
denisismagilov - stock.adobe.com
Moderne ETL-Tools für die Microservices-Datenintegration
Zwar bieten nicht alle ETL-Tools die für Microservices nötigen Datenintegrationsoptionen, doch moderne Anwendungen decken eine Vielzahl von Datenquellen ab.

Datenintegration und -verarbeitung ist eine komplexe Herausforderung für IT-Abteilungen, wenn sie Microservices-Anwendungen in großem Maßstab verwalten. Moderne Microservices-Anwendungen verarbeiten Daten aus einer Vielzahl von Quellen, wie zum Beispiel Mainframes, proprietäre Datenbanken, E-Mail-Nachrichten und Webseiten. Wenn eine dieser Quellen nicht ordnungsgemäß integriert wird, kann dies zu ernsthaften Problemen führen.
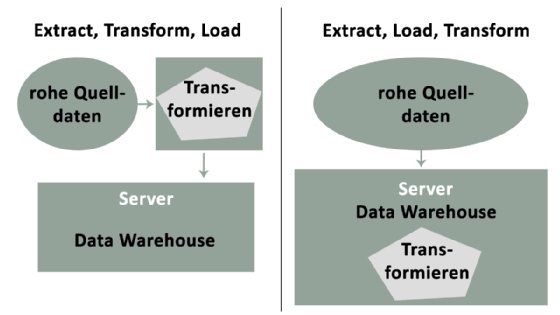
Eine ordnungsgemäße Datenintegration sollte nicht nur Daten aus verschiedenen Quellen kombinieren, sondern auch eine einzige Schnittstelle schaffen, über die man sie anzeigen und abfragen kann. Die am häufigsten verwendete Technik ist Extrahieren, Transformieren und Laden (Extract, Transform, Load, kurz: ETL). Diese bereits ältere Methode der Datenintegration hat in modernen Architekturen neues Leben gefunden.
Traditionelle versus moderne ETL-Tools
Die meisten traditionellen ETL-Tools eignen vor allem für monolithische Anwendungen, die On-Premises ausgeführt werden. Diese Tools wurden entwickelt, um Daten in Stapeln zu integrieren. Beispiele für etablierte Batch-ETL-Tools sind IBM InfoSphere DataStage, Microsoft SQL Server Integration Services, Oracle Data Integrator und Informatica PowerCenter.
Diese Tools wurden entwickelt, um spezifische Probleme monolithischer Anwendungen zu lösen. Die Verwendung für die Microservices-Datenintegration kann eine zeitaufwendige und fehleranfällige Tätigkeit sein. Darüber hinaus erfüllen Batch-Prozesse nicht die modernen Anforderungen an den Echtzeit-Datenzugriff von Microservices-Anwendungen. Unternehmen und Kunden erwarten heute die neuesten verfügbaren Daten.
Moderne ETL-Tools ermöglichen es, Daten in Echtzeit zu speichern, zu streamen und bereitzustellen, da diese Tools mit Blick auf Microservices entwickelt wurden. Der Datenintegrationsansatz umfasst Echtzeitzugriff, Streaming von Daten und Cloud-Integrationsmöglichkeiten. Die Tools lassen sich auch gut in Cloud Data Warehouses wie Amazon RedShift, Snowflake, Google BigQuery und Azure SQL integrieren.
Diese Tools tragen zur ständig wachsenden Zahl von Datenquellen und Datenströmen bei, was den traditionellen ETL-Tools aufgrund ihres Batch-Ansatzes fehlt. Moderne ETL-Tools bieten mehr Sicherheit, da sie in Echtzeit Daten auf Fehler prüfen und anreichern. Zu diesen Streaming- und Data-Pipeline-ETL-Tools gehören Apache Kafka und die Kafka-Plattform Confluent, Matillion, Fivetran und Alooma.
Distributed Streaming mit Kafka
Die Open-Source-Plattform Kafka wird zum Aufbau von Echtzeit-Data-Pipelines und Stream-Processing-Anwendungen verwendet. Ursprünglich als Messaging Queue konzipiert, entwickelte sie sich schnell zu einer vollwertigen Streaming-Plattform, die täglich Billionen von Ereignissen in hochverteilten Microservices-Anwendungen verarbeitet.
Kafka integriert unterschiedliche Systeme über nachrichtenbasierte Kommunikation – in Echtzeit und skalierbar. Obwohl das Konzept nicht neu ist, ist die Methode von Kafka die Grundlage für viele moderne Tools wie Confluent und Alooma.
Einfach zu bedienendes Confluent
Da sich Kafka noch in der frühen Einführungsphase befindet, gibt es einen kleinen Pool von Entwicklern, die über die Fähigkeiten verfügen, es richtig einzusetzen. Mit der Data-Streaming-Plattform von Confluent, die darauf abzielt, die Arbeit mit Kafka einfacher zu machen, können Unternehmen die Lernkurve umgehen.
Confluent erweitert die Integrationsmöglichkeiten von Kafka und bietet zusätzliche Tools und Sicherheitsmaßnahmen zur Überwachung und Verwaltung von Kafka-Streams für die Datenintegration von Microservices. Confluent gibt es in einer kostenlosen Open-Source-Version, einer Enterprise-Version und einer kostenpflichtigen Cloud-Version.
Matillion für Cloud Data Warehouses
Matillion bietet ein ETL-Tool, das speziell für Cloud Data Warehouses wie Amazon Redshift, Google BigQuery und Snowflake entwickelt wurde. Matillion basiert auf einem Amazon Machine Image, das für eine schnelle Einrichtung ausgelegt ist.
Mattilion ermöglicht es, Daten aus Dutzenden von Quellen in ein bevorzugtes Data Warehouse zu laden, wie zum Beispiel Amazon Simple Storage Service (Amazon S3) und Amazon Relational Database Service, Google Analytics, Salesforce, SAP und sogar Social-Media-Plattformen. Damit ist es einfach, das Laden und Transformieren von Daten zu orchestrieren und zu automatisieren und gleichzeitig mit anderen Systemen und AWS-Diensten zu integrieren.
Point and Click mit Fivetran
Das SaaS-Datenintegrations-Tool von Fivetran verspricht Point and Click ETL-Prozesse über eine unkomplizierte Benutzeroberfläche. Es verbindet die Anwendung schnell mit einer Datenquelle, richtet Integrationen ein, wandelt die Daten in das bevorzugte Format um und sendet sie an ihr Ziel.
Fivetran verfügt über eine vollautomatische Data Pipeline für Analysten. Bei der Arbeit mit mehreren Microservices, die jeweils mehrere Datenintegrationen erfordern, kann die Effizienz von Fivetran entscheidend sein.
Ultraschnelle Abfragen mit Alooma
Alooma ist eine weitere moderne ETL-Plattform, die auf Kafka basiert und Streaming-Funktionen wie die Anreicherung von Daten und ultraschnelle Abfragen in Echtzeit bietet. Alooma lässt sich mit gängigen Datenbanken wie MongoDB, Salesforce, REST, iOS und Android integrieren. Google Cloud erwarb Alooma im Februar 2019.
Die Alooma-Plattform bietet horizontale Skalierbarkeit, indem sie so viele Ereignisse wie nötig in kleinen Kostenschritten verarbeitet. Dies ist eine wichtige Voraussetzung für Microservices-Anwendungen, die sporadisch ausfallen können. Aus Sicherheitsgründen speichert Alooma Daten nicht dauerhaft. Es verschlüsselt auch alle laufenden Daten und bietet Zertifizierungen für System and Organization Controls 2 Type 2 und das EU-US Privacy Shield.





