So optimieren Sie Storage für KI und Machine/Deep Learning
Speicher für KI müssen Anforderungen an die Datenformate, an Scale-Out oder an Bandbreite und Latenzen erfüllen. Bewährte Speicheranbieter haben dafür Angebote in ihren Programmen.
Die Neubelebung von Artificial Intelligence beziehungsweise künstlicher Intelligenz (AI/KI) infolge von Machine Learning und Deep Learning hat eine Explosion bei Forschung und Produktentwicklung erzeugt, da Unternehmen kreative Methoden entdecken, um diese neuen Algorithmen für Prozessautomatisierung und vorausschauende Erkenntnisse anzuwenden. Die Natur von Modellen für Machine Learning und Deep Learning, wobei letzteres oft die neuronalen Strukturen und Verbindungen des Gehirns nachbildet, erfordern den Erwerb, die Aufbereitung, das Verschieben und die Entwicklung von massiven Datengruppen.
Besonders Modelle für Deep Learning brauchen große Datensätze. Und Speicher für KI im Allgemeinen und Deep Learning im Besonderen steht vor einzigartigen Herausforderungen. Ein kurzer Exkurs in die Natur von Software für Machine Learning und Deep Learning zeigt auf, warum Storage-Systeme so ausschlaggebend für diese Algorithmen sind, um zeitgerechte und genaue Ergebnisse zu liefern.
Warum Storage für KI und Deep Learning wichtig ist
Viele Forscher haben gezeigt, dass die Genauigkeit von Modellen für Deep Learning sich mit größeren Datensets verbessert. Die Verbesserung ist so bedeutsam, dass die Forscher oft verfeinerte Techniken zur Datenvermehrung benutzen, um synthetisch eigene Daten für das Training der Modelle zu erzeugen.
Zum Beispiel enthält ein Datensatz von ImageNet, der für das Benchmarking verschiedener Bilderklassifikationsalgorithmen von Deep Learning genutzt wird, mehr als 14 Millionen Bilder mit Millionen von Anmerkungen – während das ResNet-50-Modell, das oft zum Benchmarking von Hardware für Bilderklassifizierung eingesetzt wird, gerade mal eine Größe von 100 Megabyte besitzt. Die Modelle, die idealerweise im Memory vorgehalten werden, müssen kontinuierlich mit Daten gefüttert werden, was oft dazu führt, dass das Speichersystem zum Engpass der gesamten Performance wird.
Ungeachtet des jeweiligen Modells und der Anwendung besteht Deep Learning aus zwei Schritten: Modelltraining und Datendeduktion. Training findet dort statt, wo die Parameter der Modelle auf Basis von wiederholten, oft rekursiven Berechnungen kalkuliert und optimiert werden, wobei ein Übungsdatensatz berechnet wird. Deduktion findet dort statt, wo das Trainingsmodell auf neu hereinkommenden Daten beruht, aus denen Klassifikationen und Voraussagen abgeleitet werden.
Das Design von Speichersystemen für Deep Learning muss eine ausgeglichene Performance über eine Bandbreite von Datentypen und Deep-Learning-Modellen zur Verfügung stellen.
Jeder Schritt kann die Systeme, die Storage für AI und Deep Learning zur Verfügung stellen, auf unterschiedliche Art belasten. Beim Training erfolgt die Belastung sowohl wegen der großen Datensätze als auch der schnellen I/O-Prozesse auf der Computing-Seite – oft ein verteilter Cluster –, die wegen einer akzeptablen Performance erforderlich sind. Bei den Deduktionen erfolgt die Belastung wegen der Echtzeitnatur der Daten, die mit minimalen Latenzen abgewickelt werden müssen.
Anforderungen der Storage-Performance beim Deep Learning
Deep-Learning-Algorithmen benutzen enorme Mengen an mathematischen Grundmustern, mit denen sie gut zur Ausführung auf GPUs geeignet sind, die ursprünglich für Tausende von simultanen Floating-Point-Berechnungen bei Pixeldaten entwickelt worden waren. Anders als Computergrafiken erfordern neuronale Netzwerke und andere Modelle für Deep Learning keine hochpräzisen Floating-Point-Resultate. Sie werden im Allgemeinen durch eine neue Generation von AI-optimierten GPUs und CPUs weiterbewegt, die 8- und 16-Bit-Matrixberechnungen mit niedriger Präzision unterstützen – eine Optimierung, die Storage-Systeme sogar in noch größere Performance-Engpässe verwandeln kann.
Die Unterschiedlichkeit von Deep-Learning-Modellen und Datenquellen bedeutet zusammen mit den Entwürfen für verteiltes Computing, die für Deep-Learning-Server verwendet werden, dass Systeme, die für KI-Storage entwickelt wurden, die folgenden Komponenten berücksichtigen müssen:
Eine große Bandbreite an Datenformaten, einschließlich solcher für Binary Large Object Data (BLOB), Bilder, Video, Audio, Text und strukturierter Daten, die alle verschiedene Formate und I/O-Besonderheiten besitzen.
Eine Scale-Out Systemarchitektur, mit der Workloads über viele Systeme hinweg verteilt sind – in der Regel vier bis 16 Systeme für Trainingszwecke und potentiell hunderte oder tausende für Deduktionen.
Bandbreite und Durchsatz, die schnell massive Mengen an Daten zu Computing-Hardware weiterleiten können.
IOPS, die hohen Durchsatz ungeachtet der jeweiligen Datenbesonderheiten aushalten können – für sowohl viele kleine Transaktionen als auch seltenere große Transfers.
Latenzen, um Daten mit minimaler Verzögerung zu liefern, da mit virtuellem Memory Paging die Performance von Trainingsalgorithmen sich signifikant verschlechtern kann, wenn GPUs auf neue Daten warten müssen.
Das Design von Speichersystemen für Deep Learning muss eine ausgeglichene Performance über eine Bandbreite von Datentypen und Deep-Learning-Modellen zur Verfügung stellen. Laut Nvidia ist es wichtig, die Performance von Speichersystemen für sehr viele Load-Bedingungen zu prüfen: „Die Komplexität von Workloads und die Datenmengen, die zur Unterstützung von Deep-Learning-Trainingsprozessen erforderlich sind, sorgen für eine kritische Performance-Umgebung. (...) Wegen ihrer Komplexität ist es eine wesentliche Voraussetzung für das Funktionieren dieser Umgebungen, grundlegende Performance-Daten zu sammeln, bevor man in die Produktion geht. Man muss überprüfen, ob das Kernsystem aus Hardwarekomponenten und Betriebssystem auch die erwartete Performance unter synthetischen Load-Bedingungen liefern kann.“
Wesentliche Features von Storage-Systemen für Deep Learning
Die oben beschriebenen Performance-Komponenten haben die Hersteller von Speichersystemen für KI dazu gebracht, fünf wesentliche Features einzuführen. Diese bestehen aus:
Ein parallelisiertes Scale-Out System-Design, das inkrementell erweitert werden kann und bei dem die I/O-Performance mit der Kapazität anwächst. Ein Kennzeichen eines solchen Designs ist eine verteilte Speicherarchitektur oder ein File-System, das logische Elemente wie Objekte und Dateien von dem physischen Gerät oder den physischen Geräten entkoppelt, die sie aufnehmen.
Eine programmierbare, softwaredefinierte Control Plane, die entscheidend für die Erstellung eines Scale-Out Designs ist und die die Automatisierung der meisten Managementaufgaben ermöglicht.
Zuverlässigkeit, Dauerhaftigkeit, Redundanz und Storage-Dienste auf Unternehmensniveau.
Eine eng miteinander verbundene Systemarchitektur von Compute und Storage für Training-Systeme von Deep Learning auf der Basis eines nicht blockierenden Netzwerkdesigns, um Server und Storage miteinander zu verbinden. Dabei sollte eine minimale Geschwindigkeit von 10 GbE bis zu 25b Gb Ethernet oder von EDR (25 Gbps) InfiniBand vorhanden sein.
SSD-Systeme, die zunehmend schnellere NVMe-Geräte verwenden, die einen höheren Durchsatz und IOPS als SATA
DAS-Systeme verwenden in der Regel NVMe-over-PCIe-Geräte.
NAS-Designs verwenden in der Regel 10 Gb Ethernet oder schneller, mit NVMe over Fabric, InfiniBand oder mit PCIe-Fabric-Switches.
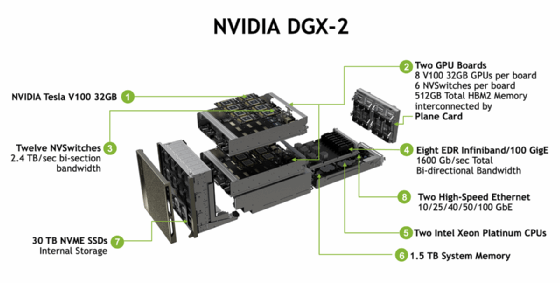
Abbildung 1: Nvidia DGX-2 bietet eine High-Performance-Architektur für Depp Learning.
Maßgeschneiderte Storage-Produkte
KI ist derzeit eine „heiße“ Technologie, und die Hersteller haben den Markt schnell mit einer Mischung aus neuen und modernisierten Produkten überschüttet, um dem Bedürfnis nach KI-Workloads zu entsprechen. Angesichts dieser Marktdynamik wollen wir erst gar nicht versuchen, hier eine umfassende Übersicht über jene Produkte vorzulegen, die speziell für KI-Storage herausgekommen sind. Stattdessen hier ein paar Beispiele:
Dell EMC Ready Solutions for AI gibt es mit Bundles für Rack-Skalierung, die Server, Speicher, Edge Switch und einen Management-Knoten zusammenpacken. Als Speicher wird ein Isilon H600 oder F800 All-Flash Scale-Out NAS mit 40-GbE-Netzwerkverbindungen verwendet.
DDN A3I benutzt AI200 oder AI400 NVMe All-Flash Arrays (AFA) mit bis zu 360 TByte Kapazität und entsprechend 750K und 1,5M IOPS und vier oder acht 100-GbE- oder EDR-InfiniBand-Schnittstellen. Alternativ gibt es die DDN AI7990 hybride Speicher-Appliance mit 5,4 Petabyte Kapazität, 750K IOPS und vier 100-GbE- oder EDR-InfiniBand-Schnittstellen. Bei DDN gibt es auch Bundles der Produkte mit Nvidia DGX-1 GPU-beschleunigten Servern und Hewlett Packard Enterprise Apollo 6500 beschleunigten Servern.
IBM Elastic Storage Server AFA gibt es in einer Bandbreite von SSD-basierten Konfigurationen, die eine nutzbare Kapazität bis zu 1,1 Petabyte liefern. IBM verfügt auch über eine Referenz-Systemarchitektur, die Elastic Storage Server mit Power-System-Servern und dem Software-Stack PowerAI Enterprise verbindet.
NetApp OnTap AI Referenzarchitektur kombiniert DGX-1-Server von Nvidia mit NetApp AFA A800-Systemen und zwei Nexus-3K-100-GbE-Switches von Cisco. Die A800 kann 1M IOPS mit Latenzen unter einer halben Millisekunde liefern, und ihr Scale-Out Design stellt mehr als 11M IOPS in einem Cluster mit 24 Knoten zur Verfügung.
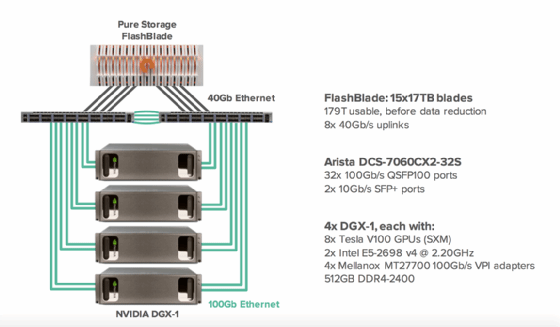
Pure Storage AIRI ist ein weiteres integriertes System auf Basis von DGX-1, das das FlashBlade AFA-System für File- und Object-Storage einsetzt. Referenzsysteme sind mit Arista-, Cisco- und Mellanox-Switches erhältlich. Ein Arista-Design benutzt zum Beispiel 15 17-TB-FlashBlades mit acht 40-GbE-Links zu einem 100-GbE-Switch von Arista mit 32 Ports.
Abbildung 2: Die System-Architektur von Pure Storage AIRI im Überblick.
Deduktionssysteme für Deep Learning sind weniger anspruchsvoll in Sachen Storage-Subsysteme und werden in der Regel durch lokale SSDs in einem x86-Server abgedeckt. Obwohl Deduktionsplattformen im Allgemeinen aus konventionellen 1U- und 2U-Server-Designs mit lokalen SSD- und NVMe-Einschüben bestehen, umfassen sie zunehmend Compute Accelerators wie die Nvidia T4 GPU oder eine FPGA, die einige Deep-Learning-Prozesse auf Hardwarebasis abarbeiten.