Unstrukturierte Daten
Was sind unstrukturierte Daten?
Unstrukturierte Daten sind Informationen in vielen verschiedenen Formen, die nicht den herkömmlichen Datenmodellen entsprechen und daher in einer gängigen relationalen Datenbank nur schwer zu speichern und zu verwalten sind.
Der Großteil der heute generierten neuen Daten ist unstrukturiert, was zur Entwicklung neuer Plattformen und Tools für die Verwaltung und Analyse dieser Daten geführt hat. Mit diesen Tools können Unternehmen unstrukturierte Daten einfacher für Business Intelligence (BI) und Analyseanwendungen nutzen.
Unstrukturierte Daten haben eine interne Struktur, enthalten jedoch kein vordefiniertes Datenmodell oder Schema. Sie können textuell oder nicht-textuell, von Menschen oder von Maschinen generiert sein.
Text ist einer der häufigsten Typen unstrukturierter Daten. Unstrukturierter Text wird in verschiedenen Formen generiert und gesammelt, darunter Word-Dokumente, E-Mail-Nachrichten, PowerPoint-Präsentationen, Umfrageantworten, Transkripte von Callcenter-Interaktionen und Beiträge aus Blogs und sozialen Medien.
Andere Arten unstrukturierter Daten sind Bilder, Audio- und Videodateien. Maschinendaten sind eine weitere Kategorie unstrukturierter Daten, die in vielen Unternehmen schnell an Bedeutung gewinnt. Beispielsweise liefern Logdateien von Websites, Servern, Netzwerken und Anwendungen – insbesondere mobilen Anwendungen – eine Fülle von Aktivitäts- und Leistungsdaten. Darüber hinaus erfassen und analysieren Unternehmen zunehmend Daten von Sensoren an Fertigungsanlagen und anderen Geräten, die mit dem Internet der Dinge (Internet of Things, IoT) verbunden sind.

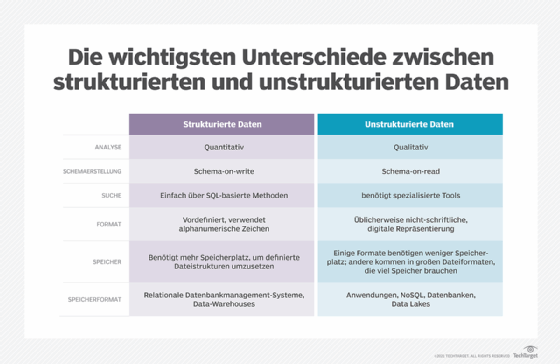
Strukturierte versus unstrukturierte Daten
Die Hauptunterschiede zwischen strukturierten und unstrukturierten Daten liegen in den Arten der Analyse, für die die Daten verwendet werden können, dem verwendeten Schema, den Datenformaten und der Art und Weise, wie die Daten gespeichert werden. Herkömmliche strukturierte Daten, wie Transaktionsdaten in Finanzsystemen und anderen Geschäftsanwendungen, entsprechen einem starren Format, um eine konsistente Verarbeitung und Analyse zu gewährleisten. Unstrukturierte Datensätze hingegen werden in uneinheitlichen Formaten gespeichert.
Strukturierte Daten werden in einer relationalen Datenbank gespeichert, die über Spalten und Tabellen Zugriff auf miteinander verknüpfte Datenpunkte bietet. Beispielsweise gelten Kundeninformationen, die in einer Tabelle gespeichert und nach Telefonnummern, Adressen oder anderen Kriterien kategorisiert sind, als strukturierte Daten. Weitere Beispiele für strukturierte Datensysteme sind Reisebuchungssysteme, Bestandsregister und Buchhaltungsüberweisungen.
Da diese Informationen kategorisiert sind, gelten sie sowohl für Menschen als auch für Algorithmen in der Datenanalyse als besser durchsuchbar. Datenbankadministratoren verwenden häufig die strukturierte Abfragesprache SQL (Structured Query Language), die eine effektive Suche nach strukturierten Daten in relationalen Datenbanken ermöglicht.
Strukturierte und unstrukturierte Daten werden häufig zusammen verwendet. Beispielsweise könnte eine strukturierte Tabelle mit Kundendaten in ein unstrukturiertes CRM-System (Customer Relationship Management) importiert werden.
Wofür werden unstrukturierte Daten verwendet?
Aufgrund ihrer Beschaffenheit eignen sich unstrukturierte Daten nicht für Transaktionsverarbeitungsanwendungen, die häufig strukturierte Daten verarbeiten. Stattdessen werden sie in erster Linie für BI und Analysen verwendet.
Kundenanalysen sind eine beliebte Anwendung für unstrukturierte Daten. Einzelhändler, Hersteller und andere Unternehmen analysieren unstrukturierte Daten, um das Kundenerlebnis zu verbessern und gezieltes Marketing zu ermöglichen. Sie führen auch Stimmungsanalysen durch, um Kunden besser zu verstehen und Einstellungen zu Produkten, Kundenservice und Unternehmensmarken zu identifizieren.
Vorausschauende Wartung (Predictive Maintenance) ist ein aufstrebender Anwendungsfall für die Analyse unstrukturierter Daten. Beispielsweise können Hersteller Sensordaten analysieren, um Geräteausfälle zu erkennen, bevor sie in Fertigungsanlagen oder bei fertigen Produkten auftreten. Energiepipelines werden mithilfe unstrukturierter Daten, die von IoT-Sensoren erfasst werden, überwacht und auf potenzielle Probleme überprüft.
Die Analyse von Protokolldaten aus IT-Systemen zeigt Nutzungstrends auf, identifiziert Kapazitätsengpässe und lokalisiert die Ursachen von Anwendungsfehlern, Systemabstürzen, Leistungsengpässen und anderen Problemen. Die Analyse unstrukturierter Daten unterstützt auch die Einhaltung gesetzlicher Vorschriften, insbesondere indem sie Unternehmen dabei hilft, den Inhalt ihrer Dokumente und Aufzeichnungen zu verstehen.
Techniken und Plattformen für unstrukturierte Daten
In der Vergangenheit waren unstrukturierte Daten oft in isolierten Dokumentenmanagementsystemen, einzelnen Fertigungsgeräten und ähnlichen Systemen gespeichert. Durch diesen Ansatz wurden unstrukturierte Daten zu sogenannten Dark Data, die für Analysen nicht verfügbar waren.
Mit der Entwicklung von Big-Data-Plattformen, vor allem Hadoop-Clustern, NoSQL-Datenbanken und dem Amazon Simple Storage Service (S3), hat sich dies jedoch geändert. Sie bieten die erforderliche Infrastruktur für die Verarbeitung, Speicherung und Verwaltung großer Mengen unstrukturierter Daten, ohne dass ein gemeinsames Datenmodell und ein einziges Datenbankschema erforderlich sind.
Herausforderungen mit unstrukturierten Daten
Unstrukturierte Daten bringen mehrere Herausforderungen mit sich. Zu den häufigsten gehören die folgenden:
- Speicheranforderungen. Unstrukturierte Daten benötigen aufgrund ihrer unterschiedlichen Formate, wie Audio-, Video- und Multimediadateien, oft große Speicherkapazitäten.
- Komplexität der Datenverwaltung. Die Verwaltung unstrukturierter Daten über verschiedene Verzeichnisse und Dateisysteme hinweg kann ohne spezielle Tools eine Herausforderung darstellen.
- Schwierigkeit der Analyse. Die Gewinnung wertvoller Erkenntnisse aus unstrukturierten Daten erfordert fortschrittliche Technologien wie generative künstliche Intelligenz (KI) und Natural Language Processing (NLP).
- Integrationsprobleme. Die Integration unstrukturierter Daten in strukturierte Daten in Data Warehouses oder Data Lakes kann komplex und schwierig sein.
- Echtzeitverarbeitung. Die Verarbeitung unstrukturierter Daten in Echtzeit, wie zum Beispiel Live-Feeds aus sozialen Medien, erfordert eine entsprechende Infrastruktur und ausgefeilte Algorithmen.
Beispiele für unstrukturierte Daten
Es gibt verschiedene Arten von unstrukturierten Daten. Zu den häufigsten gehören:
- Audiodateien, wie Podcasts und Aufzeichnungen
- Social-Media-Beiträge, darunter Tweets, Instagram- und Facebook-Statusmeldungen
- Textdokumente und Textdateien, wie Berichte, Artikel und PDFs
- Bilder, Videos und andere Multimedia-Formate
- Webseiten mit dynamischen und vielfältigen Inhalten
- E-Mails und Korrespondenz
- Echtzeit-Datenströme, wie die Ausgaben von IoT-Geräten
- Chatbot-Konversationen und NLP-verarbeitete Texte
Wie man unstrukturierte Daten verwaltet
Es gibt mehrere Möglichkeiten, unstrukturierte Daten erfolgreich zu verwalten. Zu den wichtigsten Schritten gehören die folgenden:
- Data Lakes. Unstrukturierte Daten können zusammen mit strukturierten Datensätzen in einem Data Lake gespeichert werden, um die Zugänglichkeit zu verbessern.
- Fortschrittliche Tools. Technologien wie generative KI, NLP und andere datenwissenschaftliche Techniken werden zur Verarbeitung und Analyse unstrukturierter Daten eingesetzt.
- Cloud-Speicher. Cloud-Datenspeicher bieten Skalierbarkeit für unstrukturierte Daten.
- Metadaten. Gut definierte Metadaten erleichtern die Indizierung und Suche von unstrukturierten Daten.
- Automatisierte Prozesse. Automatisierungs-Tools optimieren die Datenerfassung, Kategorisierung und Analyse.
- Dateisysteme. Regelmäßig überprüfte und optimierte Dateisysteme sorgen für eine effiziente Speicherung unstrukturierter Daten.
Was sind semistrukturierte Daten?
Semistrukturierte Daten sind weitgehend unstrukturiert, verwenden jedoch interne Tags und Markierungen, die verschiedene Datenelemente trennen und unterscheiden und sie in Paare und Hierarchien einordnen. Semistrukturierte und unstrukturierte Daten werden oft miteinander verglichen, sind jedoch unterschiedlich.
E-Mails sind ein gängiges Beispiel für semistrukturierte Daten. Die in einer E-Mail verwendeten Metadaten ermöglichen es Analyse-Tools, Schlüsselwörter einfach zu klassifizieren und zu suchen. Sensordaten, Social-Media-Daten und Markup-Sprachen wie XML und NoSQL-Datenbanken sind Beispiele für unstrukturierte Daten, die im Hinblick auf eine bessere Durchsuchbarkeit weiterentwickelt werden und als semistrukturierte Daten betrachtet werden können.
Analyse-Tools der nächsten Generation für unstrukturierte Daten
Zur Analyse unstrukturierter Daten in Big-Data-Umgebungen werden verschiedene Analysetechniken und -Tools eingesetzt. Weitere Techniken, die bei der Analyse unstrukturierter Daten eine Rolle spielen, sind Data Mining, maschinelles Lernen und Predictive Analytics.
Textanalyse-Tools suchen in Textdaten nach Mustern, Schlüsselwörtern und Stimmungen. Auf einer fortgeschritteneren Ebene ist die NLP-Technologie eine Form der KI, die versucht, die Bedeutung und den Kontext von Texten und menschlicher Sprache zu verstehen, zunehmend mit Hilfe von Deep-Learning-Algorithmen, die neuronale Netze zur Analyse von Daten verwenden.
Neuere Tools aggregieren, analysieren und fragen alle Datentypen ab, um einen besseren Einblick in Unternehmensdaten und eine verbesserte Entscheidungsfindung zu ermöglichen. Beispiele hierfür sind Azure Data Services, IBM Cognos Analytics, Microsoft Power BI und Tableau.







