
Algorithmische Vorurteile in KI-Systemen verhindern
Da Firmen Modelle wie GPT-4 integrieren, erfordert die Gewährleistung eines gerechten Zugangs zu Ressourcen aller Art einen offenen Diskurs über algorithmische Vorurteile in der KI.

Voreingenommenheit oder Vorurteile (in Englisch: Bias) wird oft als ein menschliches Problem angesehen: das Produkt unvollkommener Gehirne und nicht vermeintlich unparteiischer KI-Systeme. Aber KI-Modelle spiegeln nicht nur menschliche Voreingenommenheit wider, sondern können diese auch massiv verstärken, und zwar auf eine Weise, die schwer zu erkennen und zu verhindern ist.
Laut einem IBM-Bericht aus dem Jahr 2022 nutzte bereits vor der Einführung von ChatGPT mehr als ein Drittel der Unternehmen künstliche Intelligenz (KI) und weitere 42 Prozent zogen dies in Erwägung. In der gleichen Umfrage gaben jedoch fast drei Viertel der Befragten an, dass sie keine Schritte unternommen haben, um unbeabsichtigte Verzerrungen oder Vorurteile in ihren Modellen zu reduzieren. Diese zunehmende Akzeptanz in Verbindung mit der mangelnden Aufmerksamkeit für algorithmische Vorurteile in der KI bereitet den Experten Sorgen.
„Im Moment haben wir Systeme, die auf der Grundlage von KI marginalisierte Menschen in den USA und in anderen Teilen der Welt massiv diskriminieren, und ich denke, dass wir das nicht wirklich angehen“, meint Jesse McCrosky, Principal Data Scientist und Leiter der Abteilung Nachhaltigkeit und sozialer Wandel bei Thoughtworks und Mitverfasser eines aktuellen Berichts der Mozilla Foundation über KI-Transparenz.
Da Regierungen und Unternehmen zunehmend KI einsetzen, um wichtige Entscheidungen zu treffen, ist eine verantwortungsvolle Entwicklung von KI ebenfalls von entscheidender Bedeutung. Algorithmische Voreingenommenheit zu verhindern bedeutet, Fairness und Diskriminierung während der gesamten Modellentwicklung zu berücksichtigen und dies auch nach dem Einsatz fortzusetzen.
Was sind die Ursachen für algorithmische Vorurteile in der KI?
Voreingenommenheit oder Vorurteile in KI-Systemen beginnt auf der Ebene der Daten. „Um bessere Systeme zu entwickeln, müssen wir uns auf die Datenqualität konzentrieren und diese zuerst verbessern, bevor wir Modelle in die Produktion schicken“, erklärt Miriam Seoane Santos, Entwicklerin bei YData und Forscherin für maschinelles Lernen(ML).
Die Leistung eines KI-Systems hängt stark von den zugrundeliegenden Daten ab, die für das Training des Modells verwendet werden, was bedeutet, dass das endgültige Modell Verzerrungen in den Daten und der Art und Weise, wie sie gesammelt wurden, widerspiegelt. Ein Modell, das auf einem Datensatz mit unzureichenden Daten über Minderheitengruppen trainiert wurde, wird für diese Gruppen schlechtere Ergebnisse liefern.
„Ein Bereich, der in der verantwortungsvollen KI zunehmend untersucht wird, ist die Datenkuration selbst: Es muss sichergestellt werden, dass die Daten für alle Gruppen repräsentativ sind und dass sie auf ethische Weise gesammelt werden“, betont Perry Abdulkadir, ein Berater für algorithmische Fairness und Datenwissenschaft bei SolasAI.
Santos verwies auf eine Arbeit der Forscher Joy Buolamwini und Timnit Gebru aus dem Jahr 2018, die herausfanden, dass Gesichtserkennungssysteme hellhäutige männliche Gesichter viel genauer identifizieren als dunkelhäutige weibliche Gesichter. Der Einsatz eines solchen Modells beispielsweise in einem selbstfahrenden Auto könnte katastrophale Folgen haben, so Santos: Würde die Software einen Fußgänger auf einem Zebrastreifen nicht erkennen, wäre das Leben dieser Person unmittelbar gefährdet.
Diese Ergebnisse unterstreichen, wie wichtig die menschliche Aufsicht durch verschiedene Teams während der gesamten Modellentwicklung ist. „Es geht nicht nur darum, dass die Daten selbst in irgendeiner Weise verfälscht sind“, sagt Santos. „Es hat auch mit den menschlichen Aspekten zu tun. Wir sind diejenigen, die die Daten sammeln. Wir sind diejenigen, die darüber entscheiden, was in die Entwicklung des Systems einfließt und was nicht.“
Den Umgang mit sensiblen Daten verstehen
Probleme ergeben sich auch im Zusammenhang mit Daten, die zur Verwendung in KI-Systemen gesammelt werden und Merkmale wie Ethnie, Alter und Geschlecht offenbaren.
Einige Teams, die sich Sorgen über algorithmische Vorurteile machen, könnten sich dafür entscheiden, diese Attribute zu entfernen oder zu verschleiern, in der Hoffnung, ihren Einfluss auf Modellentscheidungen zu minimieren. Aber solche Informationen einfach auszublenden oder zu ignorieren ist nicht unbedingt möglich oder wünschenswert.
In bestimmten Kontexten sind diese Daten notwendig, um ein genaues und ethisches Modell zu erstellen. Santos, der einen Hintergrund in biomedizinischer Technik hat, nannte als Beispiel ein Modell zur Vorhersage von Brustkrebs, für das Faktoren wie das Alter und die Krankengeschichte einer Person von großer Bedeutung sein können.
Wenn der Datensatz Kategorien wie zum Beispiel jüngere Frauen nicht angemessen repräsentiert, wird die Genauigkeit der Gesundheitsversorgung in Richtung einer der Untergruppen verzerrt sein. Das kann echte Konsequenzen für Menschen haben, die eine faire Behandlung oder eine personalisierte Behandlung wünschen.
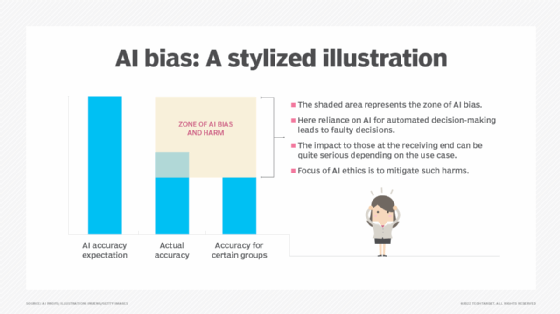
Die Rolle von Proxies bei algorithmischen Vorurteilen
In anderen Fällen können scheinbar harmlose Merkmale die Diskriminierung aufrechterhalten, indem sie als Stellvertreter für Merkmale wie Ethnie und Geschlecht dienen. „In diesen KI- und ML-Modellen treten Ungleichheiten oft auf kontraintuitive Weise auf“, so Abdulkadir. „Es kann Merkmale geben, von denen man denkt, dass sie extrem problematisch sind, von denen sich aber herausstellt, dass sie nicht unbedingt zu Ungleichheiten führen, und umgekehrt.“
So kann beispielsweise die Erfassung von Informationen wie Adresse oder Postleitzahl für bestimmte Anwendungsfälle durchaus legitim sein. Aber diese Informationen können auch indirekt die Ethnie oder Gruppe einer Person aufgrund historischer Muster offenbaren, wie zum Beispiel der Diskriminierung aufgrund des Wohngebiets.
„In unseren Modellen gibt es keine Möglichkeit, diese Art von Postleitzahlinformationen zuzulassen, da sie ein eindeutiger Indikator für Bevölkerungsschicht und Einkommen sind", sagt Scott Zoldi, Chief Analytics Officer bei FICO. „Wir müssen einfach sagen: Ja, man könnte vielleicht ein besseres Modell erhalten, aber es würde die gleichen Verzerrungen verbreiten, die wir heute in der Gesellschaft haben.“
Einige Proxies sind vielleicht nicht so leicht zu erkennen. Abdulkadir nennt das Beispiel des Einkaufsverhaltens in Lebensmittelgeschäften, das manchmal in Kreditmodellen als Risikoindikator verwendet wird: Eine Person, die viel Geld in großen Supermärkten ausgibt, kauft möglicherweise häufig Artikel wie Alkohol und Lotterielose, was auf eine geringere Kreditwürdigkeit hindeuten könnte, so die Überlegung.
„Abgesehen davon, wie schwach dieser Zusammenhang sein mag“, so Abdulkadir, „bricht diese Art von Logik sehr schnell zusammen, wenn man sich die soziologische Geschichte ansieht, warum Menschen große Supermärkte besuchen.“
In Wirklichkeit haben Verbraucher, die in Gegenden mit wenig Infrastruktur leben, keine andere Wahl, als Lebensmittel und andere lebenswichtige Dinge in Großmärkten zu kaufen. Würden die Bewerber für ihre Ausgaben in diesen Geschäften bestraft, würde dies zu einer weiteren finanziellen Benachteiligung marginalisierter Personen führen.
Schritte zur Vermeidung algorithmischer Vorurteile in der KI
Mit der zunehmenden Verbreitung von KI müssen Entwickler und Unternehmen von Anfang an verantwortungsvolle KI-Praktiken einführen, so die Experten.
Eine menschliche Bestandsaufnahme der Daten und potenzieller Probleme, die auftreten könnten, ist ein wichtiger erster Schritt zur Erstellung eines fairen Modells. Nach dieser ersten Überprüfung können die Entwicklungsteams potenziell problematische Merkmale eingehender untersuchen und dabei auch feststellen, ob sie als Proxies für geschützte Merkmale fungieren.
Santos betonte, wie wichtig es ist, verschiedene Teams in diesen Prozess einzubeziehen und Überlegungen zu algorithmischen Verzerrungen als Standardbestandteil der Modellbewertung zu behandeln. „Achten Sie auf Probleme wie unausgewogene Daten, den Schutz von Untergruppen und die Suche nach den besten Fairness-Metriken, um Ihrem System Feedback zu geben“, betont sie. „Anstatt sich nur auf die Leistung zu konzentrieren, sollten Sie verschiedene Metriken ausprobieren.“
Neben der Berücksichtigung dieser Faktoren bei der Entwicklung und Analyse von Modellen besteht ein wesentlicher Teil der Verbesserung der algorithmischen Fairness in der Verbesserung von Transparenz, Interpretierbarkeit und Verantwortlichkeit, sobald ein Modell eingesetzt wird. „Nachdem das Modell in Produktion ist, muss man garantieren, dass das System irgendwie überprüft werden kann, damit es sich anpasst“, sagt Santos. „Das ist keine einmalige Sache, sondern es kann ein Feedback erhalten, wenn seine Vorhersagen nicht stimmen oder in irgendeiner Weise fehlerhaft sind.“
KI-Modelle erstellen Vorhersagen auf komplizierte Weise, indem sie komplexe Interaktionen zwischen Hunderten oder Tausenden von Merkmalen nutzen. Warum ein Modell eine bestimmte Vorhersage getroffen hat, kann daher selbst für die Entwickler des Modells schwer zu verstehen sein, ein Phänomen, das als Blackbox-Problem bekannt ist - und dieses Phänomen wird noch verschärft, wenn Unternehmen aufgrund des Wettbewerbsdrucks Transparenz vermeiden.
„Unsere Regierungen, unsere Regulierungsbehörden, unsere Zivilgesellschaft, unsere Forscher und Journalisten müssen in der Lage sein, sinnvolle Gespräche darüber zu führen, welche Art von Gesellschaft wir aufbauen, wenn wir diese Technologien freigeben“, sagt McCrosky. „Ich glaube aber, dass es sehr schwierig ist, diese Gespräche zu führen, wenn ein Großteil der Arbeit in einer Blackbox oder hinter verschlossenen Türen stattfindet... Ich denke, es gibt wirklich ein moralisches Gebot für mehr Transparenz.“
Um dies zu ändern, sind offenere Ansätze für die Modellentwicklung und -analyse erforderlich. Zoldi ist optimistisch, was die Blockchain als Möglichkeit zur unveränderlichen Aufzeichnung des Modellentwicklungsprozesses angeht. Er erwägt, Teile des Blockchain-basierten Modellentwicklungsstandards, der bei FICO verwendet wird, als Open-Sourcing-Lösung anzubieten, um die Überprüfbarkeit zu fördern.
„Die Blockchain speichert alle Erkenntnisse und das Wissen darüber, welche Variablen in der Vergangenheit akzeptiert wurden, welche problematisch sind und welche nicht erlaubt sind“, so Zoldi. „Denn wir wollen nicht, dass Menschen Dinge neu erfinden, die wir bereits verboten oder als nicht akzeptabel eingestuft haben.“
Zur Verbesserung der Transparenz und Interpretierbarkeit sollte auch Raum für Feedback geschaffen werden. Oftmals haben die von den Entscheidungen der KI-Modelle betroffenen Personen keine Möglichkeit, diese Ergebnisse zu verstehen oder dagegen vorzugehen, obwohl die Folgen so gravierend sein können.
„Für sie bedeutet es, dass sie einen Kredit bekommen oder nicht, dass sie einen Job bekommen oder nicht, oder dass sie Zugang zu einer bestimmten neuen Behandlung erhalten“, erläutert Santos. In solchen Fällen muss man in der Lage sein, sich die Ergebnisse geben zu lassen und eine grundlegende Erklärung zu erhalten, warum dies passierte. Der Anwender erhält dann einige grundlegende Informationen darüber, welche Daten über ihn gesammelt werden, die zu den Ergebnissen geführt haben.
Die sich entwickelnde Landschaft der verantwortungsvollen KI
Die Diskussion über algorithmische Verzerrungen in der KI ist nicht neu. Forscher wie Gebru und Buolamwini, neben vielen anderen, haben seit Jahren ethische Fragen zur KI aufgeworfen.
Doch in der Vergangenheit wurde das Äußern solcher Bedenken nicht immer positiv aufgenommen. Im Jahr 2020 kündigte Google Gebru nach einem Streit über eine Forschungsarbeit, die sie im Hinblick auf die Besorgnis über algorithmische Verzerrungen in großen Sprachmodellen wie GPT-3 geschrieben hatte.
In jüngster Zeit haben große Technologieunternehmen wie Microsoft, Meta und Twitter Mitarbeiter im Bereich KI-Ethik entlassen, da das Interesse am Einsatz von KI und ML stark gestiegen ist. „Microsoft will nicht hören, dass ihre Investition in OpenAI möglicherweise nicht richtig ist“, sagte Zoldi, „aber die Firma muss hier zuhören.“
Ungeachtet dessen bedeuten die zunehmende Verbreitung von KI-Systemen und die sich abzeichnenden KI-Vorschriften, dass es für Unternehmen schwieriger werden könnte, das Gespräch zu vermeiden. „Die Technologie ist an einem Punkt angelangt, an dem sie tatsächlich dazu zwingt, diese Gespräche ernster zu nehmen und schneller zu führen“, betont McCrosky, auch wenn er anmerkt, dass sich die Dinge oft zu schnell entwickeln, als dass die Regulierungsprozesse heutzutage rechtzeitig Schritt halten könnten.
Vor allem in stark regulierten Branchen wie dem Bankwesen und dem Gesundheitswesen wird das Interesse der Unternehmen an einer verantwortungsvollen KI häufig von den gesetzlichen Vorschriften und der Gewinnsituation bestimmt. Experten sind jedoch auch hoffnungsvoll, was das Aufkommen von aufrichtigeren ethischen Verpflichtungen angeht.
Abdulkadir räumt zwar ein, dass die Einhaltung von Vorschriften und das Reputationsrisiko bei Geschäftsentscheidungen eine wichtige Rolle spielen, sagt aber, dass er auch auf individueller Ebene ein aufrichtigeres Interesse an der KI-Ethik beobachtet, einschließlich der Bereitschaft, über die gesetzlichen Anforderungen hinauszugehen. Zoldi beschrieb einen ähnlichen Wandel im Laufe seiner Zeit als Mitglied des Beirats der gemeinnützigen Organisation FinRegLab.







