
spainter_vfx - stock.adobe.com
Strukturierte und unstrukturierte Daten: Die Unterschiede
Strukturierte und unstrukturierte Daten stellen besondere Anforderungen an die Datenspeicherung. Wir erklären die Unterschiede und den Stellenwert semistrukturierter Daten.

Es gibt zwei Haupttypen von Daten: strukturierte und unstrukturierte. Strukturierte Daten sind in der Regel alphanumerisch, lassen sich anhand gemeinsamer Merkmale von Datenpunkten leicht kategorisieren und eignen sich zur Speicherung in einem vordefinierten Datenmodell, zum Beispiel in einer Datenbank. Bei unstrukturierten Daten handelt es sich in der Regel um etwas anderes als eine alphanumerische Darstellung; sie lassen sich nicht in einen definierten, einheitlichen Rahmen einordnen und werden oft in ihrem eigenen Format gespeichert.
Der Begriff Daten umfasst nahezu alles, was in digitaler Form ausgedrückt oder dargestellt werden kann. Bis zu einem gewissen Grad ist die Art der Daten nicht so wichtig wie der Kontext, in dem sie betrachtet werden, und ihre Beziehungen zu anderen Datenbits. Kontext und Beziehungen helfen dabei, Rohdaten in nützliche Informationen zu verwandeln.
Die Fähigkeit, Daten zu manipulieren, hängt weitgehend davon ab, wie wir Datenelemente klassifizieren, damit wir erkennen können, wie sie sich zu breiteren Datensätzen verhalten und welche Gemeinsamkeiten sie haben. Mit Hilfe der Datenklassifizierung können Daten-Cluster durchsucht werden, um bestimmte Instanzen zu finden, die den Suchkriterien entsprechen.
Um all dies zu erreichen, müssen einheitliche Strukturen geschaffen werden, um Daten auf konsistente Weise zu speichern oder zu definieren - daher der Begriff strukturierte Daten. Der Umgang mit Daten ist jedoch nicht immer einfach, wie jeder bestätigen kann, der schon einmal versucht hat, aus einer großen Datenmenge schlau zu werden. Nicht alle Daten lassen sich definieren und klassifizieren, und das kann zu Problemen führen.
Heutzutage sind Daten in der Regel viel mehr als nur eine alphanumerische Darstellung von etwas. Es kann sich um Video-, Audio- oder Dokumentendateien handeln, um Notizen in sozialen Medien oder um E-Mail-Inhalte. Diese unstrukturierten Datentypen lassen sich nicht in einen definierten Rahmen einordnen und werden immer mehr zu den vorherrschenden Datentypen im Unternehmen.
Um die Sache noch komplizierter zu machen, ist es manchmal notwendig, strukturierte und unstrukturierte Daten zu kombinieren, um die gewünschten Informationen zu erhalten. Dieser hybride Ansatz stellt eine dritte allgemeine Datenart dar, die so genannten semi-strukturierten Daten, die möglicherweise die am schnellsten wachsende aller drei Kategorien ist.
Was sind strukturierte Daten?
Strukturierte Daten sind Daten, die aufgrund ihrer Art und ihres Formats kategorisiert, definiert und in einer konsistenten Struktur gespeichert werden können, zum Beispiel in einem Datenbankmanagementsystem (DBMS).
Die einzelnen Datenelemente strukturierter Daten können so konstruiert werden, dass sie Standardbedingungen entsprechen, wie beispielsweise:
- Sie bestehen aus Text, numerischen oder alphanumerischen Daten.
- Die Anzahl der Zeichen, aus denen das Element besteht.
- Die Art der Datenelemente, die es ermöglicht, sie auf der Grundlage ähnlicher oder gleichartiger Werte logisch zu gruppieren.
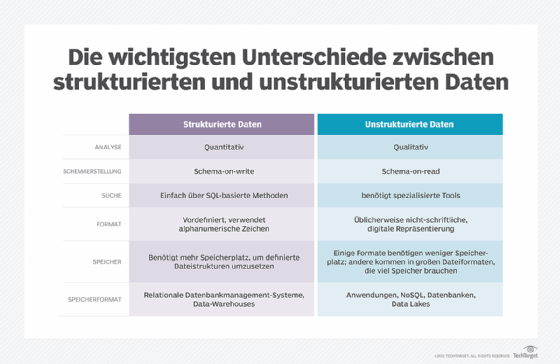
Die Platzierung von Daten in strukturierten Umgebungen wird manchmal als Schema-on-Write bezeichnet, was bedeutet, dass Daten neu in speziell definierte Slots in einem Datenspeicher geschrieben oder dorthin verschoben werden. Die Definitionen sind in der Regel eng gefasst, um sicherzustellen, dass nur ähnliche Daten an die entsprechende Stelle im Schema geschrieben werden.
So kann beispielsweise ein Postleitzahlenfeld als numerisch und fünf Zeichen lang definiert werden, wodurch verhindert wird, dass Daten, die diese beiden Kriterien nicht erfüllen, in diese Struktur geschrieben werden. Zusätzliche Sicherheitsvorkehrungen gegen falsche Daten können durch die Anwendung von Filtern getroffen werden, die einen geeigneten Eintrag weiter spezifizieren, wie zum Beispiel die Sperrung eines Bereichs von Postleitzahlen, die mit „900“ beginnen.
Eine weitere Möglichkeit, um sicherzustellen, dass die Einträge einem einheitlichen Format entsprechen, besteht darin, eine Vorlage für die Einträge bereitzustellen. Die Vorlage sorgt dafür, dass jeder Eintrag in einem einheitlichen Format erscheint, das die Suche erleichtert. Eine Vorlage für Sozialversicherungsnummern kann beispielsweise dazu führen, dass die Einträge in diesem Format erfolgen: ###-##-####.
Die Möglichkeit, Daten auf diese Weise zu gruppieren, erleichtert die Suche nach bestimmten Daten, da die Daten in einem einheitlichen Format gespeichert sind. Eine Adressdatenbank kann die folgenden standardmäßig definierten Felder enthalten:
- Vor- und Nachname
- Straßenanschrift
- Stadt
- Bundesland
- Postleitzahl
Um nur die Einwohner von Braunschweig in der Datenbank zu finden und zu extrahieren, könnten Sie im Postleitzahlenfeld nach allen Einträgen suchen, die mit „381“ beginnen.
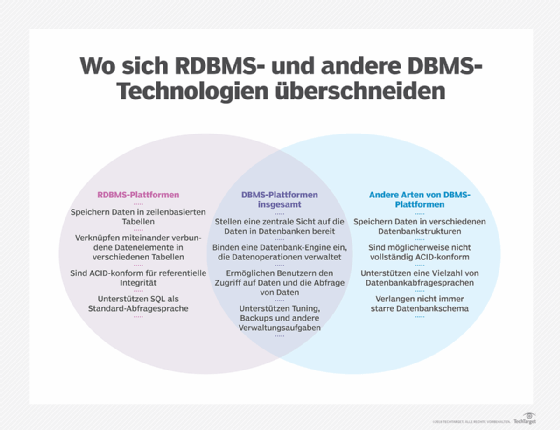
Für anspruchsvollere Datenmanipulationen ermöglicht ein relationales DBMS (RDBMS) die Einrichtung von Beziehungen zwischen zwei oder mehr verschiedenen Datensätzen mit größtenteils ungleichen Daten. Die verschiedenen Datensätze innerhalb einer relationalen Datenbank werden als Tabellen bezeichnet; innerhalb der Tabellen befinden sich Sammlungen von Daten, die in Spalten (Feldern) und Zeilen (Datensätzen oder Dateneinträgen) angeordnet sind.
Durch die Verknüpfung einer gleichartigen Spalte oder eines gleichartigen Feldes, die in beiden Tabellen vorkommen, können die Daten effektiv kombiniert werden, um noch mehr Informationen zu erhalten.
Wenn zum Beispiel die Adressdatenbank eine Tabelle ist und eine zweite Tabelle eine Liste von Studenten mit ihren Studienschwerpunkten und Heimatstädten, kann ein neuer Datensatz extrahiert werden, der die Verteilung der Studienschwerpunkte in einem bestimmten Bundesland zeigt.
SQL erleichtert die Extraktion und Zusammenstellung von Daten aus einer Gruppe von Tabellen. Mit SQL wurde ein Standardbefehlssatz für den Zugriff auf Daten und deren Suche und Zusammenstellung in sinnvoller Form eingeführt.
In einigen Fällen können relationale oder nichtrelationale Datenbanken eine Spalte enthalten, die auf ein unstrukturiertes Datenelement verweist, zum Beispiel eine Videodatei. Dieses unstrukturierte Datenelement wird als BLOB (Binary Large Object) bezeichnet.
In den meisten Fällen ist das BLOB mit den anderen Informationen in der Datenzeile verknüpft, so dass es durch die Suche in anderen Datenelementen innerhalb des Datensatzes gefunden werden kann. Das BLOB selbst ist in der Regel nicht durchsuchbar, außer möglicherweise anhand seines Namens oder Datentyps, beispielsweise mit MP4, MOV oder WMV für Videodateien.
Was sind unstrukturierte Daten?
Wie bereits erwähnt, umfassen unstrukturierte Daten Dinge wie Video-, Audio- und Dokumentdateien, Beiträge in sozialen Medien und E-Mail-Inhalte. Sie lassen sich nicht einfach standardisieren und kategorisieren. Sie ähneln oft eher Datensammlungen als diskreten Datenelementen, zum Beispiel einem Dokument, das Hunderte oder Tausende von Wörtern umfasst und viele verschiedene Themen behandelt.
Im besten Fall ist es schwierig, den Inhalt des Dokuments als eine einzige Einheit zu definieren, und Tools für strukturierte Daten bieten keine Mechanismen zum Parsen des Dokuments, um eine Kategorisierung der darin enthaltenen Daten zu ermöglichen.
Neue Datenquellen wie IoT-Sensoren, Satellitenbilder, von Drohnen erfasste Daten, Sicherheitskameras und Sprachaufzeichnungssysteme erzeugen täglich enorme Mengen an unstrukturierten Daten.
Unstrukturierte Daten können zwar verwaltet werden, werden aber in der Regel als Objekt in ihrem ursprünglichen, rohen Format gespeichert und erst bei Bedarf bearbeitet. Dieser Prozess wird als Schema-on-Read bezeichnet, was sich auf einen Ansatz zur Datenanalyse bezieht, der in neueren Datenverwaltungs-Tools wie Hadoop verwendet wird und den Daten beim Lesen eine Struktur zuweist.
Metadaten werden verwendet, um unstrukturierte Daten zu kategorisieren. Die Metadaten begleiten das Objekt und liefern eine begrenzte Menge an Standardinformationen, die als Such- und Sortierkriterien verwendet werden können. Im Allgemeinen beschränken sich die Metadaten jedoch auf grundlegende Informationen über die Datei, wie zum Beispiel das Erstellungs- und Änderungsdatum, die Größe und den Dateityp.
Es gibt auch Tools, die unstrukturierte Daten, beispielsweise Audio- oder Videodateien, scannen und Informationen wie Orte oder gesprochene Sätze extrahieren können, die als zusätzliche Metadaten verwendet werden können. In ähnlicher Weise können Technologien wie XML (Extensible Markup Language) Textdateien eine gewisse Struktur verleihen.
Obwohl es schwierig ist, spezifische Informationen aus unstrukturierten Daten zu extrahieren oder zuzuordnen, werden dringend Methoden dafür benötigt. Man schätzt, dass 80 Prozent der Daten, die Unternehmen erstellen oder sammeln, unstrukturiert sind. Neue Datenquellen wie IoT-Sensoren, Satellitenbilder, von Drohnen erfasste Daten, Sicherheitskameras und Sprachaufzeichnungssysteme produzieren täglich enorme Mengen an unstrukturierten Daten. Diese riesigen Mengen überfordern die Speichersysteme, weshalb viele Unternehmen ihre unstrukturierten Daten in Cloud-Speicherdiensten speichern.

Semistrukturierte Daten
Wie der Name schon sagt, handelt es sich bei semistrukturierten Daten um einen Datenbestand, der sowohl strukturierte als auch unstrukturierte Daten enthält, oder, was wahrscheinlicher ist, um unstrukturierte Daten, denen eine gewisse Struktur hinzugefügt wurde, um sie leichter zugänglich zu machen.
In einer einfachen Form können semistrukturierte Daten eine Videodatei sein, die von strukturierten Daten begleitet wird, die der Datei eine genauere Definition geben, zum Beispiel Themen, Ort, Datum, Teilnehmer, Länge und Format. Jede dieser Informationen kann dann verwendet werden, um bestimmte Videos zu lokalisieren oder zu gruppieren.
Strukturierte vs. unstrukturierte Daten: Die wichtigsten Unterschiede
Die Unterschiede zwischen strukturierten und unstrukturierten Daten sind tiefgreifend, aber beide Arten liefern wichtige Informationen für Unternehmen. Wie bereits erwähnt, gibt es bei unstrukturierten Daten eine weitaus größere Vielfalt, und die Analyse-Tools, die zur Bearbeitung unstrukturierter Daten verwendet werden, sind wahrscheinlich neuer und liefern Informationen, die weniger wörtlich sind als die Systeme, die strukturierte Daten verarbeiten.
Ein Supermarkt kann zum Beispiel eine relationale Datenbank verwenden, um die Einkäufe eines Kunden mit dessen Treueprogramm-ID zu verknüpfen und so Coupons für Artikel zu erstellen, die der Kunde laut den Daten wahrscheinlich kaufen wird. Eine Analyse unstrukturierter Daten in einer Einzelhandelsumgebung könnte Videodaten verwenden, die aufzeichnen, welche Gänge ein Kunde besucht und wie lange er in bestimmten Bereichen verweilt, sowie die Reihenfolge der Bewegungen. Auf der Grundlage der gesammelten Informationen kann das System dann sofort einen Gutschein für Milch ausstellen, nachdem ein Kunde den Kaffeegang passiert hat und sich dem Milchregal nähert.
Bedeutung von strukturierten vs. unstrukturierten Daten
Strukturierte Daten liefern in der Regel quantitative Informationen, während unstrukturierte Daten eher qualitative Informationen liefern. Natürlich sind beide Arten der Datenanalyse wichtig, auch wenn nicht alle Unternehmen beide benötigen.
Im Hinblick auf neuere Datenanalyse- und -manipulationstechnologien eignen sich strukturierte Daten beispielsweise gut für die KI-Verarbeitung, zum Beispiel das maschinelle Lernen.
Big Data und Big-Data-Analytik oder Data-Mining-Verarbeitung erfordern große Datenmengen, und auch hier werden strukturierte Daten bevorzugt. Angesichts der riesigen Menge an unstrukturierten Daten, die heute gesammelt werden, spielen diese jedoch auch in Big-Data-Umgebungen eine Rolle.







