Verteiltes Rechnen (Distributed Computing)

Verteiltes Rechnen (in Englisch Distributed Computing) ist ein Modell, bei dem die Komponenten eines Softwaresystems auf mehrere Computer oder Knoten verteilt sind. Auch wenn die Softwarekomponenten auf mehrere Computer an verschiedenen Standorten verteilt sind, werden sie als ein System ausgeführt.
Dies geschieht, um die Effizienz und Leistung zu verbessern. Die Systeme auf verschiedenen vernetzten Computern kommunizieren und koordinieren sich, indem sie Nachrichten hin- und herschicken, um eine bestimmte Aufgabe zu erfüllen.
Verteiltes Rechnen kann die Leistung, Ausfallsicherheit und Skalierbarkeit erhöhen und ist daher ein gängiges Computermodell für die Entwicklung von Datenbanken und Anwendungen.
Wie verteiltes Rechnen funktioniert
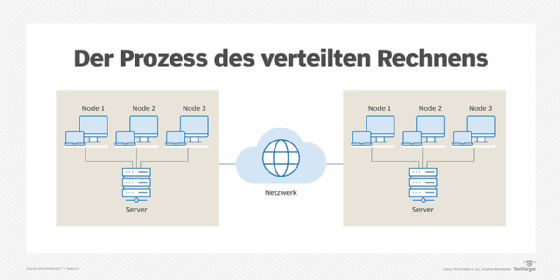
Verteilte Rechnernetze können als lokale Netze oder über ein Wide Area Network verbunden sein, wenn sich die Rechner an verschiedenen geografischen Standorten befinden. Die Prozessoren in verteilten Rechnersystemen arbeiten in der Regel parallel.
In Unternehmen werden bei der verteilten Datenverarbeitung im Allgemeinen verschiedene Schritte in Geschäftsprozessen an den effizientesten Stellen in einem Computernetz ausgeführt. Ein typischer verteilter Computer verfügt beispielsweise über ein dreistufiges Modell, das die Anwendungen in die Präsentationsschicht (oder Benutzeroberfläche), die Anwendungsschicht und die Datenschicht unterteilt. Diese Schichten funktionieren wie folgt:
- Die Verarbeitung der Benutzeroberfläche erfolgt auf dem PC am Standort des Benutzers.
- Die Anwendungsverarbeitung findet auf einem entfernten Computer statt.
- Der Datenbankzugriff und die Verarbeitungsalgorithmen finden auf einem anderen Computer statt, der einen zentralen Zugang für viele Geschäftsprozesse bietet.
Neben dem Drei-Schichten-Modell gibt es noch andere Arten der verteilten Datenverarbeitung, wie Client-Server, n-Tier und Peer-to-Peer:
- Client-Server-Architekturen. Diese verwenden intelligente Clients, die Daten von einem Server anfordern und diese Daten dann formatieren und dem Benutzer anzeigen.
- N-Tier-Systemarchitekturen. Diese Architekturen werden in der Regel in Anwendungsservern eingesetzt und verwenden Webanwendungen, um Anfragen an andere Unternehmensdienste weiterzuleiten.
- Peer-to-Peer-Architekturen. Diese teilen alle Verantwortlichkeiten auf alle Peer-Computer auf, die als Clients oder Server dienen können.
Vorteile des verteilten Rechnens
Verteiltes Rechnen bietet folgende Vorteile:
- Durch verteiltes Rechnen kann die Leistung verbessert werden, indem jeder Computer in einem Clusterverschiedene Teile einer Aufgabe gleichzeitig bearbeitet.
- Cluster für verteiltes Rechnen sind skalierbar, indem bei Bedarf neue Hardware hinzugefügt wird.
- Ausfallsicherheit und Redundanz. Mehrere Computer können dieselben Dienste bereitstellen. Wenn ein Rechner nicht verfügbar ist, können andere für den Dienst einspringen. Ebenso kann ein Unternehmen weiterarbeiten, wenn sich zwei Rechner, die denselben Dienst erbringen, in verschiedenen Rechenzentren befinden und ein Rechenzentrum ausfällt.
- Beim verteilten Rechnen kann kostengünstige Standardhardware verwendet werden.
- Komplexe Anfragen können in kleinere Teile zerlegt und auf verschiedene Systeme verteilt werden. Auf diese Weise wird die Anfrage vereinfacht und als eine Art paralleles Rechnen bearbeitet, wodurch sich die für die Berechnung der Anfrage benötigte Zeit verringert.
- Verteilte Anwendungen. Im Gegensatz zu herkömmlichen Anwendungen, die auf einem einzigen System laufen, werden verteilte Anwendungen auf mehreren Systemen gleichzeitig ausgeführt.
Grid Computing, Cloud-Computing und verteiltes Rechnen
Grid Computing ist ein Computermodell mit einer verteilten Architektur aus mehreren Computern, die zur Lösung eines komplexen Problems verbunden sind. Im Grid-Computing-Modell führen Server oder PCs unabhängige Aufgaben aus und sind lose über das Internet oder langsame Netze miteinander verbunden. Einzelne Teilnehmer können einen Teil der Rechenzeit ihres Computers für die Lösung komplexer Probleme nutzen.
SETI@home ist ein Beispiel für ein Grid-Computing-Projekt. Obwohl die erste Phase des Projekts im März 2020 endete, stellten einzelne Computerbesitzer mehr als 20 Jahre lang freiwillig einen Teil ihrer Multitasking-Rechenzeit für das Projekt zur Suche nach außerirdischer Intelligenz (SETI) zur Verfügung, während sie gleichzeitig ihre Computer weiter nutzten. Bei diesem rechenintensiven Problem wurden Tausende von PCs zum Herunterladen und Durchsuchen von Radioteleskopdaten eingesetzt.
Grid Computing und verteiltes Rechnen sind ähnliche Konzepte, die manchmal schwer zu unterscheiden sind. Im Allgemeinen ist die Definition des verteilten Rechnens weiter gefasst als die des Grid Computing. Beim Grid Computing handelt es sich in der Regel um eine große Gruppe verteilter Computer, die gemeinsam eine bestimmte Aufgabe erfüllen. Im Gegensatz dazu kann verteiltes Rechnen an zahlreichen Aufgaben gleichzeitig arbeiten. Manche definieren Grid Computing auch nur als eine Art des verteilten Computings. Während das Grid Computing in der Regel aus genau definierten architektonischen Komponenten besteht, kann das verteilte Computing verschiedene Architekturen aufweisen, wie zum Beispiel Grid, Cluster und Cloud Computing.
Das Konzept des Cloud Computing ähnelt ebenfalls dem des verteilten Computings. Cloud Computing ist ein allgemeiner Begriff für alles, was die Bereitstellung von gehosteten Diensten über das Internet umfasst. Diese Dienste werden jedoch in drei Haupttypen unterteilt: Infrastructure as a Service (IaaS), Platform as a Service (PaaS) und Software as a Service(SaaS). Cloud Computing wird auch in private und öffentliche Clouds unterteilt. Eine öffentliche Cloud verkauft Dienste an Dritte, während eine private Cloudmputing&enablejsapi=1&origin=https://www.techtarget.com" type="text/html" height="360" width="640" frameborder="0">







