
archy13 - stock.adobe.com
Groq LPU Inference Engine stellt NVIDIA-GPUs in den Schatten
Groq hat einen Prozessor entwickelt, der die Leistung von Grafikprozessoren bei großen Sprachmodellen übertreffen soll. Das Unternehmen nennt diesen Language Processing Unit (LPU).

Groq hat einen Prozessor für maschinelles Lernen entwickelt, der nach eigenen Angaben die Verarbeitungsleistung von Grafikprozessoren (GPU) bei LLM-Workloads (Large Language Model) abhängt: er soll zehnmal schneller als ein Nvidia-Grafikprozessor (GPU) sein bei zehn Prozent der Kosten und einem Zehntel des Stromverbrauchs.
Jonathan Ross, Gründer und CEO von Groq, ist ein ehemaliger Google-Ingenieur, der das Entwicklungsteam für die Tensor Processing Unit (TPU) beim Suchmaschinenanbieter leitete. „Dieser Chip war gut für KI-Trainings, aber weniger geeignet für KI-Inferenz-Workloads“, sagt er.
Daher gründete er Groq im Jahr 2016. Sein Ziel: einen Compiler für Deep-Learning-Inferenzaufgaben und einen Chip entwickeln, auf dem die kompilierten Modelle ausgeführt werden können.
„CPUs sind nicht leistungsfähig genug, um diese Aufgabe auch nur annähernd in Echtzeit zu erledigen. GPUs sind wiederum auf das Training von Machine-Learning-Modellen und nicht auf die Ausführung alltäglicher Inferenzaufgaben ausgerichtet“, erläutert Ross. „Ein Grafikprozessor mit seiner großen Anzahl paralleler Kerne kann Datenfluss- oder Datenstromprozesse nicht gut ausführen.“
Ross und sein Entwicklerteam bei Groq haben daher eine LPU Inference Engine – LPU steht für Language Processing Unit – entwickelt, die dies besser als GPUs oder CPUs könne soll. Die LPU Inference Engine wurde entwickelt, um Machine-Learning-Modelle effizient auf Geräten mit begrenzten Rechenressourcen auszuführen, wie zum Beispiel Smartphones, Smart-Home-Geräten und IoT-Geräten.
Die Engine unterstützt Deep-Learning-Frameworks wie TensorFlow, PyTorch und Caffe und kann auf verschiedenen Betriebssystemen, einschließlich Linux, Android und iOS, ausgeführt werden.
Architektur der LPU Inference Engine
Im Gegensatz zu Grafikprozessoren hat die LPU einen einzigen Kern und eine TISC-Architektur (Temporal Instruction Set Computer). „Wir verwenden kein High Bandwidth Memory. Wir müssen die Prozesse nicht aus dem Speicher nachladen, wie es bei GPUs mit HBM der Fall ist."
LPUs benötigen somit keine schnelle Datenübertragung vom Speicher über Protokolle wie Nvidias GPUDirect, da es in einem Groq-System kein HBM gibt. Die LPU verwendet SRAM „Wir haben eine etwa 20-mal schnellere Bandbreite zu unserem Speicher als GPUs zu HBM. Außerdem sind die Datenmengen, die in einem Inferenzlauf verwendet werden, klein in Vergleich zu den riesigen Datensätzen in einem Modell-Trainingslauf“, erklärt der Groq-Gründer.
Aus diesem Grund sei die LPU viel energieeffizienter. „Wir müssen weniger aus dem externen Speicher lesen. Die LPU verbraucht weniger elektrische Energie als eine Nvidia-GPU, um eine Inferenzaufgabe auszuführen“, sagt er.
Die Leistung wird als Latenzzeit und Durchsatz gemessen, das heißt als Token pro Sekunde (Token per Second, TPS). Ein Token ist die Textdatenverarbeitungseinheit in einem Large Language Model (LLM). Die LPU von Groq hat einen höheren TPS-Wert als ein Nvidia-Grafikprozessor, braucht also weniger Zeit, um eine Anfrage abzuschließen, und antwortet auch schneller, da sie eine geringere Latenzzeit hat. Laut Ross reagiert die LPU verlässlich schnell und macht damit Echtzeitgespräche zuverlässig möglich.
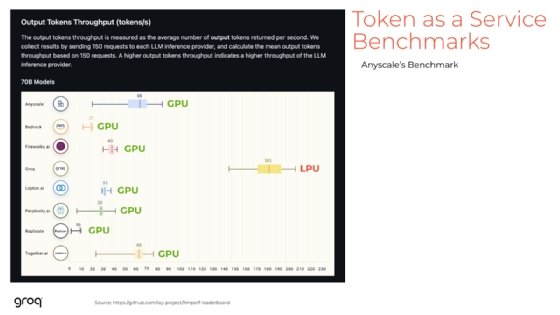
Mehr als 80 LLMs sind für Groq bereits kompiliert wurden. Die Modellkompilierung ist schnell, da mehrere LPU-Chips für die Aufgabe eingesetzt werden, und sie dauert nur wenige Stunden. Die Zeit, die benötigt wird, um Zugriff auf das Modell zu erhalten, es zu kompilieren und es auf Groq zum Laufen zu bringen, beträgt vier bis fünf Tage.
Zusammenfassung
Die LPU Inference Engine weist laut Groq mehrere Merkmale auf:
- Niedrige Latenz: Die Engine ist für Echtzeit-Inferenz optimiert und bietet eine schnelle und reaktionsschnelle Leistung für Anwendungen, die eine geringe Latenz benötigen.
- Geringer Stromverbrauch: Die Engine ist so konzipiert, dass sie stromsparend ist und sich daher für batteriebetriebene Geräte eignet.
- Kompakte Größe: Die kompakte Größe der Engine ermöglicht die Ausführung auf Geräten mit begrenztem Speicher und begrenzter Speicherkapazität.
- Flexible Hardware-Unterstützung: Die Engine kann auf verschiedenen Hardware-Plattformen laufen, darunter CPUs, GPUs und spezielle KI-Chips.
- Einfache Integration: Die Engine bietet eine einfache API für die Integration mit einer Vielzahl von Software-Frameworks und Plattformen.
Groq stellte seine Lösungen im Rahmen der IT Press Tour (in San Francisco und der Bay Area) vor, die mehrmals im Jahr Besuche bei Start-ups und IT-Unternehmen organisiert.







