
Sergey Nivens - stock.adobe.com
Optimale Architekturen für intelligente Storage-Systeme
Intelligente Algorithmen optimieren die Datenplatzierung auf dem Storage-Device und das Tiering, die Verteilung zwischen On-Premises und Public Cloud und steigern die Sicherheit.

Meistens veränderte sich Storage bislang im Hau-Ruck-Verfahren, wenn höhere Leistungen erreicht werden sollten. Storage-Systeme einfach größer, schneller oder dichter zu gestalten, hat meistens gut funktioniert und wird wohl auch weiterhin dazu beitragen, die Leistung von Storage-Lösungen zu verbessern.
Allerdings ist dieser Weg nicht mehr der beste für Kosten- und Leistungssteigerungen. Stattdessen spielen Maschinenlernen (Machine Learning, ML) und Analytics, die als Intelligenz in Storage-Systeme integriert sind, nun die Rolle des Fortschrittsmotors der Speichertechnologie.
Was ist ein intelligentes Storage-System?
Die Vorläuferlösungen intelligenter Storage-Systeme optimieren systemnahe Funktionen wie das Lesen von einer SSD oder die Versendung von Datenpaketen an eine Netzwerkschnittstelle. Intelligente Storage-Systeme optimieren auf einer höheren Abstraktionsebene. Sie verwenden dazu Betriebsdaten der Systeme, um die Leistung innerhalb des Systems zu verbessern und beobachten Datennutzungsmuster, um Systemoperationen zu optimieren,
Die Intelligenz wird auf drei unterschiedlichen Ebenen in die Speichersysteme integriert: Auf Device-Ebene, auf der Ebene der Storage Tiers sowie beim Lebenszyklusmanagement und schließlich in Form beschleunigter Zugriffsmechanismen.
Auf Geräteebene identifizieren ML-Algorithmen Datenkategorien mit ähnlichen Zugriffsmustern. Wenn ein ML-Modell prognostiziert, dass eine Reihe von Datenblocks demnächst wahrscheinlich gelesen werden wird, dann werden diese Blocks zuvor in einen Cache kopiert.
Das verringert die Latenz, wovon besonders datenintensive Anwendungen wie das Training von ML-Modellen profitieren. Sie brauchen große Datenmengen, die schnell genug bereitgestellt werden müssen, um mit der Geschwindigkeit der GPUs und anderer Beschleuniger mitzuhalten.
Storage-Tiering und Lebenszyklusmanagement
Storage-Tiering und das Lebenszyklusmanagement der Daten (Data Lifecycle Management, DLM) fokussieren sich auf größere Datenmengen als das bei Optimierungen auf Geräteebene ist. Letztere betreffen die bessere Platzierung von Daten, die demnächst gebraucht werden und überwachen die Systeme auf mögliche Ausfälle. Erstere kümmern sich um die bessere Platzierung von Daten auf dem Medium für die langfristige Speicherung. Zum Beispiel gehen solche Algorithmen zutreffend davon aus, dass eine kürzlich generierte Zeitreihe wahrscheinlicher bald wieder abgefragt wird als eine ältere Zeitreihe.
Ein Algorithmus für die intelligente Auswahl der geeigneten Speicherschicht detektiert unterschiedliche Zugriffsmuster. Dann platziert er Daten, auf die wahrscheinlich eher zugegriffen wird, auf Storage mit geringerer Latenz und höheren Kosten. Die übrigen Daten landen auf einer kostengünstigeren Storage-Plattform.
Suche in komplexen Datenbeständen
Mit dem Wachstum der Datenmenge und immer vielfältigeren Datenformaten wird es immer schwieriger, spezifische Daten zu finden. Natürlich ist es einfach, eine Datei mit einem bestimmten Namen zu finden oder eine Reihe von Archivdateien, die zu einem bestimmten Zeitpunkt erstellt wurden, wiederherzustellen.
Aber nicht immer sind die Zugriffsnotwendigkeiten so einfach gestaltet. Beispielsweise kritisieren Ingenieure die Leistung intelligenter ML-Modelle in der Produktion, weil diese nicht auf einem breit genug angelegten Datensatz trainiert wurden.
Sie würden Storage-Systeme gern nach Daten mit spezifischen Eigenschaften durchsuchen. Dazu braucht man aber Mechanismen wie intelligente Indexierung, intelligentes Tagging und intelligentes Retrieval.
Die Algorithmen intelligenter Storage-Systeme
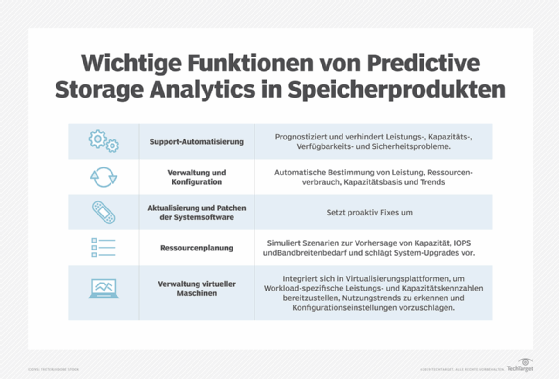
Die Intelligenz lebender Organismen hat sich während der Evolution unterschiedlich entwickelt. Dasselbe gilt auch für intelligente Storage-Systeme. Einige der verbreitetsten Funktionen intelligenter Storage-Systeme sind die Nutzung von vorausschauender (prädikativer) Analytik, verteiltes (Distributed) Storage und Verarbeitung, optimale Datenplatzierung und erhöhte Sicherheit.
Beispiel Predictive Analytics: Hier handelt es sich im Wesentlichen um statistische und ML-Verfahren. Sie erkennen beim Umgang der Systeme mit Daten Muster. Die verwenden sie dann, um zu prognostizieren, wie auf die im System gespeicherten Daten anschließend zugegriffen wird.
Bei Optimierungen auf Geräteebene basieren die Analysen auf I/O-Trace-Logs. Sie speichern jede Operation auf einem Gerät. Statistische Techniken müssen nicht wissen, was die Daten bedeuten, ob sie durch eine Vertriebstransaktion oder einen Fahrzeugsensor generiert wurden. Worauf es ankommt, sind ihre Storage-Charakteristiken: Wo sind sie gespeichert und wann wurden sie geschrieben? Meist werden für solche Aufgaben Clustering-Algorithmen verwendet.
Systemübergreifende Optimierungsalgorithmen
Intelligente Storage-Systeme können sich über mehrere Geräte erstrecken. Ein IoT-Sensor kann zum Beispiel Daten an ein Edge-Device senden, damit sie dort gespeichert und weiter analysiert werden. Das Edge-Device kann eine erste Analyse durchführen, um festzustellen, welche Daten lokal gespeichert und welche an die zentralen Analysesysteme gesendet werden sollten.
Eine auffällige Messreihe von einem Sensor kann zum Beispiel auf ein Problem hinweisen, das sofort gelöst werden muss. Solche Daten werden sofort an die nächste Stufe des Ingest-Prozesses gesendet. Andere Daten werden einfach gespeichert und in Chargen später an die Zentrale geschickt.

Intelligente Systeme können auch Daten auf mehreren Storage-Schichten managen. Aktuelle Zeitserien werden sehr viel wahrscheinlicher nachgefragt als ältere Daten. Deshalb sollten sie auf Storage mit kurzer Latenz landen.
Ältere Daten können dagegen auf weniger leistungsfähige Storage Tiers verschoben werden, die mehr Latenz haben, aber auch weniger kosten. Diese Art von Lebenszyklusmanagement muss automatisiert funktionieren. Denn die Menge und die Art der Daten, die auf diese Weise verwaltet werden, eignen sich nicht für die manuelle Verarbeitung. Am besten definieren die Administratoren abstrahierte Regeln für das Lebenszyklusmanagement. Allerdings braucht man dafür auch intelligente Storage-Systeme, mit denen sich solche Regeln über viele Datensätze und Anwendungsfälle hinweg implementieren lassen.
Musteranalyse steigert die Sicherheit
Intelligentes Storage kann auch für mehr Sicherheit sorgen. Die CPU-Nutzungsmuster, IOPS oder andere häufig überwachte Parameter von Anwendungen und Diensten folgen oft charakteristischen Mustern. Verändern sich diese gegenüber dem Normalzustand, was nicht unüblich ist, kann das ein Hinweis auf ein Sicherheitsproblem sein.
IT-Administratoren müssen daher intelligente Storage-Systeme so anlernen, dass sie diejenigen Variationen bemerken, die auf einen bevorstehenden Ausfall, einen Sicherheitszwischenfall oder eine andere Bedrohung für den Betrieb hinweisen. Zum Beispiel können ML-Ingenieure Leistungsdaten sammeln, die während kontrollierter Ransomware-Angriffe generiert wurden. Damit lassen sich Modelle bauen, die erkennen, wenn ein entsprechender Angriff stattfindet.
Die beschriebenen Funktionen, etwa die optimierte Platzierung der Daten auf dem Storage-System, sind aufgabenspezifisch. In der Praxis allerdings implementieren Organisationen sie übergreifend über eine Reihe von Komponenten der Infrastruktur hinweg. Deshalb ist es wichtig, die Gesamtarchitektur eines intelligenten Storage-Systems zu verstehen.
Die Architektur intelligenter Storage-Systeme
Storage-Systeme, intelligent oder nicht, sind ein Teil einer größeren Infrastruktur. Zu ihr gehören neben den Speichergeräten auch Server und Netze. Intelligente Storage-Systeme haben vier Kernkomponenten: ein Frontend, einen Cache, ein Backend und einen dauerhaften Datenspeicher wie Festplatte oder SSD.

Die wichtigste Aufgabe des Frontends ist es, mit dem Netzwerk des Storage-Systems zu kommunizieren. Frontends haben Ports und Controller. Über die Ports verbinden sich Host-Server mit dem Storage-System.
Ports unterstützen Transportprotokolle wie SCSI und Fibre Channel. Frontend-Controller routen die Daten in den und aus dem Cache. Sie sind außerdem für die Optimierung der Ein-/Ausgabevorgänge (I/Os) zuständig. Das geschieht normalerweise mit Hilfe von intelligenten Befehlspipeline-Algorithmen. Sie optimieren die Reihenfolge, in der I/O-Befehle abgearbeitet werden.
Cache ist Speicher mit geringer Latenz. Man verwendet ihn, um die für Ein-/Ausgabeoperationen benötigte Zeit zu verkürzen. Ausschlaggebend ist dabei die Perspektive der Applikation oder des Dienstes, welche das Storage-System nutzen. Caches speichern sowohl Daten als auch Informationen darüber, wo sich die Daten im Cache oder auf der Disk befinden.
Caching-Strategien
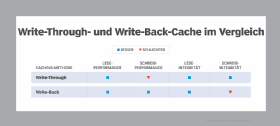
Es gibt verschiedene Strategien, um die Daten im Cache zu verwalten. Welche benutzt wird, hängt davon ab, welcher Aspekt der Ein-/Ausgabeoperationen optimiert werden soll. Bei einem Write-Back-Cache etwa schreibt das System die Daten in den Cache und anschließend wird eine Bestätigung an die Applikation geschickt.
Erst nach deren Absendung schreibt das System die Daten auf die Disk. Das minimiert die Zeit, in der die Applikation auf eine Bestätigung warten muss. Das Risiko besteht darin, die Daten zu verlieren, wenn der Cache ausfällt, bevor die Daten auf der Disk gelandet sind. Die Write-Through-Strategie dagegen bedeutet, dass die Daten in den Cache und auch unmittelbar auf die Disk geschrieben werden. Das Risiko, Daten zu verlieren, ist hier geringer, aber die Latenz höher.
Das Backend ist die Schnittstelle zwischen Cache und persistentem Speicher, also HDDs oder SSDs. Wie das Frontend besteht auch das Backend aus Ports und Controllern. Disks werden an Ports angebunden und die Controller sind für die Lese- und Schreiboperationen auf die Disks zuständig. Intelligenz im Backend umfasst daher auch Fehlererkennung und -korrektur.
Intelligenz ist wichtig, um Operationen im Storage-System zu optimieren und so insgesamt die Storage- und Compute-Operationen optimal zu betreiben. Gleichzeitig sollte man Speicher auch im größeren Kontext der gesamten vorhandenen Infrastruktur betrachten. Heute gehört dazu On-Premises- und Cloud-Infrastruktur.
Intelligente Storage in Hybrid-Cloud-Infrastrukturen
Potentiell nutzt Intelligenz beim Storage-Management am meisten, wenn sie dafür verwendet wird, den Speicher für bestimmte Workloads und Applikationen und in einer hybriden Cloud-Infrastruktur zu optimieren.
Anwendungen hängen essentiell von Datenbanken ab, die ihre strukturierten Daten verwalten. Datenorientierte Systeme können Daten über Operationen auf Applikationsebene verwenden, um die Storage-Leistung dieser Datenbanken zu steigern. Zum Beispiel kann ein datenorientiertes System Daten, die ein Datenbankmanagementsystem erzeugt hat, verwenden, um vorherzusehen, welche Daten demnächst wieder gebraucht werden. Aber Applikationen und Datenbanken werden selten für sich allein verwendet. Meist sind sie Teil umfangreicherer Arbeitsprozesse.
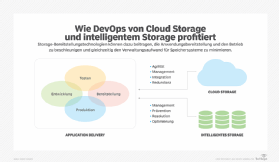
Die leistungsfähigsten Formen von intelligentem Speicher können Workloads überwachen und das Storage mehrerer Storage-Geräte optimieren. Dafür verwenden solche Lösungen Informationen von Servern, Netzwerken und Speichersystemen. Dieser Grad an Intelligenz kann dazu beitragen, die Cloud-Storage-Kosten zu kontrollieren. Sie sind oft schwer zu managen und verändern sich häufig unerwartet.
Fazit
Die Verbesserung der Storage-Leistung und mehr Kosteneffizienz hängen also heute nicht mehr von verbesserter Hardware ab. Der wichtigste Treiber von Fortschritten ist aktuell die intelligente Software. Sie optimiert alles: von den hardwarenahen I/O-Vorgängen auf einem einzelnen Gerät bis hin zur Überwachung von Workloads oder der Datenplatzierung in einer Hybrid-Cloud-Infrastruktur.
Erfahren Sie mehr über Storage Management
-
![]()
Leistung optimieren: Vier Tipps für virtualisierten Speicher
Von: Ulrike Rieß-Marchive
-
![]()
Exagrid: skalierbare Backup-Lösungen für Unternehmen
Von: Tobias Servaty-Wendehost
-
![]()
Künstliche Intelligenz für das Storage-Management nutzen
Von: Brien Posey
-
![]()
Storage für KI: Was bei der Wahl wichtig ist
Von: Bridget Botelho



