
BillionPhotos.com - stock.adobe.
NLP und KI treiben automatisiertes Data Warehouse voran
Moderne Data Warehouses automatisieren so viele Elemente wie möglich. Features wie Augmented Analytics und Natural Language Processing optimieren die Prozesse.

Im Zuge der Digitalisierung automatisieren Unternehmen auch Elemente ihrer Data Warehouses. Sie nutzen vor allem künstliche Intelligenz (KI) und maschinelles Lernen, um Daten schneller aufzubereiten und die Analysen zu beschleunigen. Augmented Analytics spielt dabei ebenso eine Rolle wie traditionelle ETL-Tools (Extract, Transform, Load). Insgesamt tragen die vielfältigen intelligenten Datenmanagement-Tools dazu bei, Daten besser zugänglich und nutzbar zu machen.
Der Einfluss von Augmented Analytics
Augmented Analytics ist der aktuelle Stand der Technik in Sachen Datenanalyse. Augmented Analytics erweitert und automatisiert die Analysemöglichkeiten von Business-Intelligence-Lösungen durch die Nutzung von Methoden und Algorithmen der KI, des maschinellen Lernens und der Sprachverarbeitung (Natural Language Processing, NLP). Beispielsweise kann ein Nutzer per Natural Language Processing in seiner Muttersprache mit der Analysesoftware interagieren. Anstatt SQL-Abfragen einzugeben, können Mitarbeiter einfach übliche deutsche oder englische Sprache verwenden.
Ein weiteres Unterscheidungsmerkmal von Augmented-Analytics-Plattformen ist, dass sie über die Analytik hinausgehen und sie um Datenaufbereitung und sogar einige Data-Warehouse-Funktionen erweitern. Laut Mark Beyer, Research Vice President und Analyst bei Gartner, besteht die Aufgabe von Augmented Analytics darin, Muster der Datennutzung zu erkennen. Diese geben Aufschluss darüber, wer auf welche Daten zugreift, wie oft, in welchen Kombinationen und wie schnell oder langsam sich die Nutzung insgesamt entwickelt.
„Augmented Analytics kann nur aus Mustern und früheren Aktivitäten lernen. Sie können die Datenanalyse auf der Ebene der Erstellung von Inhaltsprofilen nach einzelnen Assets ergänzen und daraus schließen, dass es sich bei ähnlichen Daten in verschiedenen Datensätzen um dieselben Daten handeln könnte“, sagt Beyer. „Jedes Inferenzmodell müsste trainiert werden, um langfristige Muster zu erkennen. Das würde sowohl Zeit als auch viele Anwendungsfälle erfordern, die mit denselben Daten interagieren, um zu zeigen, wie variabel die Muster sind und welche bedingten Szenarien die verschiedenen Variationen antreiben.“
Der Anbieter von Augmented-Analytics-Plattformen, Qlik, bietet eine Reihe von Datenmanagement-Tools, die in einer Lösung verpackt sind. Qlik Replicate, ein universelles Datenreplikations- und Ingestions-Tool, lässt sich mit Qlik Compose, einem Data-Lake- und Automatisierungs-Tool, verknüpfen, um Batch- und Echtzeit-Datenfeeds aus Quellsystemen in Data Warehouses und Lakes zu ermöglichen und zu automatisieren.
Der Qlik Enterprise Manager verwaltet die Datenreplikation und Pipeline-Automatisierung im gesamten Unternehmen zentral und bietet einen einzigen Kontrollpunkt für die Planung, Ausführung und Überwachung von Replikations- und Compose-Aufgaben.
Die resultierenden Datenstrukturen und Metadaten werden mit Qlik Catalog geteilt, so dass Anwender Daten direkt aus Catalog in die Augmented-Analytics-Plattform Qlik Sense – oder ähnliche Plattformen wie Power BI und Tableau – einspeisen können.
„Qlik ermöglicht die Batch-Ausführung und kontinuierliche Migration von Daten über viele Datenquellen und -ziele hinweg – und zwar sowohl On-Premises als auch in der Cloud“, sagt Anand Rao, Product Marketing Director bei Qlik. „Das Programm unterstützt Anwendungsfälle, die von Cloud-Migrationen bis zur Plattform-Modernisierung reichen, und arbeitet eng mit allen wichtigen Cloud-Anbietern zusammen.“
Der Hersteller der Augmented-Analytics-Plattform Sisense bietet eine vollständige Suite von Datenmanagementfunktionen, einschließlich Datenaufnahme, manuelle Datenvorbereitung und KI-basierte Aufbereitung, Modellierung, Governance und Katalogisierung. Jede dieser Funktionen kann gegen Best-of-Breed-Services ausgetauscht werden, die auf möglicherweise auf einen bestimmten Bereich spezialisiert sind.
„Das Besondere an Sisense ist, dass wir die Software als echte Microservices-Lösung konzipiert haben, sodass jeder Workflow ergänzt oder komplett ausgetauscht werden kann“, sagt Ryan Segar, Senior Vice President of Field Engineering bei Sisense.
Für ETL können Kunden zum Beispiel Stitch, Fivetran, CData oder Matillion verwenden. Für Data Warehouses oder Data Lakes können sie Redshift, Snowflake, SingleStore, Databricks oder BigQuery einsetzen. Für Governance und Katalogisierung lassen sich Collibra, Alation, BigID, Alteryx, Trifacta und andere nutzen.
„Machine-Learning-basierte Datenaufbereitung ist mit Abstand der größte Trend, den wir in diesem Bereich sehen“, so Segar. „Die Zeit, die Menschen mit dem Durchkämmen von Tabellen verbringen, um so einfache Aufgaben wie Deduplizierungen durchzuführen, ist lang – und dieser Prozess kann gut automatisiert werden.“
Natural Language Processing rückt in den Vordergrund
Natural Language Processing (NLP) – die Verarbeitung natürlicher Sprache – hat in letzter Zeit die Datenanalyseplattformen ergänzt. Der Grund dafür ist, dass damit auch technisch wenig versierte Benutzer, sogenannte Citizen Data Scientists, auf Daten zugreifen und diese analysieren können. Die Zahl der möglichen Anwender steigt damit stark an.
„NLP versteht die Absicht des Benutzers und analysiert Suchbegriffe, um die wichtigsten Merkmale einer analytischen Anfrage zu identifizieren. Anschließend wird die KI genutzt, um die besten Erkenntnisse für den Benutzer zu generieren, die dann verfeinert und zur weiteren Erläuterung in Dashboards eingefügt werden können“, sagt Rao. „In ähnlicher Weise können Abfragen an ein automatisiertes Data Warehouse von NLP profitieren, so dass Geschäftsanalysten Daten und analytische Berechnungen ohne komplizierte SQL-Abfragen anfordern können.“
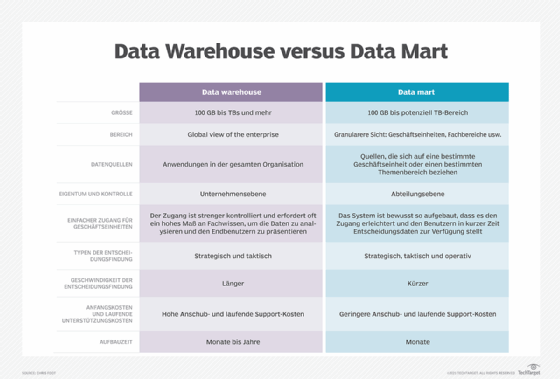
Rao definiert Data-Warehouse-Automatisierung als das Erstellen und Importieren von Datenmodellen, das Ausführen benutzerdefinierter Zuordnungen von Datentypen über verschiedene Datenspeicher hinweg, das Einhalten von Datenvalidierungs- und Qualitätsregeln und das Erstellen von Data Warehouses oder abgeleiteten Data Marts. Ein NLP-gesteuertes Abfragegenerator-Tool kann zunächst zur Aktualisierung einzelner Aufgaben innerhalb eines Workflows verwendet werden und schließlich die weniger komplexen, nachgelagerten Aufgaben ersetzen.
„Das NLP-gesteuerte Tool muss in der Lage sein, typische OLAP-Abfragen [Online Analytical Processing, Anm.] zu generieren, um Data Marts mit den gewünschten Datensätzen zu erstellen“, erläutert Rao.
Während die semantische Ebene den Zugang zu Self-Service-Daten ermöglicht hat, haben die wachsenden Datenmengen und -typen laut Segar ihren Makel offenbart.
„Der Mensch ist immer noch derjenige, der sie erstellt und pflegt. NLP wurde durch Fortschritte bei der Datenkatalogisierung vorangetrieben, und Machine Learning verändert das Spiel, so dass sich Systeme selbst auf Geschäftsbegriffe trainieren können, die in globalen und lokalen Fällen verwendet werden“, sagt Segar. „Bei richtiger Implementierung können wir die schwierigste Aufgabe im Datenmanagement automatisieren: die Einzigartigkeit jedes Benutzers zu erkennen, anstatt ihn zu schulen, anders zu denken.“
Wenn die Sprache auf ihre konsistente Verwendung über viele Vorkommnisse hinweg analysiert wird und ein Subjekt-, Objekt-, Prädikat-Konstrukt (SOP) aufweist, kann sie laut Gartner-Analyst Beyer für Codeeingaben geparst werden. Zum Beispiel basiert Computercode immer auf dem gleichen SOP-Konstrukt:
- Das Subjekt wird von einer Abteilung, Geschäftseinheit oder einer funktionalen Anforderung wie „Patientenaufnahme“ abgeleitet.
- Das Objekt bilden die gewünschten Attribute oder Speicherfelder, die ausgefüllt werden sollen, wie zum Beispiel „Datum und Uhrzeit für die Patientenaufnahme“.
- Das Prädikat sind Verbphrasen in der Sprache, zum Beispiel „aufgenommener Patient“.
„NLP kann also als Programmmodul zur Erfassung der Patientenaufnahme als Subjekt kodiert werden. Die Objekte sind die Patientenkennung, das Krankenhaus, die Stationskennung (falls zutreffend) sowie Datum und Uhrzeit, zu der der Patient als anwesend erfasst wird. Das Prädikat ist die Eingabe von Erfassungsdaten“, erklärt Beyer. „Im Backend versteht ein erweitertes System, wie diese Daten auf der Grundlage früherer Anwendungsfälle verwendet werden. Es kann auch die typischen Fehlertypen erlernen und Kontrollen für deren Überprüfung mithilfe von Regeln zu Datenqualität oder Abfrageplänen als zweites Prädikat erstellen.“
Data Warehouses werden mit Unterstützung von KI und maschinellem Lernen im Laufe der Zeit immer weiter automatisiert. Augmented Analytics ist Teil der Struktur, die dazu beiträgt, den Wert von Daten zu steigern, indem mehr Menschen in die Lage versetzt werden, wichtige kontextbezogene Erkenntnisse zu gewinnen.







