
Elnur - stock.adobe.com
In sieben Schritten ein Machine-Learning-Modell entwickeln
Die Entwicklung eines Machine-Learning-Modells für die Prozessrationalisierung und die Umsetzung von Business-Plänen erfordert Geduld, Vorbereitung und Ausdauer.

KI-Projekte werden heute in vielen Branchen und für zahlreiche Anwendungen eingeführt. Zu diesen Anwendungen gehören zum Beispiel Predictive Analytics, Mustererkennungssysteme, autonome Systeme, Konversationssysteme, Hyperpersonalisierung und zielgerichtete Systeme.
So verschieden diese Projekte auf den ersten Blick erscheinen – sie haben doch etwas gemeinsam: Alle Anwendungsfelder basieren auf einem konkreten Geschäftsproblem und darauf, dass Daten und Machine-Learning-Algorithmen auf das Problem angewendet werden müssen. Das Ergebnis ist ein Modell für maschinelles Lernen, welches die Anforderungen des Projekts erfüllt.
Die Bereitstellung und Verwaltung von Machine-Learning-Projekten erfolgt in der Regel nach demselben Muster. Herkömmliche Vorgehensweisen der Anwendungsentwicklung greifen allerdings nicht. Die bestehenden Methoden sind nicht anwendbar, da KI-Projekte von Daten und nicht von Programmiercode angetrieben werden. Das Lernen wird von Daten abgeleitet.
Der richtige Ansatz und die richtigen Methoden für maschinelles Lernen ergeben sich aus datenzentrierten Anforderungen. Sie führen zu Projekten, die sich in die Phasen der Datenermittlung, der Bereinigung, des Trainings, der Modellerstellung und der Modelliteration einteilen lassen.
Sieben Schritte zur Erstellung eines Machine-Learning-Modells
Für viele Unternehmen ist die Entwicklung von Machine-Learning-Modellen unbekanntes Terrain – und kann zu Beginn einschüchternd wirken. Die schlechte Nachricht: Selbst für diejenigen, die bereits Erfahrung mit maschinellem Lernen haben, erfordert die Erstellung eines KI-Modells eine gehörige Portion Sorgfalt, Experimentierfreude und Kreativität. Die gute Nachricht: Die Methodik für den Aufbau datenzentrierter Projekte ist einigermaßen etabliert.
Die folgenden Schritte unterstützen Sie bei Ihrem Projekt.
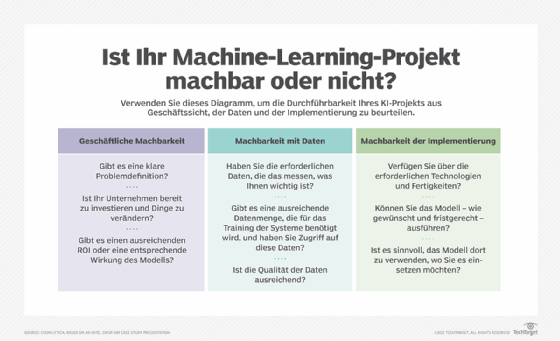
Schritt 1: Verstehen Sie das Geschäftsproblem (und definieren Sie den Erfolg)
Die erste Phase eines jeden Machine-Learning-Projekts besteht darin, ein Verständnis für die geschäftlichen Anforderungen zu entwickeln. Sie müssen wissen, welches Problem Sie lösen müssen, bevor Sie es in Angriff nehmen. Und Sie müssen wissen, wann das Problem erfolgreich gelöst wurde.
Zu Beginn sollten Sie mit dem Projektverantwortlichen zusammenarbeiten und sich vergewissern, dass Sie die Ziele und Anforderungen des Projekts verstanden haben. Ihre Motivation sollte sein, dieses Wissen in eine geeignete Problemdefinition für ein Machine-Learning-Projekt zu transformieren. Anschließend muss ein vorläufiger Plan zum Erreichen der Projektziele erstellt werden. Zu den wichtigsten Fragen, die es zu beantworten gilt, gehören:
- Was ist das Geschäftsziel, das mit einer KI-Lösung erreicht werden soll?
- Welche Teile der Lösung sind KI-relevant, und welche nicht?
- Wurden alle erforderlichen technischen und geschäftlichen Aspekte berücksichtigt, sowie Fragen der Bereitstellung?
- Was sind die definierten Erfolgskriterien für das Projekt?
- Wie kann das Projekt in iterative Sprints aufgeteilt werden?
- Gibt es besondere Anforderungen an die Transparenz, die Erklärbarkeit oder Bias-Minderungen?
- Welche ethischen Überlegungen gibt es?
- Welches sind die akzeptablen Parameter für Genauigkeit, Präzision und Werte der Konfusionsmatrix (die Konfusionsmatrix unterstützt bei der Leistungsmessung für die Klassifizierung durch maschinelles Lernen)?
- Was sind die erwarteten Eingaben in das Modell und die erwarteten Ausgaben?
- Was sind die Merkmale des zu lösenden Problems? Handelt es sich um ein Klassifikations-, Regressions- oder Clustering-Problem?
- Wie lautet die Heuristik – der schnelle und einfache Ansatz zur Lösung des Problems, der kein maschinelles Lernen erfordern würde? Wie viel besser als die Heuristik muss das Modell sein?
- Wie soll der Nutzen des Modells gemessen werden?
Obwohl in diesem ersten Schritt viele Fragen zu beantworten sind, erhöht die Beantwortung – oder auch nur der Versuch einer Beantwortung – die Chancen auf einen Erfolg des Gesamtprojekts erheblich.
Die Festlegung spezifischer, quantifizierbarer Ziele trägt dazu bei, einen messbaren ROI aus dem Machine-Learning-Projekt zu erzielen. Die Alternative ist, das Modell als Proof-of-Concept zu implementieren und es später wieder zu verwerfen. Die Ziele sollten sich auf geschäftliche Belange beziehen und nicht nur auf maschinelles Lernen. Während für maschinelles Lernen spezifische Kennzahlen – wie Präzision, Genauigkeit, Rückruf und mittlerer quadratischer Fehler – in die Metriken aufgenommen werden können, sind spezifischere, geschäftsrelevante Key Performance Indicators (KPIs) besser.
Schritt 2: Verstehen Sie die Daten und legen Sie die Modelldaten fest
Sobald Sie die Geschäftsanforderungen genau kennen und das OK für den Plan vorliegt, können Sie mit der Erstellung des Machine-Learning-Modells beginnen – richtig? Falsch. Die Festlegung des Business Case bedeutet nicht, dass Sie über die Daten verfügen, die für die Erstellung des Lernmodells erforderlich sind.
Ein Machine-Learning-Modell wird generiert durch Lernen und durch Verallgemeinerung aus Trainingsdaten. Es wendet dann das erworbene Wissen auf neue Daten an, die es noch nie zuvor gesehen hat, trifft damit Vorhersagen und erfüllt letztendlich seinen Zweck. Fehlende Daten hindern Sie daran, das Modell zu erstellen. Außerdem reicht der bloße Zugriff auf Daten nicht aus. Nützliche Daten müssen auch sauber und in einem guten Zustand sein.
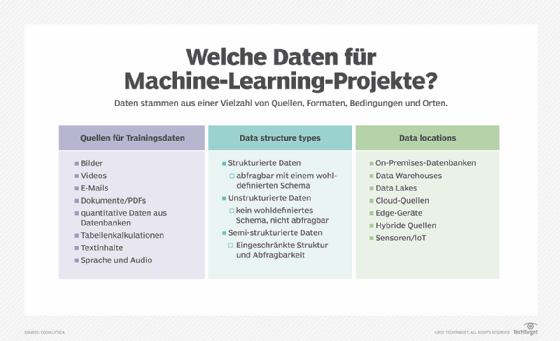
Ermitteln Sie also zunächst Ihren Datenbedarf. Prüfen Sie, ob die Daten für das Machine-Learning-Projekt in einem guten Zustand sind. Der Schwerpunkt sollte auf der Identifizierung der Daten liegen, der ersten Sammlung, den Anforderungen, der Qualitätsbestimmung, den Erkenntnissen und potenziell interessanten Aspekten, die eine weitere Untersuchung wert sind. Hier sind einige Schlüsselfragen, die es zu berücksichtigen gilt:
- Woher stammen die Daten, die für das Training des Modells benötigt werden?
- Welche Datenmenge benötigen Sie für das Machine-Learning-Projekt?
- Wie steht es um die aktuelle Menge und Qualität der Trainingsdaten?
- Wie werden die Testdaten und die Trainingsdaten aufgeteilt?
- Gibt es für überwachte Lernaufgaben eine Möglichkeit, die Daten zu kennzeichnen?
- Können vortrainierte Modelle verwendet werden?
- Wo befinden sich die Betriebs- und Trainingsdaten?
- Gibt es besondere Anforderungen für den Zugriff auf Echtzeitdaten bei Edge-Geräten oder an schwer zugänglichen Orten?
Die Beantwortung dieser zentralen Fragen hilft Ihnen, die Quantität und Qualität der Daten in den Griff zu bekommen. Sie werden damit auch die Art der Daten besser verstehen, die für die Funktionsfähigkeit des Modells erforderlich sind.
Darüber hinaus müssen Sie wissen, wie das Modell mit realen Daten arbeiten soll. Soll das Modell beispielsweise offline verwendet werden, und etwa im Batch-Modus mit Daten arbeiten, die asynchron eingespeist und verarbeitet werden? Oder soll es in Echtzeit eingesetzt werden und mit entsprechend hohen Leistungsanforderungen arbeiten, um sofortige Ergebnisse zu liefern? Diese Informationen bestimmen auch die Art der benötigten Daten und die Anforderungen an den Datenzugriff.
Legen Sie auch fest, ob das Modell einmalig, in Iterationen mit periodisch eingesetzten Versionen oder in Echtzeit trainiert werden soll. Das Training in Echtzeit stellt viele Anforderungen an die Daten, die bei manchen Konstellationen möglicherweise nicht realisierbar sind.
In dieser Phase des KI-Projekts ist es auch wichtig zu wissen, ob es Unterschiede gibt zwischen realen Daten und Trainingsdaten sowie zwischen Test- und Trainingsdaten. Sie sollten auch wissen, welchen Ansatz Sie für die Validierung und Leistungsbewertung des Modells wählen werden.
Schritt 3: Sammeln Sie Daten und bereiten Sie diese vor
Nachdem Sie Ihre Daten identifiziert haben, müssen Sie diese so aufbereiten, dass sie zum Trainieren Ihres Modells verwendet werden können. Der Schwerpunkt liegt dabei auf den datenbezogenen Aktivitäten. Diese Aktivitäten sind für die Bereitstellung des Datensatzes als Basis der Modellierung erforderlich. Zu den Aufgaben bei der Datenvorbereitung gehören Datenerfassung, -bereinigung, -aggregation, -erweiterung, -kennzeichnung, -normalisierung und -transformation. Hinzu kommen alle anderen Aktivitäten für strukturierte, unstrukturierte und halbstrukturierte Daten.
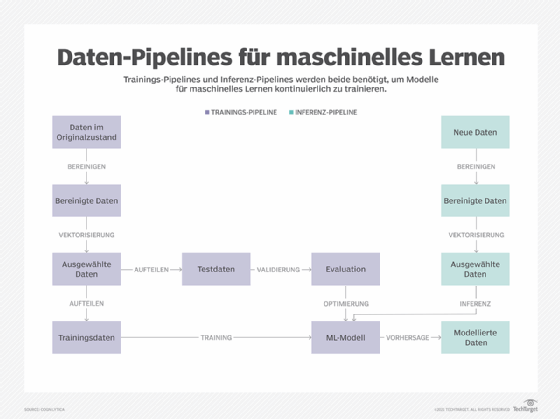
Der Prozess der Datenvorbereitung, -erfassung und -bereinigung umfasst folgende Verfahren:
- Sammeln Sie Daten aus verschiedenen Quellen.
- Standardisieren Sie Datenformate über verschiedene Datenquellen hinweg.
- Ersetzen Sie fehlerhafte Daten.
- Reichern Sie die Daten an und erweitern Sie sie.
- Fügen Sie weitere Dimensionen mit vorberechneten Beträgen und aggregierten Informationen nach Bedarf hinzu.
- Reichern Sie eigene Daten mit Daten von Dritten an.
- Multiplizieren Sie bildbasierte Datensätze, wenn sie für das Training nicht ausreichen.
- Entfernen Sie überflüssige Informationen und deduplizieren Sie die Daten.
- Entfernen Sie irrelevante Daten aus dem Trainingsdatensatz, um die Ergebnisse zu verbessern.
- Reduzieren Sie Rauschunterdrückung und beseitigen Sie Mehrdeutigkeiten.
- Erwägen Sie die Anonymisierung von Daten.
- Normalisieren oder standardisieren Sie Daten, um sie in ein einheitliches Format zu bringen.
- Wählen Sie Daten aus großen Datensätzen aus.
- Wählen Sie Merkmale, die die wichtigsten Dimensionen identifizieren, und, falls erforderlich, reduzieren Sie Dimensionen mit verschiedenen Techniken.
- Teilen Sie die Daten in Trainings-, Test- und Validierungsdatensätze auf.
Die Vorbereitung und Bereinigung von Daten kann viel Zeit in Anspruch nehmen. Umfragen unter Entwicklern und Datenwissenschaftlern aus dem Bereich des maschinellen Lernens zeigen, dass die Schritte der Datensammlung und -vorbereitung bis zu 80 Prozent der Zeit eines Machine-Learning-Projekts in Anspruch nehmen können. Dabei sollte man bedenken: Trainieren Sie das Modell mit schlechten Daten, wird das Modell ebenfalls schlecht funktionieren. Da Machine-Learning-Modelle aus Daten lernen müssen, lohnt sich der Zeitaufwand für die Vorbereitung und Bereinigung der Daten.
Schritt 4: Bestimmen Sie die Merkmale des Modells und trainieren Sie es
Sobald die Daten in einem brauchbaren Zustand vorliegen und Sie das Problem kennen, das Sie lösen sollen, kann es losgehen: Sie können zu dem Schritt übergehen, den Sie schon lange machen wollen: Das Trainieren des Modells. Damit das Modell aus den von Ihnen vorbereiteten Daten guter Qualität lernt, müssen Sie eine Reihe von Techniken und Algorithmen anwenden.

Diese Phase erfordert die Auswahl und Anwendung von Modelltechniken, das Modelltraining, die Einstellung und Anpassung von Hyperparametern, die Modellvalidierung, die Entwicklung und das Testen von Ensemble-Modellen, die Auswahl von Algorithmen und die Modelloptimierung. Um all dies auszuführen, sind folgende Maßnahmen erforderlich:
- Wählen Sie den passenden Algorithmus auf der Grundlage des Lernziels und der Datenanforderungen aus.
- Konfigurieren Sie Hyperparameter für eine optimale Leistung, stimmen Sie diese ab und legen Sie eine Iterationsmethode fest, um die besten Hyperparameter zu erreichen.
- Identifizieren Sie die Merkmale, die die besten Ergebnisse liefern.
- Legen Sie fest, ob das Modell erklärbar oder interpretierbar sein muss.
- Entwickeln Sie Ensemble-Modelle zur Verbesserung der Leistung.
- Testen Sie die verschiedenen Modellversionen auf ihre Leistungsfähigkeit.
- Identifizieren Sie die Anforderungen an den Betrieb und die Bereitstellung des Modells.
Das resultierende Modell kann dann bewertet werden. Das Ziel dabei ist, festzustellen, ob es die geschäftlichen und betrieblichen Anforderungen erfüllt.
Schritt 5: Bewerten Sie die Leistung des Modells und legen Sie Benchmarks fest
Aus KI-Perspektive umfasst die Evaluierung des Lernmodells folgende Punkte: die Evaluierung von Modellmetriken, Berechnungen der Konfusionsmatrix, KPIs, Metriken zur Modellleistung und Messungen der Modellqualität. Abschließend muss noch festgestellt werden, ob das Modell die festgelegten Geschäftsziele erfüllen kann.
Im Einzelnen sollten Sie während des Prozesses der Modellevaluierung Folgendes tun:
- Bewerten Sie das Modell anhand eines Validierungsdatensatzes.
- Bestimmen Sie die Werte der Konfusionsmatrix für Klassifizierungsprobleme.
- Identifizieren Sie Methoden für die k-fache Kreuzvalidierung, falls dieser Ansatz verwendet wird.
- Optimieren Sie die Hyperparameter weiter, um eine optimale Leistung zu erzielen.
- Vergleichen Sie das Machine-Learning-Modell mit dem Basismodell oder einer Heuristik.
Die Modellevaluierung kann als Qualitätssicherung des maschinellen Lernens betrachtet werden. Durch die Bewertung der Modellleistung anhand von Metriken und Anforderungen wird überprüft, wie das Modell in der realen Welt funktioniert.

Schritt 6: Nehmen Sie das Modell in Betrieb und stellen Sie sicher, dass es gut funktioniert
Wenn Sie überzeugt sind, dass Ihr Machine-Learning-Modell in der realen Welt funktioniert, ist es an der Zeit, das zu überprüfen. Dieser Schritt ist auch bekannt als Operationalisierung des Modells:
- Stellen Sie das Modell so bereit, dass Sie seine Leistung kontinuierlich messen und überwachen können.
- Entwickeln Sie eine Baseline oder einen Benchmark, an dem zukünftige Iterationen des Modells gemessen werden können.
- Wiederholen Sie kontinuierlich verschiedene Aspekte des Modells, um die Gesamtleistung zu verbessern.
Die Operationalisierung des Modells kann verschiedene Bereiche umfassen: Dazu gehören beispielsweise Einsatzszenarien in einer Cloud-Umgebung, an der Edge, in einer lokalen oder geschlossenen Umgebung oder innerhalb einer geschlossenen, kontrollierten Gruppe.
Bei der Operationalisierung sollten Sie auch verschiedene Überlegungen anstellen: Diese umfassen etwa Modellversionierung und -iteration, Modellbereitstellung, Modellüberwachung und Modellbereitstellung in Entwicklungs- und Produktionsumgebungen. Je nach den praktischen Anforderungen kann die Operationalisierung eines Modells von der einfachen Erstellung eines Berichts bis hin zu einer komplexeren Bereitstellung an mehreren Endpunkten reichen.
Schritt 7: Iterieren Sie das Modell und passen Sie es an
Auch wenn das Modell einsatzfähig ist und Sie seine Leistung kontinuierlich überwachen: Sie sind noch nicht fertig. Wenn es um die Implementierung von Technologien geht, heißt es oft, dass die Erfolgsformel darin besteht, klein anzufangen, groß zu denken und häufig zu iterieren.
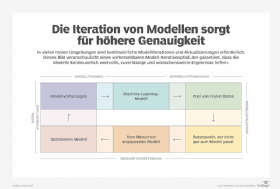
Wiederholen Sie den Prozess immer wieder und nehmen Sie rechtzeitig Modifikationen und Verbesserungen für die nächste Iteration vor. Berücksichtigen Sie dabei, dass sich einiges ändert: Geschäftsanforderungen ändern sich. Die technologischen Möglichkeiten ändern sich. Und auch Daten aus der realen Welt ändern sich – oft auf unerwartete Weise.
All dies kann neue Anforderungen für den Einsatz des Modells an anderen Endpunkten oder in neuen Systemen mit sich bringen.
Das Ende kann nur ein neuer Anfang sein, daher ist es am besten, Folgendes festzulegen:
- die nächsten Anforderungen an die Funktionalität des Modells
- die Ausweitung des Modelltrainings, um das Modell zu verbessern
- die Verbesserung der Modell-Performance und -genauigkeit
- die Verbesserung der operativen Leistung des Modells
- die betrieblichen Anforderungen für verschiedene Einsätze
- die Lösungen für einen Modelldrift oder Datendrift, die zu Leistungsänderungen aufgrund von Änderungen der realen Daten führen können.
Denken Sie darüber nach, was in Ihrem Modell funktioniert hat, was überarbeitet werden muss und was noch in Arbeit ist. Ein todsicherer Weg zum Erfolg bei der Entwicklung von Machine-Learning-Modellen ist die kontinuierliche Suche nach Optimierungen – und besseren Möglichkeiten, um den sich ändernden Geschäftsanforderungen gerecht zu werden.
Historische Perspektive der Modellerstellung
Vor etwa 25 Jahren entwickelte ein Konsortium aus fünf Anbietern den Cross-Industry Standard Process for Data Mining (CRISP-DM). Der Prozess konzentrierte sich auf einen kontinuierlichen Iterationsansatz für die verschiedenen datenintensiven Schritte in einem Data-Mining-Projekt.
Die Methodik beginnt mit einer iterativen Schleife zwischen Geschäftsverständnis und Datenverständnis. Darauf folgt eine Übergabe an eine iterative Schleife zwischen Datenvorbereitung und Datenmodellierung, gefolgt von einer Evaluierungsphase, die ihre Ergebnisse an die Bereitstellung und zurück an das Geschäftsverständnis weitergibt. Diese zyklische, iterative Schleife führt zu einer kontinuierlichen Datenmodellierung, -aufbereitung und -auswertung.
Die Entwicklung von CRISP-DM ist jedoch bei Version 1.0 stehen geblieben. Diese wurde vor fast zwei Jahrzehnten fertiggestellt, und über eine zweite Version sind seit fast 15 Jahren nur Gerüchte im Umlauf. IBM und Microsoft haben die Methodik iterativ weiterentwickelt und ihre eigenen Varianten entwickelt. Diese beschreiben die iterativen Schleifen zwischen Datenverarbeitung und Modellierung detaillierter und auch die während des Prozesses erzeugten Artefakte und Ergebnisse.
Darüber hinaus wurde die Methodik dafür kritisiert, dass sie nicht besonders agil und zu wenig spezifisch für KI- und Machine-Learning-Projekte ist. Methoden wie Cognitive Project Management for AI wurden weiterentwickelt, um den KI-spezifischen Anforderungen gerecht zu werden. Sie können in Unternehmen mit bestehenden agilen Entwicklungsteams und Datenorganisationen implementiert werden.
Diese Methoden sowie die Erfahrungen großer Unternehmen und ihrer Data-Science-Teams haben zu einem stärkeren, flexibleren schrittweisen Ansatz für die Entwicklung von Machine-Learning-Modellen geführt, der den spezifischen Anforderungen kognitiver Projekte besser gerecht wird.





