Technologien wie NVMe over Fabrics (NVMe-oF) und Storage Class Memory (SCM) zu den Neuerungen, um eine schnellere Cache-Erweiterung für InfiniBox zu ermöglichen.
Der Hersteller bezeichnet diese künftigen Optimierungen als „Scale to Win“ und möchte damit den Markt in Richtung Hochverfügbarkeitskonzepte treiben.





