
alunablue - stock.adobe.com
Hadoop versus Spark: ein Vergleich der Big Data Frameworks
Apache Hadoop und Spark sind zwei weit verbreitete Big Data Frameworks. Ein Einstieg in ihre Funktionen und Möglichkeiten sowie die wichtigsten Unterschiede bei den Technologien.

Hadoop und Spark sind zwei der beliebtesten Datenverarbeitungsanwendungen für Big Data. Beide stehen im Mittelpunkt eines umfangreichen Ökosystems von Open-Source-Technologien zur Verarbeitung, Verwaltung und Analyse großer Datenmengen.
Apache Hadoop und Apache Spark haben aber auch viele Debatten ausgelöst. Das betrifft insbesondere die richtige Wahl und Nutzung der Frameworks. Die meisten Diskussionen drehen sich um die Optimierung von Big-Data-Umgebungen für Stapelverarbeitung oder Echtzeitverarbeitung. Das vereinfacht jedoch den Vergleich beider Systeme. Während Hadoop ursprünglich auf Batch-Anwendungen beschränkt war, kann es jetzt auch für interaktive Abfragen und Echtzeit-Analysen eingesetzt werden – dies gilt zumindest für einige seiner Komponenten. Spark hingegen wurde ursprünglich entwickelt, um Batch-Jobs schneller zu verarbeiten, als dies mit Hadoop möglich war.
Außerdem ist eine Entscheidung zwischen Hadoop und Spark nicht unbedingt eine Entweder-oder-Entscheidung. Viele Unternehmen setzen beide Plattformen für unterschiedliche Big-Data-Anwendungen ein. Sie können auch zusammen verwendet werden: Spark-Anwendungen werden häufig auf der Ressourcenmanagementtechnologie YARN und dem Hadoop Distributed File System (HDFS) aufgebaut. HDFS ist eine der wichtigsten Datenspeicheroptionen für Spark, das über kein eigenes Dateisystem oder Repository verfügt.
Im Folgenden werden die Komponenten, Funktionen und Fähigkeiten von Hadoop und Spark und ihre Unterschiede näher betrachtet. Wir starten mit einigen grundlegenden Details, die für jedes Open Source Framework gelten.
Was ist Apache Hadoop?
Apache Hadoop wurde von den Softwareentwicklern Doug Cutting und Mike Cafarella entwickelt und erstmals 2006 veröffentlicht. Der Zweck des Programms war, große Datenmengen zu verarbeiten. Dabei wurde zunächst das namensgebende Dateisystem verwendet sowie MapReduce – ein Programmiermodell und eine Processing Engine, die Google 2004 vorstellte.
Hadoop bietet die Möglichkeit, die Verarbeitung großer Datenmengen effizient auf verschiedene Computer aufzuteilen, Berechnungen lokal auszuführen und die Ergebnisse dann zu kombinieren. Mit dieser verteilten Verarbeitungsarchitektur können Big-Data-Anwendungen für Cluster erstellt werden, die hunderte oder tausende handelsübliche Commodity-Server, sogenannte Nodes, enthalten.
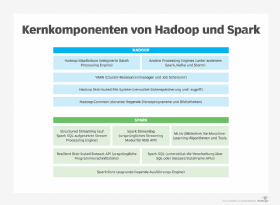
Zu den Hauptkomponenten von Hadoop gehören:
- HDFS. HDFS (Hadoop Distributed File System) wurde ursprünglich auf der Grundlage eines von Google favorisierten Dateisystems entwickelt. Es verwaltet den Prozess der Verteilung, der Speicherung und des Zugriffs auf Daten über viele separate Server hinweg. HDFS kann sowohl strukturierte als auch unstrukturierte Daten verarbeiten und eignet sich daher für den Aufbau eines Data Lake.
- YARN. YARN (Yet Another Resource Negotiator) ist der Cluster-Ressourcenmanager von Hadoop. YARN ist für die Ausführung der verteilten Workloads zuständig. Die Software plant die Verarbeitungsaufträge und weist den Anwendungen Rechenressourcen wie CPU und Speicher zu. YARN hat diese Aufgaben von MapReduce übernommen, als dieses 2013 als Teil von Hadoop 2.0 hinzugefügt wurde.
- Hadoop MapReduce. Obwohl die Bedeutung von MapReduce durch YARN reduziert wurde, ist MapReduce nach wie vor wichtig. MapReduce ist die integrierte Processing Engine, die in vielen Hadoop-Clustern zur Ausführung großer Batch-Anwendungen verwendet wird. Sie orchestriert den Prozess der Aufteilung umfangreicher Berechnungen in kleinere. Die Rechenaufgaben können auf mehrere Clusterknoten verteilt werden, auf denen dann die verschiedenen Verarbeitungsaufträge ausgeführt werden.
- Hadoop Common. Hierbei handelt es sich um eine Reihe von Dienstprogrammen und Bibliotheken, die von den anderen Hadoop-Komponenten verwendet werden.
Was ist Apache Spark?
Apache Spark wurde ursprünglich von Matei Zaharia im Jahr 2009 entwickelt, als er Doktorand an der University of California (Berkeley) war. Die wichtigste Neuerung bei dieser Technologie war die Verbesserung der Datenorganisation – die In-Memory-Verarbeitung über verteilte Clusterknoten wurde damit effizienter skalierbar.
Wie Hadoop kann Spark riesige Datenmengen verarbeiten. Dazu teilt Spark Arbeitslasten – wie Hadoop – auf verschiedene Knoten auf, bei Spark geschieht diese Aufteilung in der Regel aber viel schneller als bei Hadoop. Dadurch kann Spark Anwendungsfälle verarbeiten, die Hadoop mit MapReduce nicht bewältigt – und macht es zu einer universellen Allzweck-Processing-Engine.
Die folgenden Technologien bilden die Schlüsselkomponenten von Spark:
- Spark Core. Spark Core ist die zugrunde liegende Execution Engine. Sie übernimmt die Jobplanung und die Koordinierung grundlegender I/O-Operationen unter Verwendung der Basic API von Spark.
- Spark SQL. Das Spark-SQL-Modul ermöglicht Benutzern die optimierte Verarbeitung strukturierter Daten. Diese erfolgt durch die direkte Ausführung von SQL-Abfragen oder den Zugriff auf die SQL-Execution-Engine über die Dataset-API von Spark.
- Spark Streaming und Structured Streaming. Diese Module fügen Funktionen für die Streaming-Verarbeitung hinzu. Spark Streaming übernimmt Daten aus verschiedenen Streaming-Quellen – einschließlich HDFS, Kafka und Kinesis – und unterteilt sie in Mikro-Batches, um einen kontinuierlichen Stream darzustellen. Structured Streaming ist ein neuerer Ansatz. Er baut auf Spark SQL auf, und ist darauf ausgelegt ist, die Latenz zu reduzieren und die Programmierung zu vereinfachen.
- MLlib. MLlib ist eine integrierte Bibliothek für maschinelles Lernen. Sie enthält eine Reihe von Algorithmen für maschinelles Lernen sowie Tools für die Auswahl von Merkmalen und den Aufbau von Pipelines für maschinelles Lernen.
Wie unterscheiden sich Hadoop und Spark?
Ein wesentlicher Unterschied zwischen den beiden Frameworks ist die Verwendung von MapReduce in Hadoop. HDFS war in den ersten Versionen von Hadoop eng mit MapReduce verbunden, während Spark speziell entwickelt wurde, um MapReduce zu ersetzen. Auch wenn Hadoop bei der Datenverarbeitung aktuell nicht mehr ausschließlich von MapReduce abhängt, gibt es immer noch eine starke Verbindung zwischen beiden. „In den Köpfen vieler Menschen ist Hadoop gleichbedeutend mit MapReduce“, sagt Erik Gfesser, Director und Chief Architect beim Beratungsunternehmen Deloitte.
MapReduce in Hadoop hat Vorteile, wenn es darum geht, die Kosten für große Verarbeitungsaufträge, die einige Verzögerungen tolerieren können, niedrig zu halten. Auf der anderen Seite hat Spark gegenüber MapReduce den klaren Pluspunkt, zeitnahe Analyseergebnisse zu liefern. Der Grund dafür ist, dass es Daten hauptsächlich In-Memory verarbeitet.
Hadoop kam zuerst auf den Markt und revolutionierte die Art und Weise, wie Anwender die Skalierung von Daten-Workloads angehen können. Es machte Big-Data-Anwendungen mit großen Datenmengen und unterschiedlichen Datentypen in Unternehmen möglich. Insbesondere die Aggregation und Speicherung von Datensätzen zur Unterstützung von Analyseanwendungen wurden deutlich verbessert. Daher wird Hadoop häufig als Plattform für Data Lakes eingesetzt, in denen sowohl Rohdaten als auch aufbereitete Datensätze für Analysezwecke gespeichert werden.
Obwohl Hadoop inzwischen nicht nur ausschließlich für die Stapelverarbeitung verwendet werden kann, eignet es sich in erster Linie für die Analyse von historischen Daten. Spark wurde von Grund auf für die Optimierung von Datenverarbeitungsaufträgen mit hohem Durchsatz entwickelt. Daher ist es für verschiedene Anwendungen geeignet. So wird Spark sowohl für Online-Anwendungen und interaktive Datenanalysen als auch für ETL-Prozesse (Extract, Transform, Load) und andere Batch-Prozesse verwendet. Es kann allein zur Datenanalyse oder als Teil einer Pipeline für die Datenverarbeitung eingesetzt werden.
Spark kann auch als Staging Tier auf einem Hadoop-Cluster für ETL und explorative Datenanalysen genutzt werden. Damit wird ein weiterer wesentlicher Unterschied zwischen den beiden Frameworks deutlich: Spark verfügt nicht über ein integriertes Dateisystem wie HDFS. Das bedeutet, dass es mit Hadoop oder anderen Plattformen für die langfristige Datenspeicherung und -verwaltung gekoppelt werden muss.
Im Folgenden vergleichen wir Hadoop und Spark in verschiedenen spezifischen Bereichen.
Architektur
Der grundlegende architektonische Unterschied zwischen Hadoop und Spark ist die Art und Weise, wie die Daten für die Verarbeitung organisiert werden. In Hadoop werden alle Daten in Blöcke aufgeteilt. Diese werden über die Festplatten der verschiedenen Server in einem Cluster repliziert, wobei HDFS ein hohes Maß an Redundanz und Fehlertoleranz bietet. Hadoop-Anwendungen können dann als einzelner Job oder als Directed Acyclic Graph (DAG), welcher mehrere Aufträge enthält, ausgeführt werden.
In Hadoop 1.0 verteilte ein zentraler JobTracker-Dienst MapReduce-Aufgaben auf die Knoten. Diese Tasks konnten unabhängig voneinander ausgeführt werden, wobei ein lokaler TaskTracker-Dienst die Auftragsausführung auf den einzelnen Knoten verwaltete. Ab Hadoop 2.0 wurden JobTracker und TaskTracker jedoch durch folgende Komponenten von YARN ersetzt:
- ein ResourceManager-Daemon, der als globaler Job-Scheduler und Ressourcen-Arbitrator fungiert
- NodeManager, ein Agent, der auf jedem Cluster-Knoten installiert wird, um die Ressourcennutzung zu überwachen
- ApplicationMaster, ein für jede Anwendung erstellter Daemon, der die erforderlichen Ressourcen vom ResourceManager aushandelt und mit den NodeManagern zusammenarbeitet, um Verarbeitungsaufgaben auszuführen
- Ressourcencontainer, welche die Systemressourcen enthalten, die den verschiedenen Knoten und Anwendungen zugewiesen sind
In Spark wird auf Daten von externen Speicherorten zugegriffen. Bei diesen Storage-Systemen kann es sich um HDFS, einen Cloud-Objektspeicher wie Amazon Simple Storage Service, verschiedene Datenbanken und andere Arten von Datenspeichern handeln. Zwar finden bei Spark die meisten Verarbeitungen im Arbeitsspeicher statt, die Plattform kann jedoch Daten auch auf die Festplatte auslagern und dort verarbeiten. Dies ist von Vorteil, wenn die Datensätze zu groß sind, um in den verfügbaren Arbeitsspeicher zu passen. Spark kann außerdem auf Clustern ausgeführt werden, die von YARN, Mesos und Kubernetes verwaltet werden, oder im Standalone-Modus.
Ähnlich wie bei Hadoop hat sich die Architektur von Spark gegenüber dem ursprünglichen Entwurf erheblich verändert. In frühen Versionen organisierte Spark Core Daten in einem Resilient Distributed Dataset (RDD) – einem In-Memory-Datenspeicher, der auf die verschiedenen Knoten in einem Cluster verteilt ist. Außerdem wurden DAGs erstellt, die bei der Planung von Aufträgen für eine effiziente Verarbeitung helfen.
Die RDD-API wird weiterhin unterstützt. Aber seit Spark 2.0 wurde die RDD-API durch die Dataset-API als empfohlene Programmierschnittstelle ersetzt. Wie RDDs sind Datasets verteilte Datensammlungen mit starken Typisierungsfunktionen. Um die Leistung zu steigern, enthalten sie aber umfangreichere Optimierungen durch Spark SQL. Die aktualisierte Architektur umfasst auch DataFrames, bei denen es sich um Datensätze mit benannten Spalten handelt. Diese ähneln vom Konzept her relationalen Datenbanktabellen oder Data Frames in R- und Python-Anwendungen. Structured Streaming und MLlib verwenden beide den Dataset/DataFrame-Ansatz.
Fähigkeiten der Datenverarbeitung
Hadoop und Spark sind beides verteilte Big Data Frameworks, mit denen große Datenmengen verarbeitet werden können. Trotz der durch YARN ermöglichten erweiterten Workloads orientiert sich Hadoop immer noch hauptsächlich an MapReduce. Dieses eignet sich gut für langlaufende Batch-Jobs, für die keine strengen Service Level Agreements (SLA) gelten.
Spark hingegen kann Batch-Workloads als Alternative zu MapReduce ausführen. Es bietet aber darüber hinaus APIs auf höherer Ebene für verschiedene andere Anwendungen. Zusätzlich zu den Modulen für SQL, Stream Processing und maschinelles Lernen umfasst es eine GraphX-API für die Graphverarbeitung sowie SparkR- und PySpark-Schnittstellen für die Programmiersprachen R und Python.
Leistung
Die Datenverarbeitung mit Hadoop und MapReduce ist in der Regel langsam und kann schwierig zu verwalten sein. Spark ist bei vielen Batch-Jobs schneller: Befürworter behaupten, dass Spark bei der Verarbeitung von Batch-Jobs im Hauptspeicher bis zu 100-mal schneller ist als eine entsprechende Anwendung auf Hadoop – obwohl der Leistungsgewinn in den meisten realen Anwendungen wahrscheinlich viel geringer ist.
Ein wichtiger Grund für den Geschwindigkeitsvorteil von Spark ist die Tatsache, dass die Verarbeitung der Daten ohne Zwischenschritt – dem Rückschreiben der Daten auf die Festplatte – erfolgen kann. Aber selbst Spark-Anwendungen, die explizit für die Ausführung auf der Festplatte geschrieben wurden, können nach Angaben der Spark-Entwickler potenziell eine zehnmal bessere Leistung erzielen als vergleichbare MapReduce-Workloads auf Hadoop.
Hadoop kann jedoch einen Vorteil haben, wenn viele länger laufende Anwendungen gleichzeitig auf demselben Cluster verwaltet werden sollen. Spark ist hier im Nachteil: Wenn viele Spark-Anwendungen gleichzeitig ausgeführt werden, kann es zu Speicherproblemen kommen, die die Leistung aller Anwendungen beeinträchtigen.
Skalierbarkeit
Grundsätzlich lassen sich Hadoop-Systeme so skalieren, dass sie größere Datensätze aufnehmen können, auf die nur sporadisch zugegriffen wird. Dabei wird ein Teil der Daten auf Festplatten gespeichert und verarbeitet – was kostengünstiger ist als die Daten ständig im Hauptspeicher vorzuhalten. Eine in Hadoop 3.0 – die 2017 veröffentlichte Version – hinzugefügte YARN-Federation-Funktion ermöglicht es Clustern, Zehntausende von Knoten und mehr zu unterstützen. Dafür verbindet sie mehrere Subcluster, die über eigene Ressourcenmanager verfügen.

Der Nachteil ist, dass IT- und Big-Data-Teams bei On-Premises-Implementierungen möglicherweise mehr Arbeit investieren müssen, um neue Knoten bereitzustellen und zu einem Cluster hinzuzufügen. Außerdem wird bei Hadoop der Speicher mit den Rechenressourcen auf den Clusterknoten zusammengelegt, was es für Anwendungen und Benutzer außerhalb des Clusters schwierig machen kann, auf die Daten zuzugreifen. Einige dieser Skalierbarkeitsprobleme können jedoch automatisch mit Hadoop-Diensten in der Cloud verwaltet werden.
Einer der Hauptvorteile von Spark ist die Trennung von Speicher- und Rechenleistung. Dies erleichtert es Anwendungen und Nutzern, von überall auf die Daten zuzugreifen. Spark enthält Tools, die Benutzern unterstützen, Knoten je nach Workload-Anforderungen dynamisch nach oben und unten zu skalieren; außerdem ist es in Spark einfacher, die Knoten am Ende eines Verarbeitungszyklus automatisch neu zuzuweisen. Eine Herausforderung bei der Skalierung von Spark-Anwendungen besteht darin, sicherzustellen, dass die Anwendungen unabhängig voneinander auf die Knoten verteilt werden, um Speicherverluste zu reduzieren.
Sicherheit
Hadoop bietet ein höheres Maß an Sicherheit mit weniger externem Overhead für die langfristige Datenspeicherung. HDFS verfügt über eine transparente Ende-zu-Ende-Datenverschlüsselung mit separaten Verzeichnissen für Verschlüsselungszonen und einem integrierten Dienst für die Verwaltung der Schlüssel. Es enthält auch ein auf Berechtigungen basierendes Modell zur Durchsetzung von Zugriffskontrollen für Dateien und Verzeichnisse mit der Möglichkeit, Zugriffskontrolllisten zu erstellen. Diese können für die Implementierung rollenbasierter Sicherheit und anderen Regeln für verschiedene Benutzer oder Gruppen verwendet werden.
Darüber hinaus kann Hadoop in einem sicheren Modus mit Kerberos-Authentifizierung für alle Dienste und Benutzer betrieben werden. Es kann auch die Vorteile zugehöriger Tools nutzen. Dazu gehören beispielsweise Apache Knox, ein REST-API-Gateway, das Authentifizierungs- und Proxy-Dienste zur Durchsetzung von Sicherheitsrichtlinien in Hadoop-Clustern bereitstellt, sowie Apache Ranger, ein zentrales Sicherheitsmanagement-Framework für Hadoop-Umgebungen. Diese Kombination von Funktionen bietet eine stärkere Security im Vergleich zu Spark.
Spark verfügt über ein komplexeres Sicherheitsmodell, das verschiedene Sicherheitsstufen für mehrere Arten von Bereitstellungen unterstützt. Beispielsweise verwendet es einen Shared-Secret-Authentifizierungsansatz. Dieser dient für Aufrufe von Remote-Prozeduren zwischen Spark-Prozessen mit bereitstellungsspezifischen Mechanismen zum Generieren der geheimen Passwörter. In einigen Fällen sind die Sicherheitsvorkehrungen eingeschränkt, da alle Anwendungen und Daemons die gleichen Geheimnisse teilen, obwohl dies nicht gilt, wenn Spark auf YARN oder Kubernetes ausgeführt wird.
Das Spark-Modell wurde in erster Linie entwickelt, um die Sicherheit von Datenströmen zu gewährleisten. Diese sind weniger dauerhaft als Daten, die über längere Zeiträume gespeichert werden. Eine Sorge ist, dass dies die Spark-Dateninfrastrukturen für ein breiteres Spektrum und größeres Ausmaß von Cyberangriffen öffnen kann. Darüber hinaus sind Authentifizierung und andere Sicherheitsmaßnahmen in Spark nicht standardmäßig aktiviert. Dennoch kann ein ausreichender Schutz durch die Kombination einer geeigneten Verschlüsselungsarchitektur mit passenden Richtlinien zur Schlüsselverwaltung erreicht werden.
Anwendungen und Anwendungsfälle
Sowohl Hadoop MapReduce als auch Spark werden häufig für Stapelverarbeitungsaufgaben verwendet – zum Beispiel für ETL-Aufgaben zur Übertragung von Daten in einen Data Lake oder ein Data Warehouse. Beide können auch verschiedene Big-Data-Analyse-Anwendungen mit aktuellen oder historischen Daten verarbeiten, wie beispielsweise Kundenanalysen, prädiktive Modellierung, Geschäftsprognosen, Risikomanagement und Cyberbedrohungsanalysen.
Spark ist oft die bessere Wahl für Daten-Streaming und Anwendungen für Echtzeit-Analysen. Dazu gehören zum Beispiel Betrugserkennung, vorausschauende Wartung, Aktienhandel, Empfehlungsmaschinen, zielgerichtete Werbung und Preisgestaltung für Flugtickets und Hotels. Auch für laufende Data-Science-Initiativen – einschließlich Graphberechnungen und Anwendungen für maschinelles Lernen – ist Spark in der Regel besser geeignet.
Maschinelles Lernen
Speziell im Bereich des maschinellen Lernens eignet sich Hadoop am besten als Staging Tier für die Verwaltung der extrem großen Datensätze, die Anwendungen häufig benötigen. Es ist gut geeignet, Rohdaten aus verschiedenen Quellen aufzunehmen und die Ergebnisse von ETL-Prozessen für die anschließende Untersuchung und Analyse durch Machine-Learning-Algorithmen zu speichern.
Im Gegensatz dazu eignet sich Spark besser für die direkte explorative Datenanalyse und den Einsatz von Modellen für maschinelles Lernen. Sein MLlib-Modul enthält Algorithmen, die für verschiedene Arten von Machine-Learning-Prozessen optimiert sind, wie zum Beispiel Klassifizierung, Regression, Clustering und Pattern Mining. Das Modul bietet auch Tools für Feature-Engineering, Pipelineentwicklung und Modellbewertung sowie Dienstprogramme für lineare Algebra und Statistik. Darüber hinaus ist Spark die empfohlene Backend-Plattform für Apache Mahout, ein Framework für maschinelles Lernen und verteilte lineare Algebra, das ursprünglich auf Hadoop MapReduce aufgesetzt wurde.
Hadoop und Spark können jedoch auch beide zusammen verwendet werden, um maschinelles Lernen zu unterstützen. Beispielsweise können Datenwissenschaftler und Dateningenieure Rohdaten aus HDFS in Spark ziehen, um sie interaktiv zu untersuchen und zu verarbeiten. Nachdem der Prozess des Feature-Engineerings und der Auswahl abgeschlossen ist, werden die Modelle für maschinelles Lernen ebenfalls direkt in Spark aggregiert und verarbeitet. Merkmale, die zwar interessant, aber für ein bestimmtes Projekt nicht relevant sind, könnten in einem Hadoop-Cluster für eine mögliche spätere Verwendung archiviert werden.
Bereitstellungs- und Verarbeitungskosten
Unternehmen können sowohl die Hadoop- als auch die Spark-Frameworks der kostenlosen Open-Source-Versionen einsetzen. Alternativ bieten sich kommerzielle Cloud-Dienste und On-Premises-Angebote an. Die anfänglichen Bereitstellungskosten sind jedoch nur eine Komponente der Gesamtkosten für den Betrieb der Big-Data-Plattformen. IT- und Datenverwaltungsteams müssen auch die Ressourcen und das Fachwissen mit einbeziehen, die für die sichere Bereitstellung, Wartung und Aktualisierung der zugrunde liegenden Infrastruktur und Big-Data-Architektur erforderlich sind.
Ein Unterschied zwischen beiden Systemen besteht darin, dass eine Spark-Implementierung in der Regel mehr Speicher benötigt, was die Kosten für den Aufbau eines Clusters erhöhen kann. Hadoop kann eine kostengünstigere Plattform für die Ausführung gelegentlicher Berichte auf Standard-Hardware sein und die Kosten niedrig halten, wenn Unternehmen große Datenmengen für zukünftige Analyseprojekte aufbewahren möchten.
Das breite Hadoop-Ökosystem umfasst eine Vielzahl von optionalen, unterstützenden Technologien, die installiert, konfiguriert und gewartet werden müssen. Darunter befinden sich weit verbreitete Tools wie die HBase-Datenbank und die Data-Warehouse-Software Hive. Viele von ihnen können auch mit Spark verwendet werden. Kommerzielle Versionen der Frameworks bündeln diese Komponenten zu Sets, was die Bereitstellung vereinfacht und die Gesamtkosten niedrig hält.
Wie man sich zwischen Hadoop und Spark entscheidet
Hadoop ist nicht nur für einige Anwendungen kostengünstiger als Spark. Es verfügt auch über bessere langfristige Funktionen für die Datenverwaltung. Das macht Hadoop zur logischeren Wahl für das Sammeln, Verarbeiten und Speichern großer Datensätze, auch solcher, die möglicherweise nicht für aktuelle Analysen benötigt werden. Spark eignet sich besser zur Unterstützung von Analyseanwendungen, die im interaktiven Modus laufen und bei denen mehrere Operationen gleichzeitig oder verkettet ausgeführt werden müssen.
Aber wie bereits erwähnt, schließen sich Hadoop und Spark nicht gegenseitig aus. Die meisten Unternehmen, die Hadoop für Data-Engineering-, Datenaufbereitungs- und Analyseanwendungen einsetzen, verwenden auch Spark als Teil dieser Workflows, ohne dass es zu Problemen kommt. Darüber hinaus werden beide Frameworks häufig mit anderen Open-Source-Komponenten kombiniert, um verschiedene Aufgaben zu lösen.
Während ursprünglich mehr als ein halbes Dutzend Anbieter kommerzielle Hadoop-Distributionen entwickelt haben, hat sich der Markt konsolidiert. Cloudera ist nach wie vor ein unabhängiger Hadoop-Anbieter. Das Unternehmen hat 2019 Hortonworks, einen konkurrierenden Hadoop-Pionier, übernommen und bietet nun die Cloudera Data Platform an. Darüber hinaus haben die Cloud-Marktführer AWS, Microsoft und Google alle Big-Data-Plattformen im Angebot. Auf Basis von Hadoop, Spark und anderen Big-Data-Technologien bieten sie auch Services an: Amazon EMR, Azure HDInsight beziehungsweise Google Cloud Dataproc.
Ein Zeichen für die abnehmende Fokussierung auf MapReduce ist jedoch, dass AWS und Google in ihren Marketingmaterialien Hadoop nicht mehr so stark betonen. Stattdessen heben sie Spark und einige der anderen Technologien aus dem Hadoop-Ökosystem hervor. Databricks, ein Anbieter, der vom Spark-Erfinder Matei Zaharia und anderen gegründet wurde, bietet ebenfalls eine Cloud-Plattform für Datenverarbeitung und Analyse an. Diese baut auf Spark auf und ist jetzt als Databricks Lakehouse Platform bekannt.





